Download

1 / 43
580 likes | 1.46k Views
第四章 队列研究 ( cohort study ). 前瞻性研究 (Prospective study) ;发生率研究( incidence study) ; 随访研究 (follow-up study) ;纵向研究 (longitudinal study). 概述 研究实例 研究设计与实施 资料整理与分析 常见偏倚及其控制 优点与局限性. 第一节 概 述. 一、概念 1 、队列:有共同经历或状态的一群人。 固定队列( fixed cohort ):指某特定事件发生时所有的人

E N D
第四章 队列研究 (cohort study) 前瞻性研究(Prospective study);发生率研究(incidence study); 随访研究(follow-up study);纵向研究(longitudinal study) 概述 研究实例 研究设计与实施 资料整理与分析 常见偏倚及其控制 优点与局限性
第一节 概 述 一、概念 1、队列:有共同经历或状态的一群人。 固定队列(fixed cohort):指某特定事件发生时所有的人 作为一个队列,或相对稳定、相对大的人群。原子弹 爆炸后形成的队列。 动态队列(dynamic cohort):是经常增加或减少队列成员 的队列。 2、队列研究:选择暴露于及非暴露于某因素的两组人群,随访观察一定时间,比较两组人群某种疾病的结局(发病率、死亡率)从而判断该因素与发病或死亡有无关联及关联的大小。 3、暴露(exposure):研究对象接触过某种待研究的物质、具备某种待研究的特征或行为。 4、危险因素(risk factor):泛指引起某特定结局(outcome)的发生,后使其发生的概率增加的因子。
二、 基本原理 现在 将来 暴露 疾病 人数 比较 a a/(a+b) b c c/(c+b)_ d 无干预 是否暴露 + + - 目标人群 - + -
基本特征 • 属于观察法 • 设立对照组 • 由“因及果”的研究 • 能证明暴露与结局的因果联系(可信性强) • 一“因”多“果”的研究
三、研究目的 1、检验病因假设:验证某种因素对某种疾病发病率、死亡率或某种 健康状态的影响。 2、评价预防效果:“人群的自然实验”。 3、描述疾病的自然史:疾病的全部自然发生、发展的 过程为疾病的自然史。
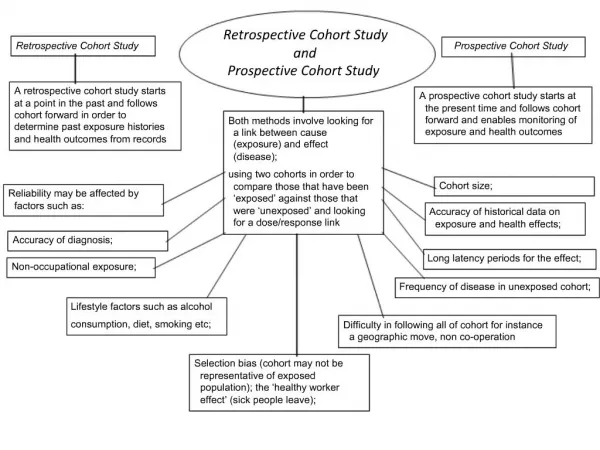
四、研究类型 (一)前瞻性队列研究(prospective cohort study);即时性队列研究(concurrent cohort study):开始时确定对象、分组,经随访得到结局。 优点:资料准确 缺点:样本大;花费大;时间长 (二)历史性队列研究(historical cohort study);非即时性队列研究(nonconcurrent cohort study):开始时已得到结局,对象确定、分组在过去某时间。研究者掌握研究对象过去某时点暴露状况的历史材料和自此时点到现在的结局材料 优点:省人、物、时 缺点:无混杂因素的资料 (三)双向性队列研究(ambispective cohort study):历史队列研究后继续进行前瞻性队列研究 具有第一、二类优点而克服其缺点
(历史性) 研究开始 (前瞻性) 暴露组 ------------------------→ 非暴露组(双向性队列研究) 暴露组 非暴露组 过去现在 将来 追溯收集历史资料 继续追踪收集资料 追踪收集资料
(四)不同研究类型的选用原则 前瞻性队列研究 1、目的明确 2、疾病发病率或死亡率≥5‰ 3、能获得暴露资料 4、确定结局的方法简便可靠 5、有足量样本,且人群稳定 6、有足够的可利用资源 历史性队列研究 要有完整可靠的历史记录或档案 双向性对列研究 从暴露到现在的观察时间还不能满足研究的要求,还需前瞻性观察一段 时间
第二节 研究实例 石棉与肺癌联系的病例对照研究 • Mount-Sinai研究:接触石棉粉尘的四个职业人群为暴露组,总人群为非暴露组。肺癌SMR=5.31;胃肠道肿瘤=2.06;全肿瘤=3.26;全死因=1.47 • 数个规模较大的研究证明二者联系有普遍性 • 特异性:肺癌联系最强;肺腺癌占30%-40%(一般人群=15%-20%);病变部位在肺下叶周边部 • 剂量反应关系:时间:暴露1个月SMR=2.24;1年为SMR=7.84 浓度:男、 >2年、低者SMR=1.6;高者=2.3
第三节 研究设计与实施 • 确定研究因素 • 确定研究结局 • 确定研究现场与研究人群 • 确定样本量 • 资料的收集与随访 • 质量控制
一、确定研究因素:暴露因素(危险因素;保护因素),一般在描述性研究和病例对照研究基础上进行一、确定研究因素:暴露因素(危险因素;保护因素),一般在描述性研究和病例对照研究基础上进行 二、确定研究结局(outcome):研究者预期的结果事件;死亡、发病以及某些试验指标的变化 三、确定研究现场和研究人群 (一)研究现场:有足量研究对象;领导重视;群众配合;交通方便;文化水平、医疗卫生条件好
(二)研究人群 1、暴露人群 (1)职业人群:联苯胺致膀胱癌——染料厂工人 石棉致肺癌——石棉作业工人 (2)特殊暴露人群:对某因素有高暴露率的人群(放 射线辐射与白血病之关系:受原子弹爆炸危害 者;接受放射线治疗者) (3)一般人群:吸烟与肺癌;口服避孕药与子宫内膜 癌;饮食与高血压等。 缺点:面访个体而不能从记录中获取资料 注意问题:因素与疾病均应常见;无或不需 特殊暴露人群 (4)有组织的团体:医学、工会会员;参加保险者 (吸烟与肺癌)
2、对照人群的选择 可比性 (1)内对照:同一队列无暴露或暴露水平低者 如Framingham心脏病研究 (2)外对照:在特殊暴露人群以外的特设对照 放射科医师——五官科医师 (3)一般人群对照:发病或死亡率易得且稳定 缺点:资料粗糙,项目不全 注意:时间和地区应同暴露人群 (4)多重对照:多种对照
四、确定样本量(size of sample) 1、注意问题 (1)抽样方法 (2)暴露组与对照组的比例:相等 (3)失访率:按10%估计 2、影响因素 (1)一般人群中所研究疾病的发病率(p0) (2)暴露人群发病率( p1);d=p1-p0 p1=RR•p0 (3)希望的显著性水平(a=0.05 or =0.01) • (4)希望的把握度(power):(1- b=0.9)
3、计算 公式:
例:评价口服避孕药与子女患先天性心脏病之关系例:评价口服避孕药与子女患先天性心脏病之关系 已知:非暴露组发病率为P0=0.07 q0=1.993 假定 RR=2.5 设 a=0.5 b=0.1 查表 Za=1.96 Z b=1.282 求:每组n=? 计算:P1RR•p0=0.0175 q1=1-p1=0.0175 代入上式计算: n=2310 如考虑失访: n=2310(1+0.1)=2541
公式: 例:放射线与白血病,人群发病率(p0)=0.0001, 暴露组发病率(p1)=0.001。 定:a=0.05(双侧)b=0.1 查表:Ua=1.96 Ub=1.282 代入上式得:每组n≈14266(人) 考虑失访:每组n= 14266+ 14266×10% ≈15693(人)
五、资料的收集与随访 (一)基线资料收集(baseline information): 待研究的暴露因素和暴露情况的资料,疾病与健康状况的资料以及个人信息资料 1、记录或档案 2、访问 3、体检及实验室检查 4、环境资料
(二)随访 1、随访期:据疾病的潜伏期(病因作用到临床发现)和暴露与疾病的联系强度作出 2、随访目的:1)确定研究对象是否处于观察之中(分母) 2)确定人群中事件结局(分子) 3)收集混杂因素的资料 3、随访方法:1)利用记录或档案 2)特殊方法:面谈、电话、通信 3)环境检测 4、观察终点(end point)与终止时间:前者是观察对象出现了预期的结果;后者是整个研究可得出结论的时间 5、间隔时间:据具体情况而定 6、随访者:培训
六、质量控制 1、调查员的选择 2、调查员的培训 3、制定调查手册 4、监督 重复调查;数值检查或逻辑检错;定期观察调查员的工作;对不同调查员的数据进行分布比较;变量的时间趋势分析;使用录音机
第四节 资料的整理与分析 一、队列研究资料整理表
流行病学资料分析原则 1、描述性分析: • 研究对象的一般特征 • 均衡性检验 2、推断性分析: • 显著性检验:比较两组率(暴露比例)有无显著性差异 • 效应估计(联系强度) :用率或暴露比估计 3、控制混杂因素:匹配;分层;多因素分析
二、人时计算(person time) (一)以个体为单位计算暴露人年(person year): 精确法:以天为单位,计算研究对象被观察的天数,折合成人年。 近似法:以年为单位计算,开始与终止年份各算0.5年,同一年开始 与终止者算0.25年,开始与终止年份之间算1年,累积人年。 (二)动态人群:不知道每个成员进入和退出的准确时间,只有每年横断面调查的资料。以平均人数乘观察年数得总人年数;平均人数为相邻两时段人口平均数或年中人数。 表 动态人群人年计算 例:35~岁组: 人年数=(8836+9149)/2+(9149+9287)/2+(9287+9414)/2+ (9414+9710)/2+(9710+9796)/2×5/12=41211(人年)
(三)寿命表法: Lx=Ix+1/2(Nx-Dx-Wx) Ix+1=Ix+Nx-Dx-Wx 其中:Lx为x时间内暴露人年数; Ix为x时间开始时的人数; Nx为x时间内进入队列的人数; Dx为x时间内出现终点结局的人数; Wx为x时间内失访的人数
表 寿命表法计算人 第一年暴露人年数为: L1=I1+1/2(N1-D1-W1)=1403+1/2(79-4-30)=1425.5 I2=I1+N1-D1-W1=1403+79-4-30=1448 L2=1448+1/2(45-2-11)=1464 以此类推,合计得13336.5人年
三、率的计算 (一)常用指标 1. 累积发病率(cumulative incidence): 简单累积法:(适用于固定队列) 表 钩体感染与脑动脉炎关系的队列研究 中国人畜共患病杂志 1988, 4(3):44 1)卡方检验:c2=20.6 自由度=1 P<0.01 2)U检验:大样本,样本率的频数分布接近于正态分布时
2、发病密度法(incidence density;ID):(适用于动态队列) 发病密度:一定时期内的平均发病率(以人时为分母计算的发病率) ID=D/PT D:观察期间发病数 PT:观察人时数(person time) PT=观察人数×观察时间 观察时间常用年(人年数,person year) 1个月=0.0833年,1天=0.00274年 对发病密度资料,要进行c2检验。
例:广岛原子弹爆炸后幸存者16年队列研究,资料如下:例:广岛原子弹爆炸后幸存者16年队列研究,资料如下: 表 原子弹爆炸后幸存者中白血病发病率 中国流行病学杂志 1988, 9(2):111 设: M1为两组发病人数之和; N1为暴露组观察人年数 N0为非暴露组观察人年数; T为总观察人年数 a为暴露组发病例数; c为非暴露组发病例数 则: c界值=U界值,本例c =9.75>U0.01 P<0.01
3. 标化法 1、标化率:粗率不能比较,年龄标化后比较 2、标化死亡(发病)比(standard mortality rate, SMR):实际死亡(发病)人数与以全人口的死亡 (发病)率为标准计算出预期死亡(发病)人数之 比。用于死亡(发病)率较低时。 例:某人群观察期内冠心病死亡80人,已知用该地全人口冠心病死亡率为标准计算出的预期死亡人数为71人,求:SMR=? 即该人群死于冠心病的危险超过相应全人群的0.13倍。
标化比例死亡比(standard proportional mortality rate, SRMR):是因某病死亡的人数与由因该病死亡占全死因死亡的比例乘以该人群实际死亡数所计算的预期死亡数的比。 用于得不到人群历年得人口资料,而仅有死亡数、 日期和年龄时。 例:某厂20~40岁工人死亡总数为292,其中因结核病死亡100人,全人口该年该年龄组因结核病死亡者占全死因死亡数的比例为6.28%,求:SPMR=? 该例: 说明该厂该年20~24岁组结核病死亡的危险是一般人群的5.45倍。
(二)显著性检验: SMR95%CI: 下限:Lp/E(D) 上限:Up/E(D) Lp ,Up分别为按Poission分布所得的死亡数可信区间的上限和下限;D为实际死亡数;E(D)为预期死亡数。 计算:当D>50时,用正态分布法求SMR95%CI 当D≤50时,用Poission查表求SMR95%CI 本例:D>50=80, 则: 如果该区间包含SMR,则差别无统计学意义。
显著性检验:把观察死亡数D作为均数是期望死亡数E的Poission分布。显著性检验:把观察死亡数D作为均数是期望死亡数E的Poission分布。 当E≥10时,可进行正态近似检验: 或: (自由度=1) 本例: 无显著性差异 当E<10时,按Poission分布的原理检验
危险度 risk 四、效应的估计(联系强度) 1、资料整理 表6-5 队列研究资料整理表 2、计算 (1)相对危险度(relative risk, RR): RR=Ie/Io=(a/n1)/(c/n0) 暴露对于个体增加危险性的倍数
相对危险度(RR)与关联强度 (Monson RA, 1980)
RR95%CI: 1)Woolf法: RR95%CI=exp(lnRR±1.96 ) Var(lnRR)=1/a+1/b+1/c+1/d 2)Miettinen法: (2)归因危险度(attributive risk,AR)或称率差( rate difference,RD) AR=Ie-Io=(a/n1)-(c/n0)=RRΧ Io- Io = Io(RR-1) 暴露增加的超额危险度(excess risk) AR95%CI=AR ±1.96s
(3)归因危险度百分比(attributive risk proportion, ARP,AR%)或称暴露人群归因分值(attributive fraction,AFe),或称暴露人群病因分值( etiologic fraction,EFe) ARP=AR%= (Ie – I0)/Ie = (RR-1)/RR 暴露人群中归因于暴露的发病或死亡占全 部发病或死亡的比例。如吸烟与肺癌关系研究表明,AFe=90.7%,说明吸烟者中的肺癌90.7%归因于吸烟,而非群全部由吸烟引起。
(4)人群归因危险度(population attributive risk,PAR) PAR=It – Io 整个人群中某时期由于某暴露因素引起该病发病或死亡的率。 (5)人群归因危险度百分比(population attributive risk proportion,PARP,PAR%)(人群归因分值 population etiologic fraction,PEF) PARP=PAR%=(It – Io)/It = Pe(RR-1)/1+Pe(RR-1) Pe:人群中某种暴露者的比例 人群中某暴露因素引起的发病或死亡占整个人群该病发病或死亡的比例。
例: 已知:吸烟者肺癌年死亡率(Ie)为0.96‰,非吸烟 者(Io)为0.07‰,全人群为(It) 0.56‰,则: RR= Ie/Io= 0.96‰/ 0.07‰=13.7 AR= Ie-Io= 0.96‰-0.07‰=0.89‰ AR%=(Ie-Io)/ Ie×100%=92 .7% PAR= It-Io= 0.56‰-0.07‰=0.49‰ PAR%= (It-Io)/ It×100%=87.5%
(5)剂量反应关系分析 表 49-59岁男性按初始血清胆固醇水平 (mg/dl)分组的冠心病6年发病情况 计算:CIi=ai/ni AIi=CIi/6 RRi+1=[ai+1×(ni -ai)]/[ai×(ni+1-ai+1) ] ARi+1=(CIi+1- CI1)
五、分层分析和多因素分析 • 分层分析:同病例对照研究 • 多因素分析 Logistic回归模型(Logistic regression model) Cox回归模型( Cox regression model)
六、健康工人效应(health worker effect) 定义:最初在职业流行病学研究中观察到的现象,即由于工人队列健康状况优于其他人群,其总死亡率常低于一般人群。因此,不能将工 人死亡率与一般人群死亡率直接比较。健康工人效应常低估暴露与疾病的联系。 处理: (1)将每一年龄组的期望死亡数乘以0.9 (2)将全国性大企业工人死亡率与全国人口死亡率比较,以其死亡率比值的平均值为校正系数,将调查的期望死亡数乘以校正系数,进行校正。
第五节 常见偏倚(bias)及其控制 一、选择偏倚:原因:拒绝参加;记录不全;志愿者特征; 定义不严格;开始时未诊断出早期病例 二、失访偏倚:原因:迁出;外出;不再合作;死亡(不>10% ) 影响:失访率;失访者特征;两组失访差异 三、信息偏倚:错分偏倚(misclasfication bias):暴露错分; 疾病错分;联合错分 原因:仪器不准;检验技术不熟;定义不明 影响:误差异错分;有差异错分 四、混杂偏倚:由于混杂因子的影响造成(匹配;分层;多 因素分析)
第六节 优点与局限性 (一)优点: 1、可获得暴露组与非暴露组的死亡率、发病率,直接计算相对危险度 2、检验病因假说的能力强,结论有说服力 3 、可了解疾病自然史;可研究一种因素与多种结局的关系 4、样本量大结果稳定 5、了解基线率,为制定预防规划提供资料 6、资料完整可靠,无回忆偏倚 (二)缺点: 1、不适于研究发病率低的疾病 2、易产生失访偏倚 3、花费时间、人力物力、财力大 4、随研究时间推移,未知因素进入研究人群可影响结局 5、设计要求高,实施难度大