Download
1 / 30
300 likes | 309 Views
Learn about hash tables, direct-address tables, collision resolution, hash functions, and analysis of hash operations. Understand simple uniform hashing, computing key values, and examples like linear probing. Discover how to implement and utilize hash tables effectively.

E N D
Hash Tables • Many applications require a dynamic set that only supports the dictionary operations: Insert, Delete, Search • A hash table is an efficient implementation of a dictionary • Worst case – same as linked list – O(n) • Under reasonable assumptions – O(1)
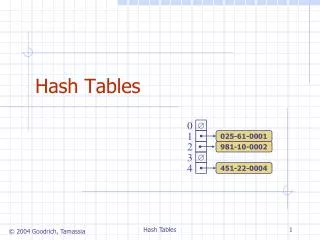
Direct-address Tables • Assumptions • The universe U of keys is reasonably small:U = { 0, 1, 2, …, m-1 }, for some small m • No two elements have the same key • Implementation • Allocate an array of size m • Insert the kth element into the kth slot in the array
Direct-address Tables • Advantage • O(1) time for all operations • Disadvantages • Wasteful if the number of elements actually inserted is significantly smaller than the size of the universe (m) • Only applicable for small values of m,i.e. a limited range of keys
Hash Tables • Performance is almost similar to that of a direct-address table, but without the limitations • The universe U may be very large • The storage requirement is O(|K|), where K is the set of keys actually used • Disadvantage – O(1) performance is now average case, not worst case
Hash Tables • We need a hash function to map keys from the universe U into the hash tableh: U { 0, 1, …, m-1 } • For each key k, the hash function computes a hash value h(k) • If two keys hash to the same value:h(k1) = h(k2), we call this a collision
Collisions • Can we avoid collisions altogether? • No. Since |U| > m, some keys must have the same hash value • A good hash function will be as ‘random’ as possible • Still, collisions must be resolved
Collision Resolution • Chaining (also called open hash) • Elements stored in their ‘correct’ slot • Collisions resolved by creating linked lists • Open addressing (also calledclosed hash) • All elements stored inside the table • Maybe rehashed if their slot is full
Collision resolution – Chaining • All keys that have the same hash value are placed in a linked list • Insertion can be done at the beginning of the list in O(1) time • Searching is proportional to the length of the list – with a good hash function, will also be O(1)
Hash Function Requirements • A hash function must be deterministic – the hash value generated for each key cannot change during the life of the hash table • Equal keys must always be mapped to the same hash value
Hash Function Properties • Properties of a good hash function • Easy to evaluate – h(x) can be computed very quickly (not only in O(1), but also with a small constant) • Uniform distribution over all the table slots • Different keys are mapped to different slots (as much as possible)
Simple Uniform Hashing • The quality of the hash function strongly influences the efficiencyof the hash table • Simple Uniform Hashing assumption: The hash function will hash any keyinto any slot with equal probability • It is possible to define hash functions that almost satisfy this assumption
Analysis • The load factor of a hash table is defined as the number of elements stored in the table, divided by the total number of slots: • A search will take under the assumption of simple uniform hashing • Therefore, all hash operations can be performed in O(1)
Computing Key Values • The first step is to represent the key as a natural integer number • For example if S is a string then we can interpret it as an integer value using the following formula:
The Division Method • Key k is mapped into one of m slots by taking the remainder of k divided by m: • Choosing the value of m • Preferably prime • Not too close to a power of 2
Example – the Division Method • Let h be a hash table of 9 slots andh(k) = k mod 9. insert the elements:6, 43, 23, 62, 1, 13, 34, 55, 25 h(6) = 6 mod 9 = 6 h(43) = 43 mod 9 = 7 h(23) = 23 mod 9 = 5 h(62) = 62 mod 9 = 8 h(1) = 1 mod 9 = 1 h(13) = 13 mod 9 = 4 h(34) = 34 mod 9 = 7 h(55) = 55 mod 9 = 1 h(25) = 25 mod 9 = 7
Open Addressing • Each element occupies a single slot in the hash table – no chaining is done • To insert an element, we probe the table according to the hash function until an empty slot is found • The hash function is now a function of both the key and the number of attempts in the insertion process
Linear Probing • A hash value is computed using any hash function h’, and then the number of the current attempt is added to it: • Slots are examined sequentially, until an empty one is found
Linear Probing • Easy to implement but suffers from primary clustering • Clusters tend to grow: • If an empty slot is preceded by i full slots, the probability that it will be the next one filled is (i+1)/m • If an empty slot is preceded by another empty slot, the probability is only 1/m
Exercise • You are given a hash table H with 11 slots • Demonstrate inserting the following elements using linear probing and a hash function h(k) = k mod m 10, 22, 31, 4, 15, 28, 17, 88, 59
Solution • h(10, 0) = (10 mod 11 + 0) mod 11 = 10 • h(22, 0) = (22 mod 11 + 0) mod 11 = 0 • h(31, 0) = (31 mod 11 + 0) mod 11 = 9 • h(4, 0) = (4 mod 11 + 0) mod 11 = 4 • h(15, 0) = (15 mod 11 + 0) mod 11 = 4 • h(15, 1) = (15 mod 11 + 1) mod 11 = 5 • h(28, 0) = (28 mod 11 + 0) mod 11 = 6 • h(17, 0) = (17 mod 11 + 0) mod 11 = 6
Solution • h(17, 1) = (17 mod 11 + 1) mod 11 = 7 • h(88, 0) = (88 mod 11 + 0) mod 11 = 0 • h(88, 1) = (88 mod 11 + 1) mod 11 = 1 • h(59, 0) = (59 mod 11 + 0) mod 11 = 4 • h(59, 1) = (59 mod 11 + 1) mod 11 = 5 • h(59, 2) = (59 mod 11 + 2) mod 11 = 6 • h(59, 3) = (59 mod 11 + 3) mod 11 = 7 • h(59, 4) = (59 mod 11 + 4) mod 11 = 8
Quadratic Probing • In this case, the second attempt is a more complex function of i: • Tries to avoid primary clustering • However, suffers from secondary clustering • The entire probing sequence is determined by the initial probe:
Double Hashing • Given two hash functions • One of the best methods for open addressing collision resolution • Permutations are almost random • For the entire hash to be searched,m and h2(k) must be relatively prime
Double Hashing • Possible selections of h2(k) • Select m to be a power of 2, and design h2(k) to produce odd numbers • Select m to be prime, and m’ to be m-1
Issues in Open Addressing • Search may fail if items are deleted • Solution: • Mark deleted items with a special symbol • Search treats this symbol as full, while insert treats it as empty • Table may be filled up • Solution: • Rehashing (copy into a larger table)