Download

1 / 19
200 likes | 331 Views
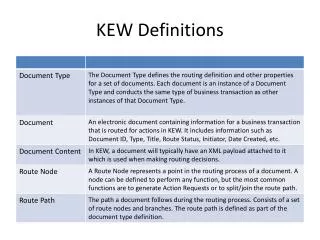
Brief Notes from Kew. Mark Jackson Software Applications Manager. Focussing on. Herbarium digitisation electronic Plant Information Centre. Kew Herbarium. Guesstimated 7 million specimens 250,000 types Less than 5% specimens databased A variety of personal databases.

E N D
Brief Notes from Kew Mark Jackson Software Applications Manager
Focussing on... • Herbarium digitisation • electronic Plant Information Centre
Kew Herbarium • Guesstimated • 7 million specimens • 250,000 types • Less than 5% specimens databased • A variety of personal databases
Preparation for Digitisation • Computerise transactions • Agree and document policy and procedures • Establish core fields (HISPID pending ABCD) • Develop hardware and software infrastructure (e.g. catalogue database, mass storage)
Digitisation Strategy • Curators to barcode, database and image types for loan • Repatriation & research projects • to use infrastructure and core fields • data to be imported into Catalogue (eventually) • Pursue digitisation projects www.kew.org/data/repatbr
Specimen imaging • Decision to try to match Cibachrome prints in terms of quality (e.g. suitable for many diagnostic purposes) • 600 dpi delivers 200MB images • Stored as uncompressed (but bzipped) TIFFs • Acquisition of mass storage
HerbScan • A3 flatbed scanner, inverted • Cradle for specimens • Distributed throughout Herbarium
£30-40,000 200MB images barely achievable 1 image per minute Fixed Versatile £7,500 200MB images easily achievable 10 images per hour Some mobility Suited to flat items Pros and cons 200 MB master images (600 dpi scans), based on capturing the level of detail of Cibachromes. CameraHerbScan
HerbCat enquiries image enquiries Client Image Server HerbCat Images Metadata
Focussing on... • Herbarium digitisation • electronic Plant Information Centre
UK government funding for delivery of services electronically • Resource-discovery interface to multiple Kew data sources (not necessarily at Kew) • Data sources are heterogenous • Simple interface overlaying other systems ePIC Interface Data source Data source Data source Data source
Architecture Interface (java servlet)/JSPs Requests Results Multi-threaded Java server Request queue Data sources Data sources Handlers: one per data source one for logging one for spell-checking Configuration files (XML)
Texts • Web documents indexed using Lucene • Flora Zambesiaca digitised and marked-up with XML • Experimentation with options for query and output via Java servlet • using XSL to output selections • using Lucene to index the XML • importing the XML into a database • Other texts - jury still out, but Lucene route looks promising
Feedback • Email mechanisms • Web usability testing/focus groups • Logging • Quantitative success • levels of usage, patterns & trends • beware: crawlers, testing & development staff, harvesters • referring URLs, Google link: popularity of site • country, domain • Qualitative success • success of queries esp. zero hits (spelling, common names, families) • performance & system monitoring • number of queries per session, return visits • results pages viewed
Future www.kew.org/epic • More data sources, including texts and images • Hierarchical browsing front-end based around revamped Brummitt Families & Genera with phylogenetic classification • Looking forward to • using the GBIF Names Service… • links with DiGIR/BioCASE resources...