Download

1 / 6
70 likes | 297 Views
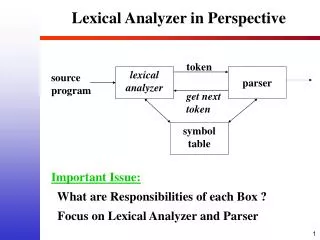
Lexical Analyzer. The main task of the lexical analyzer is to read the input source program, scanning the characters, and produce a sequence of tokens that the parser can use for syntactic analysis. The interface may be to be called by the parser to produce one token at a time

E N D
Lexical Analyzer • The main task of the lexical analyzer is to read the input source program, scanning the characters, and produce a sequence of tokens that the parser can use for syntactic analysis. • The interface may be to be called by the parser to produce one token at a time • Maintain internal state of reading the input program (with lines) • Have a function “getNextToken” that will read some characters at the current state of the input and return a token to the parser • Other tasks of the lexical analyzer include • Skipping white space and comments • Keeping track of line numbers for error reporting • Sometimes it can also produce the annotated lines for error reports • Produce the value of the token • Insert identifiers into the symbol table
Character Level Scanning • The lexical analyzer needs to have a well-defined valid character set • Produce invalid character errors • Delete invalid characters from token stream so as not to be used in the parser analysis • E.g. don’t want invisible characters in error messages • For every end-of-line, keep track of line numbers for error reporting • Skip over white space and comments • If comments are nested (not common), must keep track of nesting to find end of comments • May produce hidden tokens, for convenience of scanner structure • Always produce an end-of-file token • Important that quoted strings and comments don’t get stuck if an unexpected end of file occurs
Tokens, token types and values • The set of tokens is typically something like the following table • Or may have separate token types for different operators or reserved words • May want to keep line number with each token
Token Actions • Each token recognized can have an action function • Many token types produce a value • In the case of numeric values, make sure property numeric errors produced, e.g. integer overflow • Put identifiers in the symbol table • Note that at this time, no effort is made to distinguish scope; there will be one symbol table entry for each identifier • Later, separate scope instances will be produced • Other types of actions • End-of-line (can be treated as a token type that doesn’t output to the parser) • Increment line number • Get next line of input to scan
Testing • Execute lexical analyzer with test cases and compare results with expected results • Test cases • Exercise every part of lexical analyzer code • Produce every error message • Don’t have to be valid programs – just valid sequence of tokens
Resources • Per Brinch Hansen, On Pascal Compilers, Prentice-Hall, 1985. Out of print. • Aho, Sethi, and Ullman, Compilers: Principles, Techniques, and Tools. Addison-Wesley, 1986. (The red dragon book)