Download

1 / 68
680 likes | 827 Views
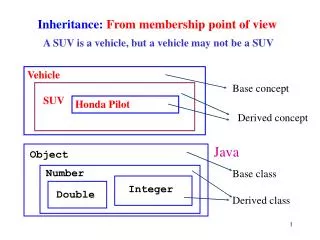
Phonology from a computational point of view. Phonemes, dialects, letter-to-sound conversion March 2001. Phonology:. The study of the sound patterns of languages. We will extend this to include the letter patterns of languages. Syntax. Information Retrieval. Morphology catch + PAST.

E N D
Phonology from a computational point of view Phonemes, dialects, letter-to-sound conversion March 2001
Phonology: The study of the sound patterns of languages. We will extend this to include the letter patterns of languages.
Syntax Information Retrieval Morphology catch + PAST Spelling caught Phonemic representation K AO1 T Sound
Why study phonology in this course? Text to speech (TTS) applications include a component which converts spelled words to sequences of phonemes ( = sound representations). E.g., sightS AY1 T John J AA1 N
Keep separate: • Spelling ( = “orthography”) • Detailed description of pronunciation • Abstract description of pronunciation called “phonemic representation”
Agenda: • Phonology: set of phonemes; their realizations as phones; • The phonemes are reasonably constant across a language. • The phones vary a lot within a speaker and across speakers. • Some of that variation is extremely rule-governed and must be understood: example, English “flap” (in butter).
In addition to the phonemes: syllable structure, and • Prosody. Today: stress levels: 0,1,2 • Text’s discussion of spelling errors, as a lead-in to Viterbi-ing the Minimum Edit Distance • Letter to sound (LTS)
All speakers have a set of several dozen basic pronunciation units (“phonemes”) to which they do not add (or from which delete) during their adult lifetimes. 39 phonemes in American English. • This phonemic inventory is not completely fixed and stable across the United States, but it is much more fixed and stable than is the pronunciation of these phonemes.
How is that possible? • I’m from New York; the vowel that I have in cat is very different from the vowel in a south Chicago native’s cat – but the phonemes are the same – they correspond across thousands of words.
Phonemic inventory • In computational circles, phonemic inventory described in DARPAbet: • Some words from the CMU dictionary THE DH AH0 THE(2) DH AH1 THE(3) DH IY0 THEA TH IY1 AH0 THEALL TH IY1 L THEANO TH IY1 N OW0 THEATER TH IY1 AH0 T ER0
Darpabet • AA odd AA D • AE at AE T • AH hut HH AH T • AO ought AO T • AW cow K AW • AY hide HH AY D
AA odd AA D AE at AE T AH hut HH AH T AO ought AO T AW cow K AW AY hide HH AY D EH Ed EH D ER hurt HH ER T EY ate EY T IH it IH T IY eat IY T OW oat OW T OY toy T OY UH hood HH UH D UW two T UW 15 Vowels
B be B IY D dee D IY G green G R IY N P pee P IY T tea T IY K key K IY S sea S IY SH she SH IY F fee F IY V vee V IY DH thee DH IY TH theta TH EY T AH Z zee Z IY ZH seizure S IY ZH ER HH he HH IY CH cheese CH IY Z JH gee JH IY L lee L IY M me M IY N knee N IY NG ping P IY NG R read R IY D W we W IY Y yield Y IY L D 24 Consonants
Moby system http://www.dcs.shef.ac.uk/research/ilash/Moby/ • /&/ sounds like the "a" in "dab" • /(@)/ sounds like the "a" in "air" • /A/ sounds like the "a" in "far" • /eI/ sounds like the "a" in "day" • /@/ sounds like the "a" in "ado" • or the glide "e" in "system" (dipthong schwa) • /-/ sounds like the "ir" glide in "tire" • or the "dl" glide in "handle" • or the "den" glide in "sodden" (dipthong little schwa) • /Oi/ sounds like the "oi" in "oil" • /A/ sounds like the "o" in "bob" • /AU/ sounds like the "ow" in "how" • /O/ sounds like the "o" in "dog"
Some sources of dictionaries,including CMU’s ftp://svr-ftp.eng.cam.ac.uk/pub/pub/pub/comp.speech/dictionaries
The tremendous variety of actual pronunciations that native speakers can blissfully ignore is staggering But speech recognition systems need to be trained on this, just as people are in their youth.
Varieties of sounds in everyone’s speech Most phonemes have several different pronunciations (called their allophones), determined by nearby sounds, most usually by the following sound. The most striking instance of such variation is in the realization of the phoneme /T/ in American English.
The syllable S rhyme onset coda nucleus h e l p
Flap (D) in American English • We find the flap of water (wa[D]er) under these conditions strictly inside a word:
But across words: • Word initial t never flaps, regardless of stresses before or after*; eat my tomato, see Topeka... • Word-final t followed by a vowel-initial wordnormally does flap, regardless of stresses before or after. at all, sit on it... *But in the words to, tonight, today, tomorrow, the toacts as if it were linked to the preceding word. “go [D]o bed”
Generalization • English permits phonemes to belong simultaneously to two syllables ( = be ambisyllabic) under certain conditions. • Ambisyllabic t's convert to flaps. Generally speaking:
s s onset rhyme onset rhyme B UH1 T ER This is where we get a flap in American English
Within a word: • C becomes part of syllable with a following onset ("maximize syllable onset"):
...within a word: s C V
This also applies across words --in English, and in many languages, but not (e.g.) in German s C V [ #
Within a word, ambisyllabification before an unstressed vowel e.g., atom s s V C V -stress +stress
But not across word boundaries we don't say my tomato my [D]omato
/T/ as flap at word-edge If a word ends in a /t/ and the next word starts with a vowel, flap is normal: at [D] all, What [D] is your name?, etc. If a word ends in a vowel and the next word starts with a vowel, never a flap – unless the second word starts with the prefix to- ! the [t] tomato, the [t] topology of… but go [D] to the moon, go [D] tomorrow…
Most computational devices avoid worrying about these issues… by (always) treating phonemes in the context of their left- and right-hand neighbors. Need to produce an AE? Find out what neighbors it needs to be produced next to. H AE T? Find an AE that was produced after an H and before a T.
Variation in pronunciation islargely geographical, but it is also related to class, race, and gender William Labov is the master analyst of this material, and many papers are available at his web site: http://www.ling.upenn.edu/~labov/home.html See especially his http://www.ling.upenn.edu/phono_atlas/ICSLP4.html …Dialect Diversity in North America
Ongoing changes in American English pronunciation 1. Loss of difference between AA (cot) and AO (caught). See also hot dog (h AA t d AO g). Some speakers produce these vowels differently (I do). Others do not. Labov’s group has produced the following map:
Distinction between vowels IH and EH before n ink-pen versus baby-pin: distinction lost in the South.
Variation in AE phoneme (“hat”) A very wide range of American speakers do NOT have the same vowels in sand and sang. The vowels in cat and sang are the same, but in sand the vowel is much higher. However, in the Northern Cities shift, all AE is pronounced like the last two syllables of idea – this is prevalent right here in the south Chicago area.
Sound – Letter relationships LTS: Letter to sound, or Phoneme-Grapheme relationships. In most languages, this is simple. But in English and in French, it’s very messy. Why? Because the spelling system in both is based on how the language usedto be pronounced, and the pronunciation has since changed.
Other languages In most other languages, spelling reflects current pronunciation much more accurately. Stress: most languages don’t mark which syllable is stressed. In some languages, there are simple principles that tell us which syllable is stressed, but when there are no such principles (e.g. English, Russian), then you need to build word-lists with the stressed indicated.
Letter to sound for English • Letter >> phoneme for speech synthesis • Phoneme >> letter for speech recognition
Challenges to Letter-to-Sound There are always new words being found, and most of them are new proper names (people, places, products, companies, etc.)
Damper, Marchand, Adamson and Gustafson 1998: Testing Letter to Sound Third ESCA/COCOSDA Workshop on SPEECH SYNTHESIS November 1998 They contest Liberman and Church’s statement in 1991: “We will describe algorithms for pronunciation of English words…that reduce the error rate to only a few tenths of a percent for ordinary text, about two orders of magnitude better than the word error rates of 15% or so that were common a decade ago.” They write, “In this paper, we have shown that automatic pronunciation of novel words is not a solved problem in TTS synthesis. The best that can be done is about 70% words correct using PbA [Pronunciation by Analogy]…traditional rules…perform very badly – much worse than pronunciation by analogy and other data-driven approaches….”
Damper et al. Compare 4 approaches: • Hand-written phonological rules • Pronunciation by analogy (based on Dedina and Nusbaum 1991) • Neural networks (based on Sejnowski and Rosenberg’s NETtalk) • Information theory-based approach (“Nearest neighbor”)
How to evaluate LTS? Systems typically use • a large dictionary • a set of “exceptional words” • a backoff strategy for words that slip through the first 2 steps. Is it fair to test the backoff strategy on words in the first two sets, then?
Damper et al propose: • Test on a single, entire, large dictionary; • Strict scoring, not frequency-weighted, giving credit only for full-word correct; • A standardized phoneme output set should be employed
Evaluation • In reality, different descriptions of English use different sets of phonemes (e.g., is stress marked on the vowels? British versus American) • Issues in testing data-driven methods, because the performance of a data-driven method is tightly linked to the data it was trained on.
Data-driven method Data Learning method Letter-to-sound conversion system
In theory, you should never test a data-driven method on data that it was trained on…. • In theory, if you want to test the performance of the method on the whole dictionary, you can train the system on the whole dictionary less one word, and then test it on that word; and do all of that each time for each word. • But that takes too long! and we’re also interested in the relationship between training corpus size and total performance.
Damper et al’s work-around • For various values of N (up to half the size of the dictionary): • Take two random samples of the dictionary, each of size N. Train on one set, test on the other. • N = 100, 500, 1000, 2000, 5000 and 8,140. • Dictionary is of size 16,280.