Download

1 / 60
600 likes | 700 Views
Gene Expression Arrays. EPP 245 Statistical Analysis of Laboratory Data. Basic Design of Expression Arrays. For each gene that is a target for the array, we have a known DNA sequence.

E N D
Gene Expression Arrays EPP 245 Statistical Analysis of Laboratory Data
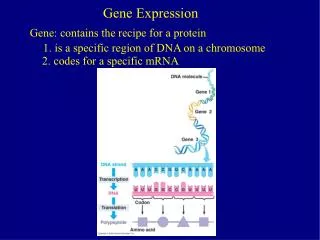
Basic Design of Expression Arrays • For each gene that is a target for the array, we have a known DNA sequence. • mRNA is reverse transcribed to DNA, and if a complementary sequence is on the on a chip, the DNA will be more likely to stick • The DNA is labeled with a dye that will fluoresce and generate a signal that is monotonic in the amount in the sample EPP 245 Statistical Analysis of Laboratory Data
Intron Exon TAAATCGATACGCATTAGTTCGACCTATCGAAGACCCAACACGGATTCGATACGTTAATATGACTACCTGCGCAACCCTAACGTCCATGTATCTAATACG ATTTAGCTATGCGTAATCAAGCTGGATAGCTTCTGGGTTGTGCCTAAGCTATGCAATTATACTGATGGACGCGTTGGGATTGCAGGTACATAGATTATGC Probe Sequence • cDNA arrays use variable length probes derived from expressed sequence tags • Spotted and almost always used with two color methods • Can be used in species with an unsequenced genome • Long oligoarrays use 60-70mers • Agilent two-color arrays • Spotted arrays from UC Davis or elsewhere • Usually use computationally derived probes but can use probes from sequenced EST’s EPP 245 Statistical Analysis of Laboratory Data
Affymetrix GeneChips use multiple 25-mers • For each gene, one or more sets of 8-20 distinct probes • May overlap • May cover more than one exon • Affymetrix chips also use mismatch (MM) probes that have the same sequence as perfect match probes except for the middle base which is changed to inhibitbinding. • This is supposed to act as a control, but often instead binds to another mRNA species, so many analysts do not use them EPP 245 Statistical Analysis of Laboratory Data
Probe Design • A good probe sequence should match the chosen gene or exon from a gene and should not match any other gene in the genome. • Melting temperature depends on the GC content and should be similar on all probes on an array since the hybridization must be conducted at a single temperature. EPP 245 Statistical Analysis of Laboratory Data
The affinity of a given piece of DNA for the probe sequence can depend on many things, including secondary and tertiary structure as well as GC content. • This means that the relationship between the concentration of the RNA species in the original sample and the brightness of the spot on the array can be very different for different probes for the same gene. • Thus only comparisons of intensity within the same probe across arrays makes sense. EPP 245 Statistical Analysis of Laboratory Data
Affymetrix GeneChips • For each probe set, there are 8-20 perfect match (PM) probes which may overlap or not and which target the same gene • There are also mismatch (MM) probes which are supposed to serve as a control, but do so rather badly • Most of us ignore the MM probes EPP 245 Statistical Analysis of Laboratory Data
Expression Indices • A key issue with Affymetrix chips is how to summarize the multiple data values on a chip for each probe set (aka gene). • There have been a large number of suggested methods. • Generally, the worst ones are those from Affy, by a long way; worse means less able to detect real differences EPP 245 Statistical Analysis of Laboratory Data
Usable Methods • Li and Wong’s dCHIP and follow on work is demonstrably better than MAS 4.0 and MAS 5.0, but not as good as RMA and GLA • ArrayAssist can use dCHIP, RMA, gcRMA, and others. • The GLA method (Durbin, Rocke, Zhou) can be imported into ArrayAssist. EPP 245 Statistical Analysis of Laboratory Data
Steps in Expression Index Construction • Background correction is the process of adjusting the signals so that the zero point is similar on all parts of all arrays. • We like to manage this so that zero signal after background correction corresponds approximately to zero amount of the mRNA species that is the target of the probe set. EPP 245 Statistical Analysis of Laboratory Data
Data transformation is the process of changing the scale of the data so that it is more comparable from high to low. • Common transformations are the logarithm and generalized logarithm • Normalization is the process of adjusting for systematic differences from one array to another. • Normalization may be done before or after transformation, and before or after probe set summarization. EPP 245 Statistical Analysis of Laboratory Data
One may use only the perfect match (PM) probes, or may subtract or otherwise use the mismatch (MM) probes • There are many ways to summarize 20 PM probes and 20 MM probes on 10 arrays (total of 200 numbers) into 10 expression index numbers EPP 245 Statistical Analysis of Laboratory Data
The RMA Method • Background correction that does not make 0 signal correspond to 0 amount • Quantile normalization makes the overall distribution of intensity values across probes the same on each array • Log2 transform • Median polish summary of PM probes EPP 245 Statistical Analysis of Laboratory Data
Analysis by means • Remove Row Means • Remove Column Means • Rows and Columns have mean 0 • Influence of an outlier spreads EPP 245 Statistical Analysis of Laboratory Data
Median Polish • Remove Row Medians • Remove Column Medians • Rows and Columns may not • have median 0 • Outliers contained • May have to be iterated EPP 245 Statistical Analysis of Laboratory Data
Example Probe Set • Using the Affy HG U133 Plus 2.0 GeneChip with 54675 probe sets, from 604258 PM probes. • Four chips derived from human IR exposed skin at 0, 1, 10, and 100 cGy • Probe set number 10067/54675 has Affy ID 200618_at • Gene is LASP1, LIM and SH3 protein 1, LIM protein subfamily, Src homology, actin binding. EPP 245 Statistical Analysis of Laboratory Data
Mean Summarization EPP 245 Statistical Analysis of Laboratory Data
Mean Summarization of the Logs EPP 245 Statistical Analysis of Laboratory Data
The GLA Method • The Glog Average (GLA) method is simpler than the RMA method, though it can require estimation of a parameter • Background correction is intended to make a measured value of zero correspond to a zero quantity in the sample • Transformation uses the glog ~ ln for large values • Normalization via lowess • Summary is a simple average of PM probes EPP 245 Statistical Analysis of Laboratory Data
Probe Sets not Genes • It is unavoidable to refer to a probe set as measuring a “gene”, but nevertheless it can be deceptive • The annotation of a probe set may be based on homology with a gene of possibly known function in a different organism • Only a relatively few probe sets correspond to genes with known function and known structure in the organism being studied EPP 245 Statistical Analysis of Laboratory Data
Two-Color Arrays • Two-color arrays are designed to account for variability in slides and spots by using two samples on each slide, each labeled with a different dye. • If a spot is too large, for example, both signals will be too big, and the difference or ratio will eliminate that source of variability EPP 245 Statistical Analysis of Laboratory Data
Dyes • The most common dye sets are Cy3 (green) and Cy5 (red), which fluoresce at approximately 550 nm and 649 nm respectively (red light ~ 700 nm, green light ~ 550 nm) • The dyes are excited with lasers at 532 nm (Cy3 green) and 635 nm (Cy5 red) • The emissions are read via filters using a CCD device EPP 245 Statistical Analysis of Laboratory Data
File Format • A slide scanned with Axon GenePix produces a file with extension .gpr that contains the results:http://www.axon.com/gn_GenePix_File_Formats.html • This contains 29 rows of headers followed by 43 columns of data (in our example files) • For full analysis one may also need a .gal file that describes the layout of the arrays EPP 245 Statistical Analysis of Laboratory Data
"Block" "Column" "Row" "Name" "ID" "X" "Y" "Dia." "F635 Median" "F635 Mean" "F635 SD" "B635 Median" "B635 Mean" "B635 SD" "% > B635+1SD" "% > B635+2SD" "F635 % Sat." EPP 245 Statistical Analysis of Laboratory Data
"F532 Median" "F532 Mean" "F532 SD" "B532 Median" "B532 Mean" "B532 SD" "% > B532+1SD" "% > B532+2SD" "F532 % Sat." EPP 245 Statistical Analysis of Laboratory Data
"Ratio of Medians (635/532)" "Ratio of Means (635/532)" "Median of Ratios (635/532)" "Mean of Ratios (635/532)" "Ratios SD (635/532)" "Rgn Ratio (635/532)" "Rgn R² (635/532)" "F Pixels" "B Pixels" "Sum of Medians" "Sum of Means" "Log Ratio (635/532)" "F635 Median - B635" "F532 Median - B532" "F635 Mean - B635" "F532 Mean - B532" "Flags" EPP 245 Statistical Analysis of Laboratory Data
Analysis Choices • Mean or median foreground intensity • Background corrected or not • Log transform (base 2, e, or 10) or glog transform • Log is compatible only with no background correction • Glog is best with background correction EPP 245 Statistical Analysis of Laboratory Data
DDR1 EPP 245 Statistical Analysis of Laboratory Data
Issues with Two-Color Arrays • Chips have different overall intensities, so normalization across chips is needed. • The overall intensity on the red channel may be greater or less than on the green channel, so normalization across dyes is needed. • The red/green difference is can be different at different intensity levels EPP 245 Statistical Analysis of Laboratory Data
Array normalization • Array normalization is meant to increase the precision of comparisons by adjusting for variations that cover entire arrays • Without normalization, the analysis would be valid, but possibly less sensitive • However, a poor normalization method will be worse than none at all. EPP 245 Statistical Analysis of Laboratory Data
Possible normalization methods • We can equalize the mean or median intensity by adding or multiplying a correction term • We can use different normalizations at different intensity levels (intensity-based normalization) for example by lowess or quantiles • We can normalize for other things such as print tips EPP 245 Statistical Analysis of Laboratory Data
Example for Normalization EPP 245 Statistical Analysis of Laboratory Data
. list Array Group Gene Expression +---------------------------------+ | Array Group Gene Expres~n | |---------------------------------| 1. | 1 1 1 1100 | 2. | 2 1 1 900 | 3. | 3 2 1 425 | 4. | 4 2 1 550 | 5. | 1 1 2 110 | |---------------------------------| 6. | 2 1 2 95 | 7. | 3 2 2 85 | 8. | 4 2 2 110 | 9. | 1 1 3 80 | 10. | 2 1 3 65 | |---------------------------------| 11. | 3 2 3 55 | 12. | 4 2 3 80 | +---------------------------------+ EPP 245 Statistical Analysis of Laboratory Data
. sort Gene . by Gene: anova Expression Group -------------------------------------------------------------------------------- -> Gene = 1 Number of obs = 4 R-squared = 0.9042 Root MSE = 117.925 Adj R-squared = 0.8564 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 262656.25 1 262656.25 18.89 0.0491 | Group | 262656.25 1 262656.25 18.89 0.0491 | Residual | 27812.5 2 13906.25 -----------+---------------------------------------------------- Total | 290468.75 3 96822.9167 EPP 245 Statistical Analysis of Laboratory Data
-> Gene = 2 Number of obs = 4 R-squared = 0.0556 Root MSE = 14.5774 Adj R-squared = -0.4167 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 25 1 25 0.12 0.7643 | Group | 25 1 25 0.12 0.7643 | Residual | 425 2 212.5 -----------+---------------------------------------------------- Total | 450 3 150 ------------------------------------------------------------------------------- -> Gene = 3 Number of obs = 4 R-squared = 0.0556 Root MSE = 14.5774 Adj R-squared = -0.4167 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 25 1 25 0.12 0.7643 | Group | 25 1 25 0.12 0.7643 | Residual | 425 2 212.5 -----------+---------------------------------------------------- Total | 450 3 150 EPP 245 Statistical Analysis of Laboratory Data
Additive Normalization by Means EPP 245 Statistical Analysis of Laboratory Data
. mean Expression . ereturn list scalars: e(df_r) = 11 e(N_over) = 1 e(N) = 12 e(k_eq) = 1 e(k_eform) = 0 macros: e(cmd) : "mean" e(title) : "Mean estimation" e(estat_cmd) : "estat_vce_only" e(varlist) : "Expression" e(predict) : "_no_predict" e(properties) : "b V" matrices: e(b) : 1 x 1 e(V) : 1 x 1 e(_N) : 1 x 1 e(error) : 1 x 1 functions: e(sample) . matrix ExpMeanMat = e(b) . matlist ExpMeanMat | Express~n -------------+----------- y1 | 304.5833 . scalar ExpMean = ExpMeanMat[1,1] . display ExpMean 304.58333 . anova Expression Array . predict ArrayMean . generate NormExp1=Expression-ArrayMean +ExpMean EPP 245 Statistical Analysis of Laboratory Data
. list Array Group Gene Expression ArrayMean NormExp1 +--------------------------------------------------------+ | Array Group Gene Expres~n ArrayM~n NormExp1 | |--------------------------------------------------------| 1. | 1 1 1 1100 430 974.5833 | 2. | 2 1 1 900 353.3333 851.25 | 3. | 3 2 1 425 188.3333 541.25 | 4. | 4 2 1 550 246.6667 607.9167 | 5. | 1 1 2 110 430 -15.41667 | |--------------------------------------------------------| 6. | 2 1 2 95 353.3333 46.24999 | 7. | 3 2 2 85 188.3333 201.25 | 8. | 4 2 2 110 246.6667 167.9167 | 9. | 1 1 3 80 430 -45.41667 | 10. | 2 1 3 65 353.3333 16.24999 | |--------------------------------------------------------| 11. | 3 2 3 55 188.3333 171.25 | 12. | 4 2 3 80 246.6667 137.9167 | +--------------------------------------------------------+ EPP 245 Statistical Analysis of Laboratory Data
. by Gene: anova NormExp1 Group ------------------------------------------------------------------------------------ -> Gene = 1 Number of obs = 4 R-squared = 0.9209 Root MSE = 70.0991 Adj R-squared = 0.8814 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 114469.431 1 114469.431 23.30 0.0403 | Group | 114469.431 1 114469.431 23.30 0.0403 | Residual | 9827.77662 2 4913.88831 -----------+---------------------------------------------------- Total | 124297.207 3 41432.4024 EPP 245 Statistical Analysis of Laboratory Data
-> Gene = 2 Number of obs = 4 R-squared = 0.9209 Root MSE = 35.0496 Adj R-squared = 0.8814 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 28617.3614 1 28617.3614 23.30 0.0403 | Group | 28617.3614 1 28617.3614 23.30 0.0403 | Residual | 2456.9441 2 1228.47205 -----------+---------------------------------------------------- Total | 31074.3055 3 10358.1018 ------------------------------------------------------------------------------------- -> Gene = 3 Number of obs = 4 R-squared = 0.9209 Root MSE = 35.0496 Adj R-squared = 0.8814 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 28617.3612 1 28617.3612 23.30 0.0403 | Group | 28617.3612 1 28617.3612 23.30 0.0403 | Residual | 2456.94427 2 1228.47214 -----------+---------------------------------------------------- Total | 31074.3055 3 10358.1018 EPP 245 Statistical Analysis of Laboratory Data
Multiplicative Normalization by Means EPP 245 Statistical Analysis of Laboratory Data
. generate NormExp2 = Expression*ExpMean/ArrayMean . list Array Group Gene Expression ArrayMean NormExp2 +-------------------------------------------------------+ | Array Group Gene Expres~n ArrayM~n NormExp2 | |-------------------------------------------------------| 1. | 1 1 1 1100 430 779.1667 | 2. | 2 1 1 900 353.3333 775.8254 | 3. | 3 2 1 425 188.3333 687.3341 | 4. | 4 2 1 550 246.6667 679.1385 | 5. | 1 1 2 110 430 77.91666 | |-------------------------------------------------------| 6. | 2 1 2 95 353.3333 81.89268 | 7. | 3 2 2 85 188.3333 137.4668 | 8. | 4 2 2 110 246.6667 135.8277 | 9. | 1 1 3 80 430 56.66667 | 10. | 2 1 3 65 353.3333 56.03184 | |-------------------------------------------------------| 11. | 3 2 3 55 188.3333 88.94912 | 12. | 4 2 3 80 246.6667 98.78378 | +-------------------------------------------------------+ EPP 245 Statistical Analysis of Laboratory Data
. by Gene: anova NormExp2 Group -------------------------------------------------------------------------------- -> Gene = 1 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 8884.90342 1 8884.90342 453.70 0.0022 -------------------------------------------------------------------------------- -> Gene = 2 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 3219.72043 1 3219.72043 696.33 0.0014 -------------------------------------------------------------------------------- -> Gene = 3 Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 1407.54019 1 1407.54019 57.97 0.0168 EPP 245 Statistical Analysis of Laboratory Data
Multiplicative Normalization by Medians EPP 245 Statistical Analysis of Laboratory Data
. sort Array . table Array, contents(p50 Expression) ------------------------- Array | med(Expres~n) ----------+-------------- 1 | 110 2 | 95 3 | 85 4 | 110 ------------------------- . input ArrayMed ArrayMed 1. 110 2. 110 3. 110 4. 95 5. 95 6. 95 7. 85 8. 85 9. 85 10. 110 11. 110 12. 110 EPP 245 Statistical Analysis of Laboratory Data
. summarize Expression, detail Expression ------------------------------------------------------------- Percentiles Smallest 1% 55 55 5% 55 65 10% 65 80 Obs 12 25% 80 80 Sum of Wgt. 12 50% 102.5 Mean 304.5833 Largest Std. Dev. 363.1144 75% 487.5 425 90% 900 550 Variance 131852.1 95% 1100 900 Skewness 1.277954 99% 1100 1100 Kurtosis 3.132949 . generate NormExp3 = Expression*102.5/ArrayMed EPP 245 Statistical Analysis of Laboratory Data