Download
1 / 49

E N D
FIGURE 4 Responses of dopamine neurons to unpredicted primary reward (top) and the transfer of this response to progressively earlier reward-predicting conditioned stimuli with training (middle). The bottom record shows a control baseline task when the reward is predicted by an earlier stimulus and not the light. From Schultz et al. (1995) with permission.
Odor Selective Cells in the Amygdala fire preferentially with regard to outcome or reward value of an odor prior to demonstration that the animal has learned this outcome or value. Odor Selective Cells in the Amygdala fire preferentially with regard to outcome or reward value of an odor simultaneous to demonstration that the animal has learned this outcome or value.
Cells in Orbitofrontal Cortex (OFC) show less selectivity to outcome, in rats without an amygdala. This demonstrates a role for the amygdala in conveying motivational/reward information to the OFC.
Dopamine, reward processing and optimal predictionONLY AS A REFERENCE FOR THOSE WHO ARE INTERESTED IN BEGINNING TO CROSS THE NEUROBEHAVIORALCOMPUTATIONAL DIVIDE – Maybe after the Exam??
Cortical and striatal projections Schultz, 1998
Expected Reward v = wu v : expected reward w : weight (association) u : stimulus (binary)
Rescorla-Wagner Rule Association update rule: w w + αδu w : weight (association) α : learning rate u : stimulus Prediction error: δ = r - v r : actual reward v : expected reward
Rescorla - Wagner provides account for: Some Pavlovian conditioning Extinction Partial reinforcement and, with more than one stimulus: Blocking Inhibitory conditioning Overshadowing … but not Latent inhibition (CS preexposure effect) Secondary conditioning
A recent update: uncertainty (i²) Kakade, Montague & Dayan, 2001
Kalman weight update rule: wiwi + αi δ With associability: αi=i² ui jj² uj+E
U1 U2 U3 U4 U5 input U(t)
input U(t) r(t)
input U(t) w(t) r(t)
input U(t) ŵ(t) v(t)
input U(t) ŵ(t) r(t) v(t)
input U(t) ŵ(t) δ(t) r(t) v(t)
Error Rule (t) = r(t) - v(t)
U(t) ŵ(t) inset Ui -input i -uncertainty v(t) wi -weight
Kalman learning & associability weight update rule: ŵi (t+1) = ŵi (t) + αi (t) δ(t) associability: αi(t)=i(t)² xi(t) jj(t)² xj(t)+E
Predicting future reward single time steps: v = wuv : expected reward w : weight (association) u : stimulus total predicted reward: v(t) = w(τ) u(t - τ) t : time steps in a trial τ : current time step t τ=0
Sum of discounted future rewards: With 0 ≤ γ≤ 1 In recursive form: Schultz, Dayan & Montague, 1997
Temporal difference rule Total estimated future reward:v(t) = r(t)+ γv(t+1) r(t) = v(t)-γv(t+1) Temporal difference rule: δ = r(t)+γv(t+1)-v(t) (With single time steps: δ = r - v r : actual reward v : expected reward )
Temporal difference rule Total estimated future reward:v(t) = r(t)+v(t+1) r(t) = v(t)-v(t+1) Temporal difference rule: δ = r(t) + v(t+1)-v(t) (With single time steps: δ = r - v r : actual reward v : expected reward )
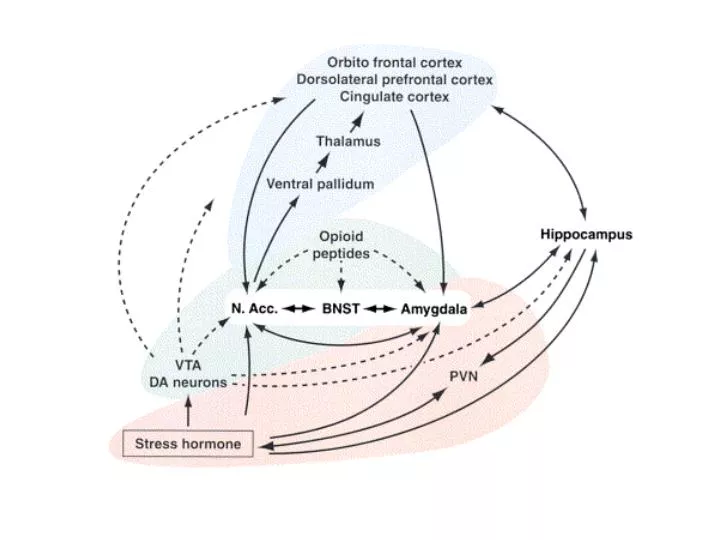
Anatomical interpretation Schultz, Dayan & Montague, 1997
Temporal Difference Rule for Navigation between successive steps u and u’ δ = ra (u) + γ v(u’)-v(u)
Behavior evaluation Hippocampal place field Foster, Morris & Dayan 2000
Spatial learning Foster, Morris & Dayan 2000
Conclusions • Behavioral study of (nonhuman) neural systems is interesting • Neural processes amenable to contemporary learning theory • .. they may play distinct roles a normative framework of learning e.g. vta, hippocampus, subiculum, also- Ach in NBM/SI,NE inLC,5-HT,ventral striatum, lateral connections , core/shell distinctions of the NAAC, patch-matrix anatomy in basal ganglia, the superior colliculus, psychoalphabetadiscobioaquadodoo