Download

1 / 24
240 likes | 447 Views
Segmented Hash: An Efficient Hash Table Implementation for High Performance Networking Subsystems. Sailesh Kumar Patrick Crowley. Problem Statement. How to implement deterministic hast tables Near worst case O (1) deterministic performance We are given with a small amount of on-chip memory

E N D
Segmented Hash: An Efficient Hash Table Implementation for High Performance Networking Subsystems Sailesh Kumar Patrick Crowley
Problem Statement • How to implement deterministic hast tables • Near worst case O(1) deterministic performance • We are given with a small amount of on-chip memory • On-chip memory limited to 1-2 bytes per table entry • In this paper we tackle the above problem
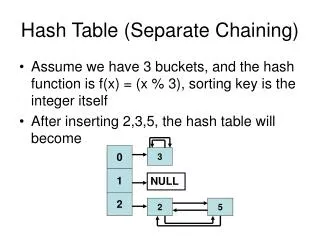
kiwi 0 1 2 3 4 5 6 7 8 9 banana Watermelon honeydew apple mango cantaloupe grapes Hash Tables • Hash table uses a hash function which is used to index the table entries • hash("apple") = 5hash("watermelon") = 3hash("grapes") = 9hash("cantaloupe") = 7hash("kiwi") = 0hash("mango") = 6hash("banana") = 2 • hash("honeydew") = 2 • This is called collision • Now what honeydew No. of keys mapped to a bucket is called collision chain length honeydew Linear Probing Double Hashing Hash2(honeydew) = 3 Linear Chaining
Performance Analysis • Average performance is O(1) • However, worst-case performance is O(n) • In fact the probability of collision chain > 1 is pretty high These keys will take twice time to be probed Pretty high probability that performance is half or three times lower These will take thrice the time to be probed
k i +1 k is mapped i +1 h ( ) to this bucket k i h ( ) k is mapped i to this bucket 2 1 1 1 2 1 2 1 2 A 4-way segmented hash table Segmented Hashing • Uses power of multiple choices • has been proposed and used earlier by several authors • A N-way segmented hash • Logically divides the hash table array into N equal segments • Maps the incoming keys onto a bucket from each segment • Picks the bucket which is either empty or has minimum keys 1 2
Segmented Hash Performance • More segments improves the probabilistic performance • With 64 segments, probability of collision chain > 2 is nearly zero even at 100% load • More deterministic hash table performance
k i h ( ) An Obvious Deficiency Every query requires 4 probes 2 1 1 1 2 1 2 0 1 2 • O(N) memory probes per query • Requires N times higher memory bandwidth • How to ensure an O(1) memory probes per query • Use Bloom filters implemented using small on-chip memory (filters out unnecessary memory accesses) • Before going further brief introduction of Bloom filters
1 1 H1 1 X H2 H3 H4 Hk 1 1 Bloom Filter m-bit Array Bloom Filter
1 1 1 H1 1 Y H2 H3 1 H4 Hk 1 1 1 Bloom Filter m-bit Array
1 1 1 H1 1 X H2 H3 1 H4 Hk 1 1 1 Bloom Filter match m-bit Array
1 1 1 H1 1 W H2 H3 1 H4 Hk 1 1 1 Bloom Filter Match (false positive) m-bit Array
k k can go to any of the 3 buckets i i h ( ) h ( ki ) 1 h ( ki ) 2 : h ( ki ) k Adding per Segment Filters We can select any of the above three segments and insert the key into the corresponding filter 2 1 1 1 2 1 2 0 1 2 1 0 0 1 m b bits 0 1 0 0 0 1 0 1
False Positive Rates • With Bloom Filters, there is likelihood of false positives • False positive means unnecessary memory accesses • With N segments, clearly the false positive rates will be at least N times higher • In fact, it will be even higher, because we have to also consider several permutations of false positives • We use Selective Filter Insertion algorithm, which reduces the false positive rates by several orders of magnitude
k can go to any of the 3 buckets i Selective Filter Insertion Algorithm k i h ( ) 2 1 1 1 2 1 2 0 1 2 1 0 0 1 Insert the key into segment 4, since fewer bits are set. Fewer bits are set => lower false positive h ( ki ) 1 m h ( ki ) 2 b : bits 0 1 0 0 h ( ki ) With more segments (or more choices), our algorithm sets far fewer bits in the Bloom filter k 0 1 0 1
Selective Filter Insertion Details • Greedy policy • For every arriving key • We choose the segment where minimum bits are set in the Bloom filter • We show that this leads to unbalanced segments • Reduced performance
k 1 h ( ) h ( ) 1 h ( ) 2 Selective Filter Insertion Algorithm 1 1 1
k 2 h ( ) h ( ) 1 h ( ) 2 Selective Filter Insertion Algorithm 1 1 1 1 1
k 3 h ( ) h ( ) 1 h ( ) 2 Selective Filter Insertion Algorithm 1 1 1 1 1 1 1
k 4 h ( ) h ( ) 1 h ( ) 2 Selective Filter Insertion Algorithm 1 1 1 1 1 1 1 1 1
k 5 h ( ) Reduced No. of choices h ( ) 1 h ( ) 2 Selective Filter Insertion Algorithm 1 1 1 1 1 1 1 1 1
Selective Filter Insertion Enhancement • Objective is to keep segments balanced • Might need to make sub-optimal choices at times • One way is to avoid the most loaded segment • Reduces number of choices by 1 • However, it leads to situations where two segments alternately leads • Things get complicated • More detailed version of algorithm can be found in paper
Simulation Results • 64K buckets, 32 bits/entry Bloom filter. • Simulation runs for 500 phases. • During every phase, 100,000 random searches are performed. Between two phases, 10,000 random keys are deleted and inserted.
Conclusion • We presented a way to implement • Hash tables with deterministic performance • We utilize small on-chip memory to achieve it • We also show that on-chip memory requirements are modest • Well within the Moore’s law • A 1M hash table for example needs 1-2MB of on-chip memory • Questions?