Download

1 / 36
370 likes | 514 Views
Distributed Programming for Dummies. A Shifting Transformation Technique Carole Delporte-Hallet, Hugues Fauconnier, Rachid Guerraoui, Bastian Pochon. Agenda. Motivation Failure patterns Interactive Consistency problem Transformation algorithm Performance Conclusions. Motivation.

E N D
Distributed Programming for Dummies A Shifting Transformation Technique Carole Delporte-Hallet, Hugues Fauconnier, Rachid Guerraoui, Bastian Pochon
Agenda • Motivation • Failure patterns • Interactive Consistency problem • Transformation algorithm • Performance • Conclusions
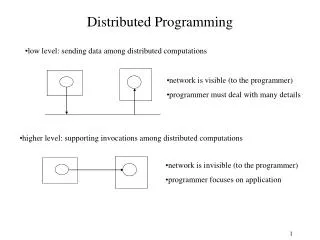
Motivation Distributed programming is not easy
Motivation • Provide programming abstractions • Hide low level detail • Allow working on a strong model • Give weaker models automatically
Models Distributed programming semantics and failure patterns
Processes • We have n distributed processes • All processes are directly linked • Synchronized world • In each round, each process: • Receive an external input value • Send a message to all processes • Receive all messages sent to it • Local computation and state change
PSR • Perfectly Synchronized Round-based model • Processes can only have atomic failures • They are only allowed to crash/stop • They can only crash if they are not in the middle of sending out a message
Crash • Processes can only have crash failures • They are only allowed to crash/stop • They can also crash in the middle of sending out a message A message might be sent only to several other processes upon a crash
Omission • Processes can have crash failures • Processes can have send-omission failures • They can send out a message to only a subset of processes in a given round
General • Processes can have crash failures • Processes can have general-omission failures • They can fail to send or receive a message to or from a subset of processes in a given round
Failure models • PSR(n,t) • Crash(n,t) • Omission(n,t) • General(n,t) We’d like to write protocols for PSR and run them in weaker failure models
Interactive Consistency An agreement algorithm
Interactive Consistency • Synchronous world • We have n processors • Each has a private value • We want all of the “good” processors to know the vector of all values of all the “good” processors • Let’s assume that faulty processors can only lie about their own value (or omit messages)
IC Algorithm A a d b c
IC Algorithm: 1st step B C D a d b c Each client sends “my value is p” message to all clients
IC Algorithm: 2nd step B, B(c), B(d) C, C(b), C(d) D, D(b), D(c) a d b c Each client sends “x told my that y has the value of z; y told me that …”
IC Algorithm: ith step B, B(c), B(d), B(c(d)), … C, C(b), C(d), … D, D(b), D(c) a d b c Each client sends “x told my that y told me that z has the value of q; y told me that …”
IC Algorithm: and faults? • When a processor omits a message, we just assume NIL as his value • Example: • NIL(b(d)) “d said nothing about b’s value”
IC Algorithm: deciding • Looking at all the “rumors” that a knows about the private value of b • We choose the rumor value if a single one exists or NIL otherwise • If b is non-faulty, then we have B or NIL as its results • If b is faulty, then a and c will have the same value for it (single one or NIL result)
IC Algorithm • We need k+1 rounds for k faulty processes • We’re sending out a lot of messages
PSR • Synchronous model • We are not going to do anything with this • Performance • Automatically transforming a protocol from PSR to a weaker model is costly • We are going to deal only with time
Why? • IC costs t+1 rounds • PSR of K rounds costs K(t+1) rounds • Optimizations of IC can do 2 rounds for failure-free runs • Now we get to K rounds in 2K+f rounds for actual f failures • We would like to get K+C rounds
The algorithm • If a process realizes it is faulty in any way – it simulates a crash in PSR • We run IC algorithms in parallel, starting one in each round for each PSR round • There can be several IC algorithms running in parallel at the same time • Each process runs the algorithm of all processes to reconstruct the failure patterns
The algorithm for phase rdo input:= receiveInput() start IC instance r with input execute one round for all pending IC instances for each decided IC do update states, decision vector and failures list modify received message by faulty statuses simulate state transition for all processes
Knowledge algorithm • Each process sends only its input value • The protocol executed on all other processes is known to him • He can execute the protocols of other processes by knowing their input values only
Extension • No knowledge of other processes’ protocols • We now send out both the input and the message we would normally send out • This is done before we really know our own state we are running several rounds in parallel
One small problem… • Since we don’t know our state, how can we continue to the next round? • We send out extended set of states • All of the states we might come across in our next few rounds of computation • Compute the future in all of them and optimize as we get more messages
State of the process • Until now, the input values did not depend on the state of the process • For a finite set of inputs, we can again use the same technique for an extended set of inputs
Performance Not real…
Number of rounds • We need K+f phases • Result for the first IC round takes f+2 phases • All of our rounds are at a 1-phase interval
Size of messages • For the simple algorithm suggested: • nlog2|Input| per process, per round, per IC • nlog2|Input| per process, per phase - the number of phases needed to decide an IC
Size of messages • For the extended transformation: • 2n possible states in a phase • A coded state takes =2log2|State|+(n+1)log2|Message| • Message size is n2n • Long…
Summary • We showed how to translate PSR into 3 different weaker models • We can try doing the same for the Byzantine model