Download

1 / 94
950 likes | 1.17k Views
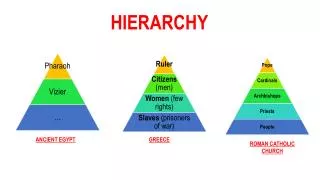
Cache Hierarchy. J. Nelson Amaral University of Alberta. Address Translation (flashback). valid bit = 0 implies a page fault (there is no frame in memory for this page). Baer, p. 62. Should the Cache be Accessed with Physical or Virtual Addresses?. Baer, p. 209. Instruction Cache.

E N D
Cache Hierarchy J. Nelson Amaral University of Alberta
Address Translation(flashback) valid bit = 0 implies a page fault (there is no frame in memory for this page) Baer, p. 62
Should the Cache be Accessed with Physical or Virtual Addresses? Baer, p. 209
Instruction Cache • Instructions are fetched either: • sequentially (same cache line) • with address form a branch target buffer (BTB) • BTB contains physical addresses • When needed, translation is: • done in parallel with delivery of previous instruction • Thus Instruction Cache can be physical Baer, p. 209
For a 2k page size, the last k bits are identical in the virtual and physical addresses. Data Cache Index Physical Virtual Tags Tags Physical Physical Virtual If the cache index fits within these k bits, then these two schemes are identical. Baer, p. 209
Parallel TLB and Cache Access Page size = 2k Only works if index + displ. ≤ k Baer, p. 210
Pipeline Stages Saves a pipeline stage when there is a hit in the TLB and cache. Stage 2: If Tag in TLB ≠ Tag in TLB: - Void Data in Register - Start Replay Stage 1: Send Data to Register Baer, p. 210
Page Sizes are typically 4KB or 8KB. An 8KB L1 cache is too small. Increase cache associativity. Two solutions: Increase the number of bits that are not translated. Baer, p. 210
Limits on Associativity Time to do the tag comparisons Solution: Do comparisons in parallel Still need time for latches/multiplexors Solution: Don’t compare with all tags. How? Use a set predictor. For L1 predictor must be fast. Baer, p. 210
Page Coloring • Goal: increase number of non-translated bits • Idea: Restrict mapping of pages into frames • Divide both pages and frames into colors. • A page must map to a frame of the same color. • For l additional non-translated bits needs 2l colors. Restrict mapping between virtual and physical addresses • Alternative to coloring: • Use a predictor for the l bits. Baer, p. 211
Virtual Cache • Virtual index and virtual tags allow for fast access to cache. • However… • Page protection and recency-of-use information (stored in TLB) must be accessed. • TLB must be accessed anyway • TLB access can be in parallel with cache access • Context switches activate new virtual address space • Entire cache content becomes stale. Either: • flush the cache • append a PID to tag in cache • must flush part of cache when recycling PIDs • Synonym Problem Baer, p. 211
Synonym Problem Virtual Address A Physical Address 1 Virtual Address B Occurs when data is shared among processes What happens in a virtual cache if two synonyms are cached simultaneously, and one of them is modified? The other becomes inconsistent! Baer, p. 211
Avoiding Stale Synonyms • Variation on Page Coloring: Require that the bits used to index the cache be the same for all synonyms • Software must be aware about potential synonyms • Easier for instruction caches • Tricky for data caches • Sun UltraSPARC has virtual instruction cache. Baer, p. 212
Example • Page size is 4 Kbytes • How many bits for page number and page offset? • 20 bits for page number and 12 bits for page offset • Direct-mapped D-Cache has 16 bytes per lines, 512 lines: • How many bits for tag, index, and displacement? • 16x512 = 8192 bytes = 213 bytes • displacement = 4 bits • index = 13-4 = 9 bits • tag = 32-13 = 19 bits Lowest bit of page number is part of the index. Baer, p. 212
Page Number Page Offset 28 24 20 16 12 8 4 0 Cache Tag Cache Index Cache Displ. Process A Physical Pages Page 4 Page 14 Process B Page 17 Baer, p. 212
Process A reads line 8 of its page 4 (line 8 physical page 14): Page Number Page Number Page Offset Page Offset Process B reads line 8 of its page 17 (line 8 of physical page 14): 12 20 16 20 16 12 28 24 28 24 4 0 8 8 4 0 Cache Displac. Cache Displac. Cache Tag Cache Tag Cache Index Cache Index 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Baer, p. 212
Process A reads line 8 of its page 4 (line 8 physical page 14): Page Number Page Number Page Offset Page Offset Process B reads line 8 of its page 17 (line 8 of physical page 14): 12 20 16 12 20 16 28 24 24 28 8 0 4 4 0 8 Cache Displac. Cache Displac. Cache Tag Cache Tag Cache Index Cache Index 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Now processor B writes to its cache line 8. Baer, p. 212
Process A reads line 8 of its page 4 (line 8 physical page 14): We have a synonym problem: two copies of the same physical line in the cache, and they are inconsistent. Page Number Page Number Page Offset Page Offset Process B reads line 8 of its page 17 (line 8 of physical page 14): How can we avoid the synonym? 16 12 20 16 20 12 28 24 28 24 4 8 4 0 0 8 Cache Displac. Cache Displac. Cache Tag Cache Tag Cache Index Cache Index 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Now processor B writes to its cache line 8. Baer, p. 212
Checks on a cache miss: • check virtual tags to ensure that there is a miss (this would be in the tag at line 264) (ii) compare the physical page number of the missing item (page 14 in the example) with the physical tag(s) of all other locations in the cache that could be potential synonyms (physical page number for virtual tag of line 8 in the example). Baer, p. 212
Other drawbacks of Virtual Caches I/O addresses are physical. Cache coherency in multiprocessors use physical addresses. Virtual caches are not currently used in practice. Baer, p. 212
Virtual Index and Physical Tags Idea: limit mapping in a similar way to page coloring but apply it only to the cache. Example: Consider an m-way set associative cache with capacity m x 2k. Constraint: Each line in a set has a pattern of l bits that is different from all other lines. The pattern should be above the lower k bits, and l < m. Baer, p. 212
Virtual Index and Physical Tags (Cont.) On an access: Set: determined by k untranslated bits. Use a prediction for the m patterns of the l virtual bits. If the prediction does not match the full match in the TLB, need to repeat access. Drawback: lines mapped to the same set with the same l-bit pattern cannot be in the cache simultaneously. Baer, p. 212
“Faking” Associativity Column-associative Caches: Treat a direct-mapped cache as two independent halves. First Access: Access the cache using the usual index. Second Access: If a miss occurs, rehash the address and perform a second access to a different line. Swap: If the second access is a hit, swap the entries for the first and second accesses. Baer, p. 213
Column-Associative Cache Assume that the high order bit of a makes it first to be looked at Half 1. Processor Memory &a a a … c Cache … Half 2 Half 1 b a
Column-Associative Cache Assume that the high order bit of b makes it first to be looked at Half 1. Processor Memory &b a a … c Cache … Half 2 Half 1 b b a b
Column-Associative Cache Assume that c’s high order bit is the opposite of a and b. Processor Memory &c a a … Cache Thus, look for c on Half 2 first. … Half 2 Half 1 b b a b c c c
Column-Associative Cache Processor Memory &b a a … Cache … Half 2 Half 1 b b c b a c c
Column-Associative Cache Processor Memory &c a a … Cache … Half 2 Half 1 b b a b c c c
Column-Associative Cache Processor Memory &b a a … Cache … Half 2 Half 1 b b c b a c c
Thus the sequence abcbcbcbcbc…. results in a miss in every access. The same sequence would result in close to 100% hit rate in a 2-way associative cache. Solution: add a rehash bit that indicates that the entry is not in its original location If there is a miss on first access and rehash is on, there will be also a miss on the second access. The entry with rehash bit on is the LRU and should be evicted. Baer, p. 214
Operation of Column-Assoc. Cache tag(index) = tag_ref? It is a hit. Serve entry to processor. yes no rehash_bit(index) on It is a miss. Enter: off rehash bit index1 ← flip_high_bit(index) It is a secondary hit. swap[entry(index),entry(index1)] rehash_bit(index1) ← 1 Serve entry to processor tag(index1) = tag_ref? yes no tag_ref 0 data tag_ref 1 data index index It is a secondary miss. Enter: swap[entry(index),entry(index1)] rehash_bit(index1) ← 1 Baer, p. 214
Performance of Column-Associative Caches (CAC) • Comparing CAC with Direct-Mapped Cache (DMC) of same capacity: • Miss ratio(CAC) < Miss ratio(DMC) • Access to second half(CAC) > Access(DMC) • Comparing with a Two-Way Set Associative Cache (2SAC) of same capacity: • miss ratio(CAC) approaches miss ratio(2SAC) Baer, p. 215
Design Question When should a column-associative cache be chosen over a 2-way set associative cache? When the 2-way set associative cache requires the processor clock to be longer. Baer, p. 215
Design Question #2 Can a column-associative cache be expanded to higher associativity? How? Have to replace the hashing function. The single-bit hashing does not work. Could use some XOR combination of PC bits. Baer, p. 215
Victim Caches Baer, p. 215
Operation of Victim Cache tag(index) = tag_ref? It is a hit. Serve entry to processor. yes swap(victim, VC[i]) Update VC LRU information Serve entry to processor Tag(VC[i]) = VCTag yes no Let VC(j) be the LRU entry in VC no VCTag = concat[index,tag(index)] Assoc. search victim cache for VCtag yes VC(j) dirty? Writeback(VC[j]) no VC[j] ← victim Baer, p. 216
History: First Victim Cache HP 7100, introduced in 1992 HP 7200, introduced in 1995 64-entry victim cache 120 MHz clock Baer, p. 216
Code Reordering • Procedure reordering • Basic Block Reordering Baer, p. 217
Data Reordering • Cache-conscious algorithms • Pool allocation • Structure reorganization • Loop tiling (cache tiling?) Baer, p. 218
Hiding Memory Latencies • Prefetching • Software instructions • Hardware assisted • Hardware only (stream prefetching) • Between any two levels of memory hierarchy • Prefetching is predictive, can we use the same predictor modeling as for branches? Baer, p. 218
Prefetching Prediction × Branch Prediction Baer, p. 219
Assessment Criteria for Prefetching Timeliness: • too early: displaces useful data that have to be reloaded before prefetched data is needed • too late: data is not there when needed Baer, p. 219
Prefetching • Why? • What? • When? • Where? To hide memory latency by increasing hit ratio. Ideally semantic objects. In practice cache lines. In a timely manner when a trigger happens. A given cache level or a special prefetch storage buffer. Baer, p. 219
Disadvantages of Prefetching • Compete for resources with regular memory operations • P.e., might need an extra port in cache to check tags before prefetching • Competition for memory bus with regular loads and stores Baer, p. 220
Software Prefetching • Non-binding loads: a load that does not write to a register • More sophisticated instructions: designate the level in the cache hierarchy where prefetched line should stop (Itanium) Baer, p. 220
Software Prefetching Example for (i=0 ; i<n ; i++) inner = inner + a[i]*b[i]; What is the drawback now? Code with Prefetching: for (i=0 ; i<n ; i++){ prefetch (&a[i+1]); prefetch(&b[i+1]); inner = inner + a[i]*b[i]; } Each prefetch instruction brings an entire cache line. Same line is fetched several times. May cause an exception on the last iteration. Baer, p. 221
Software Prefetching Example for (i=0 ; i<n ; i++) inner = inner + a[i]*b[i]; What is the drawback now? Prefetching with Predicate: for (i=0 ; i<n ; i++){ if (i ≠ n-1 and i mod 4 = 0){ prefetch (&a[i+1]); prefetch(&b[i+1]); } inner = inner + a[i]*b[i]; } This branch is not easy to predict correctly. Baer, p. 221
Software Prefetching Example for (i=0 ; i<n ; i++) inner = inner + a[i]*b[i]; With Loop Unrolling: Issues: - register pressure - code growth prefetch(&a[0]); prefetch(&b[0]); for (i=0 ; i<n-4 ; i += 4){ prefetch (&a[i+4]); prefetch(&b[i+4]); inner = inner + a[i]*b[i]; inner = inner + a[i+1]*b[i+!]; inner = inner + a[i+2]*b[i+2]; inner = inner + a[i+3]*b[i+3]; } for ( ; i<n ; i++) inner = inner + a[i]*b[i]; Baer, p. 221
Sequential Prefetching • or one-block lookahead (OBL) prefetching: • prefetch the next cache line • makes the line size look larger • Strategies • always-prefetch: high coverage, low accuracy • prefetch-on-miss: good for I-caches • tagged-prefetching: good for D-caches • one-bit tag in the cache indicates if next line should be prefetched • when line is prefetched: tag ← 0 • when line is referenced: tag ← 1 Baer, p. 222
One-Block Ahead Prefetching Problem: Timeliness of OBL is usually poor (it is too late). Solution: Prefetch multiple lines ahead. accuracy can be low. Number of lines ahead cold be adaptive on previous success (a predictor!). unreliable feedback: timeless of feedback information is also poor. Baer, p. 222