Download
1 / 1
10 likes | 110 Views
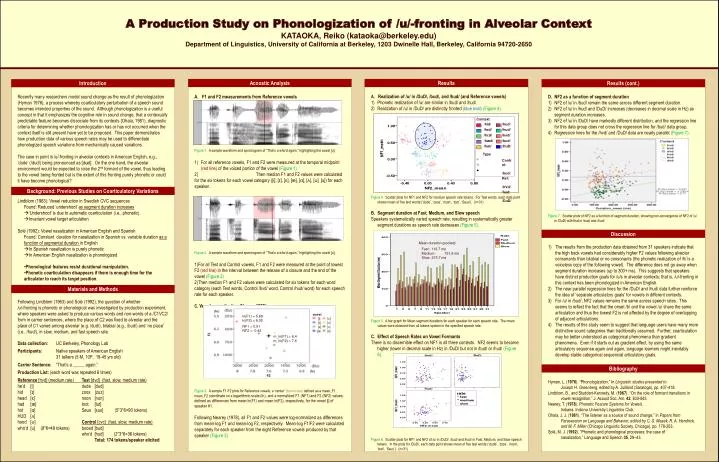
A Production Study on Phonologization of /u/-fronting in Alveolar Context KATAOKA, Reiko (kataoka@berkeley.edu) Department of Linguistics, University of California at Berkeley, 1203 Dwinelle Hall, Berkeley, California 94720-2650. Acoustic Analysis. Results. Introduction. Results (cont.).

E N D
A Production Study on Phonologization of /u/-fronting in Alveolar Context KATAOKA, Reiko (kataoka@berkeley.edu)Department of Linguistics, University of California at Berkeley, 1203 Dwinelle Hall, Berkeley, California 94720-2650 Acoustic Analysis Results Introduction Results (cont.) • A. Realization of /u/ in /DuD/, /bud/, and /hud/ (and Reference vowels) • Phonetic realization of /u/ are similar in /bud/ and /hud/. • Realization of /u/ in /DuD/ are distinctly fronted (blue oval) (Figure 4). • Figure 4. Scatter plots for NF1 and NF2 for medium speech rate tokens. For Test words, each data point shows mean of five test words (‘dude’, ‘zoos’, ‘noon’, ‘toot’, ‘Seus’). (n=31) • Segment duration at Fast, Medium, and Slow speech • Speakers systematically varied speech rate, resulting in systematically greater segment durations as speech rate decreases (Figure 5). • Figure 5. A bar graph for Mean segment durations for each speaker for each speech rate. The mean values were obtained from all tokens spoken in the specified speech rate. • Effect of Speech Rates on Vowel Formants • There is no discernible effect on NF1 in all three contexts. NF2 seems to become higher (lower in decimal scale in Hz) in /DuD/ but not in /bud/ or /hud/ (Figure 6). • Figure 6. Scatter plots for NF1 and NF2 of /u/ in /DuD/, /bud/ and /hud/ in Fast, Medium, and Slow speech tokens. In the plots for /DuD/, each data point shows mean of five test words (‘dude’, ‘zoos’, ‘noon’, ‘toot’, ‘Seus’). (n=31) Recently many researchers model sound change as the result of phonologization (Hyman 1976), a process whereby coarticulatory perturbation of a speech sound becomes intended properties of the sound. Although phonologization is a useful concept in that it emphasizes the cognitive role in sound change, that a contexually predictable feature becomes dissociate from its contexts (Ohala, 1981), diagnostic criteria for determining whether phonologization has or has not occurred when the context itself is still present have yet to be proposed. This paper demonstrates how production data of various speech rates may be used to differentiate phonologized speech variations from mechanically caused variations. The case in point is /u/-fronting in alveolar contexts in American English, e.g., ‘dude’ (/dud/) being pronounced as [dʉd]. On the one hand, the alveolar environment would be expected to raise the 2nd formant of the vowel, thus leading to the vowel being fronted but is the extent of this fronting purely phonetic or could it have become phonological? • A. F1 and F2 measurements from Reference vowels • Figure 1. A sample waveform and spectrogram of “That’s a who’d again,” highlighting the vowel [u]. • For all reference vowels, F1 and F2 were measured at the temporal midpoint (red line) of the voiced portion of the vowel (Figure 1). • 2) Then median F1 and F2 values were calculated for the six tokens for each vowel category ([i], [ɪ], [ɛ], [æ], [ɑ], [ʌ], [ʊ], [u]) for each speaker. • F1 and F2 measurements from Test and Control vowels • Figure 2. A sample waveform and spectrogram of “That’s a who’d again,” highlighting the vowel [u]. • For all Test and Control vowels, F1 and F2 were measured at the point of lowest F2 (red line) in the interval between the release of a closure and the end of the vowel (Figure 2). • Then median F1 and F2 values were calculated for six tokens for each word category (each Test words, Control /bvd/ word, Control /hud/ word) for each speech rate for each speaker. • C. Vowel normalization (Nearey 1978) • Figure 3. A sample F1-F2 plots for Reference vowels, a ‘center’ (brown star) defined as a mean_F1, mean_F2 coordinate on a logarithmic scale (ln), and a normalized F1 (NF1) and F2 (NF2) values, defined as differences from mean ln(F1) and mean ln(F2), respectively, for the vowel [i] of speaker #1. • Following Nearey (1978), all F1 and F2 values were log-normalized as differences from mean-log F1 and mean-log F2, respectively. Mean-log F1/F2 were calculated separately for each speaker from the eight Reference vowels produced by that speaker (Figure 3). • NF2 as a function of segment duration • NF2 of /u/ in /bud/ remain the same across different segment duration. • NF2 of /u/ in /hud/ and /DuD/ increases (decreases in decimal scale in Hz) as segment duration increases. • NF2 of /u/ in /DuD/ have markedly different distribution, and the regression line for this data group does not cross the regression line for /bud/ data group. • Regression lines for the /hvd/ and /DuD/ data are nearly parallel (Figure 7). • Figure 7. Scatter plots of NF2 as a function of segment duration, showing non-convergence of NF2 of /u/ in /DuD/ with that in /bud/ and /hud/. • Context • /hid/ /hud/ • /hɪd/ /hʊd/ • /hɛd/ /hʌd/ • /hæd/ /bud/ • /hɑt/ /DuD/ • Type • Control: /bud/ • Ref: /hVd/ • Test: /DuD/ Background: Previous Studies on Coarticulatory Variations • Lindblom (1963): Vowel reduction in Swedish CVC sequences • Found: Reduced ‘undershoot’ as segment duration increases • ‘Undershoot’ is due to automatic coarticulation (i.e., phonetic). • Invariant vowel target articulation • Solé (1992): Vowel nasalization in American English and Spanish • Found: Constant duration for nasalization in Spanish vs. variable duration as a function of segmental duration in English • In Spanish nasalization is purely phonetic • In American English nasalization is phonologized • Phonological features resist durational manipulation. • Phonetic coarticulation disappears if there is enough time for the articulator to reach its target position. Discussion • The results from the production data obtained from 31 speakers indicate that the high back vowels had considerably higher F2 values following alveolar consonants than bilabial or no consonants (the phonetic realization of /h/ is a voiceless copy of the following vowel). The difference does not go away when segment duration increases (up to 300+ ms). This suggests that speakers have distinct production goals for /u/s in alveolar contexts; that is, /u/-fronting in this context has been phonologized in American English. • The near parallel regression lines for the /DuD/ and /hud/ data further reinforce the idea of ‘separate articulatory goals’ for vowels in different contexts. • For /u/ in /bud/, NF2 values remains the same across speech rates. This seems to reflect the fact that the onset /b/ and the vowel /u/ share the same articulation and thus the lowest F2 is not affected by the degree of overlapping of adjacent articulations. • The results of this study seem to suggest that language users have many more distinctive sound categories than traditionally assumed. Further, coarticulation may be better understood as categorical phenomena than gradient phenomena. Even if it starts out as gradient effect, by using the same articulatory sequence again and again, language learners might inevitably develop stable categorical sequencial articulatory goals. Mean duration (pooled) Fast: 113.7 ms Medium: 151.6 ms Slow: 215.7 ms Materials and Methods Following Lindblom (1963) and Solé (1992), the question of whether /u/-fronting is phonetic or phonological was investigated by production experiment, where speakers were asked to produce various words and non-words of a /C1VC2/ form in carrier sentences, where the place of C2 was fixed to alveolar and the place of C1 varied among alveolar (e.g. /dud/), bilabial (e.g., /bud/) and ‘no place’ (i.e., /hud/), in slow, medium, and fast speech rate. Data collection: UC Berkeley, Phonology Lab Participants: Native speakers of American English 31 talkers (5 M, 10F; 19-45 yrs old) Carrier Sentence: “That’s a _____ again.” Production List: (each word was repeated 6 times) Reference [hvd] (medium rate) Test [dvd] (fast, slow, medium rate) he’d [i] dude [dud] hid [ɪ] zoos [zuz] head [ɛ] noon [nun] had [æ] toot [tut] hot [ɑ] Seus [sus] (5*3*6=90 tokens) HUD [ʌ] hood [ʊ] Control [cvc] (fast, slow, medium rate) who’d [u] (8*6=48 tokens) booed [bud] who’d [hud] (2*3*6=36 tokens) Total: 174 tokens/speaker elicited (ln) vowel [i] [u] [ɪ] [ʊ] [ɛ] [ʌ] [æ] [ɑ] ln(F1) = 5.89 ln(F2) = 8.02 NF1 = 0.51 NF2 = -0.42 m_ln(F1) = 6.4 m_ln(F2) = 7.6 Bibliography (ln) Hyman, L. (1976). “Phonologization,” In Linguistic studies presented to Joseph H. Greenberg, edited by A. Juilland (Saratoga), pp. 407-418. Lindblom, B., and Studdert-Kennedy, M. (1967). “On the role of formant transitions in vowel recognition,” J. Acoust Soc. Am. 42, 830-843. Nearey, T. (1978). Phonetic Feature Systems for Vowels. Indiana. Indiana University Linguistics Club. Ohala, J. J. (1981). “The listener as a source of sound change,” in Papers from Parasession on Language and Behavior, edited by C. S. Masek, R. A. Hendrick, and M. F. Miller (Chicago Linguistic Society, Chicago), pp. 178-203. Solé, M. J. (1992). “Phonetic and phonological processes: the case of nasalization,” Language and Speech 35, 29–43.






















