Download

1 / 11
110 likes | 122 Views
This document contains meeting notes from various dates discussing topics such as generic error counters, memory access, packet counters, multicast support, buffer offset, and more.

E N D
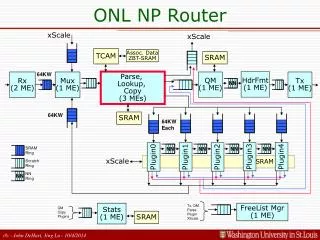
An NP-Based Router for the Open Network LabMeeting Notes John DeHart
Notes from 4/10/07 (HF Review) • Add Per block generic Error counters • HF should test for invalid port# and drop if found • Developers WorkBench has a code coverage utility • Can we read Local Memory from the XScale? • And if so, can we do it only while the ME is stopped or can we do it while it is running? • Counters for Rx and Tx per port: • Per port Rx counters in Mux • Per port Tx counters in HF • Rx and Tx will add sending Drop counters to Stats block • PLC drop if Plugin Ring is full • Plugins should wait if write ring is full • Rx will drop if SRAM ring to Mux is full • Are there MSF counters for dropped packets? • If so, can we access them?
Notes from 3/27/07 • Schedule? • Bank1: check SRAM access bw with QM and Rings • QID: Use 1-5 for port numbers in top 3 bits so that a DG qid of 0 will not result in a full QID=0 • NSP: Should we allow users to assign traffic to a DG queue • Do we need the Drop bit or is it sufficient to have a copy_vector of 0 to indicate a drop? • Define how/where sampling filters are implemented and how the sampling happens. • QIDs and Plugins are still fuzzy. • Should there be a restricted set of QIDs that the Plugins can allocate that the RLI and XScale are not allowed to allocate? • Can we put Output Port in data going to the XScale? • Buffer Offset: Should it point to the start of the ethernet header or start of the IP pkt? • Length fields in the buffer descriptor are they ethernet frame length or IP packet length? • Add Buffer Chaining slides.
Notes from 3/23/07 ONL Control Mtg • Using the same QID for all copies of a multicast does not work • The QM does not partition QIDs across ports • Do we need to support Datagram queues? • Yes, we will support 64 datagram queues per port • We will use the same Hash Function as in the NSP router • For testing purposes, can users assign the datagram queues to filters/routes? • Proposed partitioning of QIDs: • QID[15:13]: Port Number 0-4 • QID[12]: Reserved by RLI vs XScale • 0: RLI Reserved • 1: XScale Reserved • QID[11: 0] : per port queues • 4096 RLI reserved queues per port • 4032 XScale reserved queues per port • 64 datagram queues per port • yyy1 0000 00xx xxxx: Datagram queues for port <yyy> • IDT XScale software kernel memory issues still need to be resolved.
Notes from 3/13/07 • Ethertype needs to be written to buffer descriptor so HF can get it. • Who tags non-IP pkts for being sent to XScale: Parse? • We will not be supporting ethernet headers with: • VLANs • LLC/SNAP encapsulation • Add In Plugin in data going to a Plugin: • In Plugin: tells the last plugin that had the packet • Plugins can write to other Plugins sram rings • Support for XScale participation in an IP multicast • For use with Control protocols? • Add In Port values for Plugin and XScale generated packets • Include both In Port and In Plugin to lookup key? • Should flag bits also go to Plugins • For users to use our IP MCast support they must abide by the IP multicast addressing rules. • i.e. Copy will do the translation of IP MCast DAddr to Ethernet MCast DAddr so if the IP DA does not conform it can’t do it.
Issues and Questions • Upgrade to IXA SDK 4.3.1 • Techx/Development/IXP_SDK_4.3/{cd1,cd2,4-3-1_update} • Which Rx to use? • Intel Rx from IXA SDK 4.3.1 is our base for further work • Which Tx to use? • Three options: • Our current Tx (Intel IXA SDK 4.0, Radisys modifications, WU Modifications) • Among other changes, we removed some code that supported buffer chaining. • Radisys Tx based on SDK 4.0 – we would need to re-do our modifications • This would get the buffer chaining code back if we need/want it • Intel IXA SDK 4.3.1 Tx – no Radisys modifications, we would need to re-do our modifications • How will we write L2 Headers? • When there are >1 copies: • For a copy going to the QM, Copy allocates a buffer and buffer descriptor for the L2 Header • Copy writes the DAddr into the buffer descriptor • Options: • HF writes full L2 header to DRAM buffer and Tx initiates the transfer from DRAM to TBUF • Unicast: to packet DRAM buffer • Multicast: to prepended header DRAM buffer • HF/Tx writes/reads L2 header to/from Scratch ring and Tx writes it directly to TBUF • When there is only one copy of the packet: • No extra buffer and buffer descriptor are allocated • L2 header is given to Tx in same way as it is for the >1 copy case • How should Exceptions be handled? • TTL Expired • IP Options present • No Route • C vs. uc • Probably any new blocks should be written in C • Existing code (Rx, Tx, QM, Stats) can remain as uc. Freelist Mgr? • Continued on next slide…
Issues and Questions • Need to add Global counters • See ONLStats.ppt • Global counters: • Per port Rx and Tx: Pkt and Byte counters • Drop counters: • Rx (out of buffers) • Parse (malformed IP header/pkt) • QM (queue overflow) • Plugin • XScale • Copy (lookup result has Drop bit set, lookup MISS?) • Tx (internal buffer overflow) • What is our performance target? • 5-port Router, full link rates. • How should SRAM banks be allocated? • How many packets should be able to be resident in system at any given time? • How many queues do we need to support? • Etc. • How will lookups be structured? • One operation across multiple DBs vs. multiple operations each on one DB • Will results be stored in Associated Data SRAM or in one of our SRAM banks? • Can we use SRAM Bank0 and still get the throughput we want? • Multicast: • Are we defining how an ONL user should implement multicast? • Or are we just trying to provide some mechanisms to allow ONL users to experiment with multicast? • Do we need to allow a Unicast lookup with one copy going out and one copy going to a plugin? • If so, this would use the NH_MAC field and the copy vector field • Continued on next slide…
Issues and Questions • Plugins: • Can they send pkts directly to the QM instead of always going back through Parse/Lookup/Copy? • Use of NN rings between Plugins to do plugin chaining • Plugins should be able to write to Stats module ring also to utilize stats counters as they want. • XScale: • Can it send pkts directly to the QM instead of always going through Parse/Lookup/Copy path? • ARP request and reply? • What else will it do besides handling ARP? • Do we need to guarantee in-order delivery of packets for a flow that triggers an ARP operation? • Re-injected packet may be behind a recently arrived packet for same flow. • What is the format of our Buffer Descriptor: • Add Reference Count (4 bits) • Add MAC DAddr (48 bits) • Does the Packet Size or Offset ever change once written? • Yes, Plugins can change the packet size and offset. • Other? • Continued on next slide…
Issues and Questions • How will we manage the Free list? • Support for Multicast (ref count in buf desc) makes reclaiming buffers a little trickier. • Scratch ring to Separate ME • Do we want it to batch requests? • Read 5 or 10 from the scratch ring at once, compare the buffer handles and accumulate • Depending on queue, copies of packets will go out close in time to one another… • But vast majority of packets will be unicast so no accumulation will be possible. • Or, use the CAM to accumulate 16 buffer handles • Evict unicast or done multicast from CAM and actually free descriptor • Do we want to put Freelist Mgr ME just ahead of Rx and use NN ring into Rx to feed buffer descriptors when we can? • We might be able to have Mux and Freelist Mgr share an ME (4 threads per or something) • Modify dl_buf_drop() • Performance assumptions of blocks that do drops may have to be changed if we add an SRAM operation to a drop • It will also add a context swap. The drop code will need to do a test_and_decr, wait for the result (i.e. context swap) and then depending on the result perhaps do the drop. • Note: test_and_decr SRAM atomic operation returns pre-modified value • Usage Scenarios: • It would be good to document some typical ONL usage examples. • This might just be extracting some stuff from existing ONL documentation and class projects. • Ken? • It might also be good to document a JST dream sequence for an ONL experiment • Oh my, what I have done now… • Do we need to worry about balancing MEs across the two clusters? • QM and Lookup are probably heaviest SRAM users • Rx and Tx are probably heaviest DRAM users. • Plugins need to be in neighboring MEs • QM and HF need to be in neighboring MEs
Notes • Need a reference count for multicast. (in buffer descriptor) • How to handle freeing buffer for multicast packet? • Drops can take place in the following blocks: • Parse • QM • Plugin • Tx • Mux Parse • Reclassify bit • For traffic that does not get reclassified after coming from a Plugin or the XScale we need all the data that the QM will need: • QID • Stats Index • Output Port • If a packet matches an Aux filter AND it needs ARP processing, the ARP processing takes precedence and we do not process the Aux filter result. • Does anything other than ARP related traffic go to the XScale? • IP exceptions like expired TTL? • Can users direct traffic for delivery to the XScale and add processing there? • Probably not if we are viewing the XScale as being like our CPs in the NSP implementation.
Notes • Combining Parse/Lookup/Copy • Dispatch loop • Build settings • TCAM mailboxes (there are 128 contexts) • So with 24 threads we can have up to 5 TCAM contexts per thread. • Rewrite Lookup in C • Input and Output on Scratch rings • Configurable priorities on Mux inputs • Xscale, Plugins, Rx • Should we allow plugins to write directly to QM input scratch ring for packets that do not need reclassification? • If we allow this is there any reason for a plugin to send a packet back through Parse/Lookup/Copy if it wants it to NOT be reclassified? • We can give Plugins the capability to use NN rings between themselves to chain plugins.