Download

1 / 9
90 likes | 279 Views
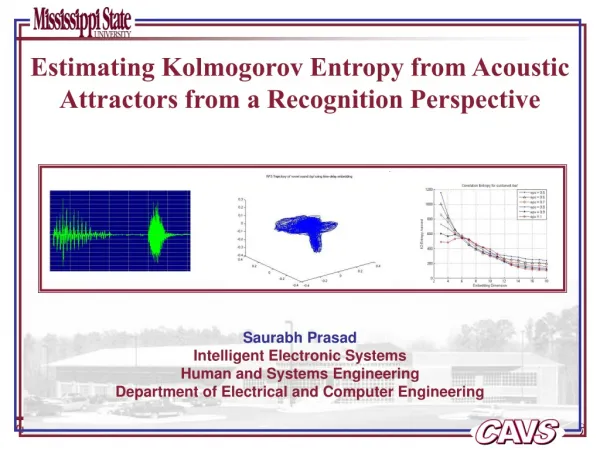
Second Order Kolmogorov Entropy Estimation of speech data – The setup. Speech data, sampled at 22.5 KHz Sustained Phones (/aa/, /ae/, /eh/, /sh/, /z/, /f/, /m/, /n/) Short (single utterance) phones (/aa/, /ae/, /eh/, /sh/, /z/, /f/, /m/, /n/) CVC words (bat, beat, boat, boy)

E N D
Second Order Kolmogorov Entropy Estimation of speech data – The setup • Speech data, sampled at 22.5 KHz • Sustained Phones (/aa/, /ae/, /eh/, /sh/, /z/, /f/, /m/, /n/) • Short (single utterance) phones (/aa/, /ae/, /eh/, /sh/, /z/, /f/, /m/, /n/) • CVC words (bat, beat, boat, boy) • Output – Second order Kolmogorov Entropy • Using these, we wish to analyze: • The presence or absence of chaos in any time series. • Their discrimination characteristics across different attractors for classification
The analysis setup • Currently, this analysis includes estimates of K2 for different embedding dimensions • Variation in entropy estimates with the neighborhood radius, epsilon was studied • Variation in entropy estimates with SNR of the signal was studied • Currently, the analysis was performed on 3 vowels, 2 nasals and 2 fricatives • Results show that vowels and nasals have a much smaller entropy, as compared to fricatives • Further, k2 consistently decreases with embedding dimension for vowles and nasals, while for fricatives, it consistently increases
The analysis setup (in progress / coming soon)… • Data size (length of the time series): • This is crucial for our purpose, since we wish to extract information from short time series (sample data from utterances). • Speaker variation: • We wish to study variations in the Kolmogorov entropy of phone or word level attractors • across different speakers. • across different phones/words • across different broad phone classes
Correlation Entropy vs. Embedding Dimension – various epsilons
Correlation Entropy vs. Embedding Dimension – various epsilons
Correlation Entropy vs. Embedding Dimension – various epsilons