Download
1 / 54
610 likes | 1.36k Views
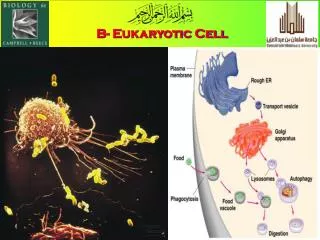
EUKARYOTIC CELL SEEN UNDER LIGHT MICROSCOPE. EUKARYOTIC CELL SEEN UNDER ELECTRON MICROSCOPE. Organelle Stains. 3,3'-dihexyloxacarbocyanine iodide, DiOC6. Endoplasmic Reticulum. Cells and macromolecules. Protein. RNA. Prokaryotic cell. DNA. Eukaryotic cell. The proteins.

E N D
Organelle Stains 3,3'-dihexyloxacarbocyanine iodide, DiOC6 Endoplasmic Reticulum
Cells and macromolecules Protein RNA Prokaryotic cell DNA Eukaryotic cell
Principles of Protein Structure Primary structure ACDEFGHIKLMNPQRSTVWY α-helix Protein subunit (monomer) domain QUATERNARY STRUCTURE β-sheet SECONDARY STRUCTURE TERTIARY STRUCTURE
The most commonly used method to determine the structure of molecules in three dimensions is X-ray crystallography.
The Nobel Prize in Chemistry 1958 Frederick Sanger for his work on the structure of proteins, especially that of insulin
Edman degradation Phenylisothiocyanate is reacted with an uncharged terminal amino group, under mildly alkaline conditions, to form a cyclical phenylthiocarbamoyl derivative. under acidic conditions, this derivative of the terminal amino acid is cleaved as a thiazolinone derivative. The thiazolinone amino acid is then selectively extracted into an organic solvent and treated with acid to form the more stable phenylthiohydantoin (PTH)- amino acid derivative that can be identified by using chromatography or electrophoresis. This procedure can then be repeated again to identify the next amino acid.
Landmarks in the development of biology using Insuline Insulin was the first protein to be sequenced. First to be chemically synthesized. Insulin was involved in the initiation of macromolecular crystallographic studies. In fact, it was the second protein to be subjected to preliminary X-ray crystallographic studies. Pepsin was the first.
Dorothy took up the X-ray analysis of insulin as the first problem in her independent research career. Bovine insulin was crystallized by Abel way back in 1926 . The method of crystallization in the presence of salts of zinc and other metals, was standardized by Scott in 1934.
X-ray crystallography Is a method of determining the arrangement of atoms within a crystal, in which a beam of X-rays strikes a crystal and diffracts into many specific directions. From the angles and intensities of these diffracted beams, a three-dimensional picture of the density of electrons within the crystal . From this electron density, the mean positions of the atoms in the crystal can be determined, as well as their chemical bonds, their disorder and various other information.
X-ray crystallography, the hexagonal symmetry of snowflakes results from the tetrahedral arrangement of hydrogen bonds about each water molecule. The water molecules are arranged similarly to the silicon atoms in the tridymite polymorph of SiO2. The resulting crystal structure has hexagonal symmetry when viewed along a principal axis.
X-ray crystallography shows the arrangement of water molecules in ice, revealing the hydrogen bonds that hold the solid together.
Amino acids • Collagen has an unusual amino acid composition and sequence: • Glycine (Gly) is found at almost every third residue • Proline (Pro) makes up about 9% of collagen • Collagen contains two uncommon derivative amino acid • Hydroxyproline (Hyp), derived from proline. • Hydroxylysine (Hyl), derived from lysine (Lys). Collagen
The three-dimensional structure of penicillin, for which Dorothy Crowfoot Hodgkin was awarded the Nobel Prize in Chemistry in 1964. The green, white, red, yellow and blue spheres represent atoms of carbon, hydrogen, oxygen, sulfur and nitrogen, respectively.
X-ray crystallography of biological molecules took off with Dorothy Crowfoot Hodgkin. Solved the structures of : cholesterol (1937), vitamin B12 (1945) Penicillin (1954). was awarded the Nobel Prize in Chemistry in 1964. In 1969, she succeeded in solving the structure of insulin, on which she worked for over thirty years
Unveiling the sequence Before Fred's work, it was already known that different proteins had different amino acid compositions, different biological activities, and different physical properties and that genes had an important role in controlling them. It was not at all clear how molecules as large as proteins could be synthesized; the idea that proteins were stochastic molecules, with a sort of "center of gravity" of structure but with appreciable microheterogeneity, was taken seriously. This is the paradigm that Fred's results shifted.
N-terminal sequences of insulin One of the main reasons Sanger chose insulin for this work is that it was one of the few proteins available in pure form, and was available in gram quantities because of its medical importance.
Fred invented the N-terminal labeling method using 1:2:4 fluorodinitrobenzene (FDNB) It which reacts with amino groups under mild conditions that avoid degradation of the polypeptide chain. After complete acid hydrolysis of the dinitrophenyl (DNP)-protein, the DNP groups remain attached to the N-terminal amino acid and can be isolated and identified.
Fred showed that there were four N-terminal residues per 12K insulin molecule. • two of which were glycine and two phenylalanine suggesting that there were four polypeptide chains in the 12K molecule. • Cysteine was present, so it was thought that the chains were held together by -S-S- bridges. • After performic acid oxidation, which splits the -S-S- bridges, insulin could be fractionated by precipitation into an A fraction and a B fraction. • the A fraction had N-terminal glycine, and the B fraction had phenylalanine. • The two fractions had different amino acid compositions, and neither contained tryptophan. • Later it became clear that the 12K molecule is a noncovalent dimer of the fundamental molecular unit, comprising one A chain and one B chain.
The lack of tryptophan was fortunate, because it degrades upon acid hydrolysis, and one of the most important methods Fred used to get at the structure of insulin, with great success, was partial acid hydrolysis, which splits the peptide bonds almost randomly. • In fact, the first amino acid sequences of insulin came from partial acid hydrolysis of DNP-labeled A and B fractions. Some DNP peptides can be extracted into ethyl acetate from acid solution and then separated by silica gel columns; since DNP compounds are usually yellow, this was real "chroma"-tography. • For the B fraction, these peptides turned out to be the DNP-labeled N-terminal Phe followed by one or more other amino acids. Fred identified the DNP-amino acid and the other amino acids in the peptide after complete acid hydrolysis and then assembled the N-terminal sequence Phe.Val.Asp.Glu. • Among the peptides that contained Asp or Glu, several different peptides had the same amino acid composition, so he concluded that both Asp and Glu were amidated in the original sequence.
Other DNP peptides were not extracted into ethyl acetate. • They were peptides derived from internal sequences surrounding Lys, to which DNP was linked by the amino group on the side chain. Since they all had free N-terminal amino groups (liberated from internal peptide bonds by partial acid hydrolysis), they were positively charged in acid, which explains why they did not extract into organic solvents. • Amino acid analysis and relabeling with FDNB to determine the end groups gave the internal sequence Thr.Pro.Lys.Ala. The A fraction yielded the N-terminal sequence Gly.Ileu.Val.Glu.Glu. • This article (SANGER 1949 ) was pivotal—it showed for the first time that at least some of the amino acids were in a unique sequence in insulin. • Furthermore, the A and B fractions each yielded a unique sequence, suggesting that there were only two, not four, species of peptide chain in insulin. • an A chain that contained about 20 amino acids • B chain with about 30 amino • This article showed that it should be possible in principle to determine the whole structure of each chain simply by extending the methods developed in this article—partial hydrolysis, fractionation of the products, end group analysis, and further partial hydrolysis of the longer products.
Sanger's method of peptide end-group analysis: A derivatization of N-terminal end with sanger’s reagent (DNFB), B total acid hydrolysis of the dinitrophenyl peptide
The complete sequence of the B chain • The B chain was tackled first. • Partial acid hydrolysis of the whole chain yielded many more products to be separated • These relatively crude fractions, which contained between 8 and 25 peptides, were then subjected to two-dimensional paper chromatography, and the peptides were detected (usually) by lightly staining with ninhydrin. • Finally, they were able to characterize 23 dipeptides, 15 tripeptides, 9 tetrapeptides, 2 pentapeptides, and 1 hexapeptide by amino acid composition and end-group analysis. • The completion of the sequence depended on the use of specific proteases—trypsin, chymotrypsin, and pepsin to produce larger fragments. • The main advantage of protease digestion is that trypsin and chymotrypsin cleave at few sites, but do so relatively completely, so the complexity of the mixture to be separated is low.
Fred's initial approach to sequencing by random cleavage was too difficult for larger proteins, mainly because of the problems of fractionation of complex mixtures. • At the time this work was done, the Edman sequential degradation technique had already been described (EDMAN 1950 ). This method removes amino acids sequentially from the N terminus; it later was the method of choice for the direct sequencing of peptides and proteins and became highly automated and sensitive at the sub-picomole level. In his memoir, Fred says that he did not use it because the products were not colored like the yellow DNP-derivatives, and so fractionations were difficult to follow in the absence of flow spectrophotometers and reliable fraction collectors. • The DNP compounds could be seen as yellow bands moving down the column.
The A chain Two years later, SANGER and THOMPSON 1953 completed the sequence of the A chain, which, although shorter (21 amino acids compared with 30 in the B chain), was technically more difficult. Used partial acid hydrolysis of the whole chain and then protease digestion to give larger blocks.
The -S-S- bonds The A chain and B chain by themselves are physiologically inactive. Sanger and his colleagues Ryle, Smith, and Kitai went on to finish another functionally very important piece of covalent chemistry: the three disulfide bonds in the unoxidized molecule. They discovered that adding thiol blocking reagents like N-ethylmaleimide prevented the exchange under the slightly alkaline conditions used for digestion with pancreatic proteases. One of the interchain disulfide bonds was easily identified, but the A chain includes two adjacent cysteines, and they found no protease that could cleave the peptide bond between them.
Major landmarks in DNA sequencing • 1953 Discovery of the structure of the DNA double helix. • 1972 Development of recombinant DNA technology. • 1974 The first complete DNA genome to be sequenced is that of bacteriophage φX174. • 1977 Allan Maxam and Walter Gilbert publish "DNA sequencing by chemical degradation". • Frederick Sanger, independently, publishes "DNA sequencing by enzymatic synthesis". • 1980 Frederick Sanger and Walter Gilbert receive the Nobel Prize in Chemistry. • 1984 Medical Research Council scientists decipher the complete DNA sequence of the • Epstein- Barr virus . • 1986 Leroy E. Hoods laboratory at the California Institute of Technology and Smith announce the first semi-automated DNA sequencing machine . • 1995 Craig Venter, Hamilton Smith, and colleagues at The Institute for Genomic Research (TIGR) publish the first complete genome of a free-living organism, the bacterium Haemophilus influenzae.
DNA sequencing by the Sanger method The standard DNA sequencing technique is the Sanger method, named for its developer, Frederick Sanger, who shared the 1980 Nobel Prize in Chemistry. This method begins with the use of special enzymes to synthesize fragments of DNA that terminate when a selected base appears in the stretch of DNA being sequenced. These fragments are then sorted according to size by placing them in a slab of polymeric gel and applying an electric field -- a technique called electrophoresis. Because of DNA's negative charge, the fragments move across the gel toward the positive electrode. The shorter the fragment, the faster it moves. Typically, each of the terminating bases within the collection of fragments is tagged with a radioactive probe for identification.
DNA sequencing example Given DNA template: 5'-atgaccatgattacg...-3' DNA synthesized: 3'-tactggtactaatgc...-5' Gel pattern: +-------------------------+ lane ddATP | W | | || | lane ddTTP | W | | | | | | lane ddCTP | W | | | | lane ddGTP | W || | | +-------------------------+ Electric Field + Decreasing size where "W" indicates the well position, and "|" denotes the DNA bands on the sequencing gel.
A sequencing gel . The dark color of the lines is proportional to the radioactivity from 32P labeled adenonsine in the transcribed DNA sample.
Translating the DNA sequence The order of amino acids in any protein is specificed by the order of nucleotide bases in the DNA. Each amino acid is coded by the particular sequence of three bases. To convert a DNA sequence First, find the starting codon. The starting codon is always the codon for the amino acid methionine. This codon is AUG in the RNA (or ATG in the DNA): GCGCGGGUCCGGGCAUGAAGCUGGGCCGGGCCGUGC.... Met In this particular example the next codon is AAG. The first base (5'end) is A, so that selects the 3rd major row of the table. The second base (middle base) is A, so that selects the 3rd column of the table. The last base of the codon is G, selecting the last line in the block of four.
Automated procedure for DNA sequencing A computer read-out of the gel generates a “false color” image where each color corresponds to a base. Then the intensities are translated into peaks that represent the sequence.
High-throughput seqeuncing:Capillary electrophoresis The human genome project has spurred an effort to develop faster, higher throughput, and less expensive technologies for DNA sequencing. Capillary electrophoresis (CE) separation has many advantages over slab gel separations. CE separations are faster and are capable of producing greater resolution. CE instruments can use tens and even hundreds of capillaries simultaneously. The figure show a simple CE setup where the fluorescently-labeled DNA is detected as it exits the capillary. Sheath flow Laser Focusing lens Sheath flow cuvette Beam block Collection Lensc Collection Lensc PMT filter
Sieving matrix for CE It is not easy to analyze DNA in capillaries filled only with buffer. That is because DNA fragments of different lengths have the same charge to mass ratio. To separate DNA fragments of different sizes the capillary needs to be filled with sieving matrix, such as linear polyacrylamide (acrylamide polymerized without bis-acrylamide).This material is not rigid like a cross- linked gel but looks much like glycerol. With a little bit of effort it can be pumped in and out of the capillaries. To simulate the separation characteristics of an agarose gel one can use hydroxyethylcellulose. It is not much more viscous then water and can easily be pumped into the capilliaries.