Download
1 / 28
290 likes | 525 Views
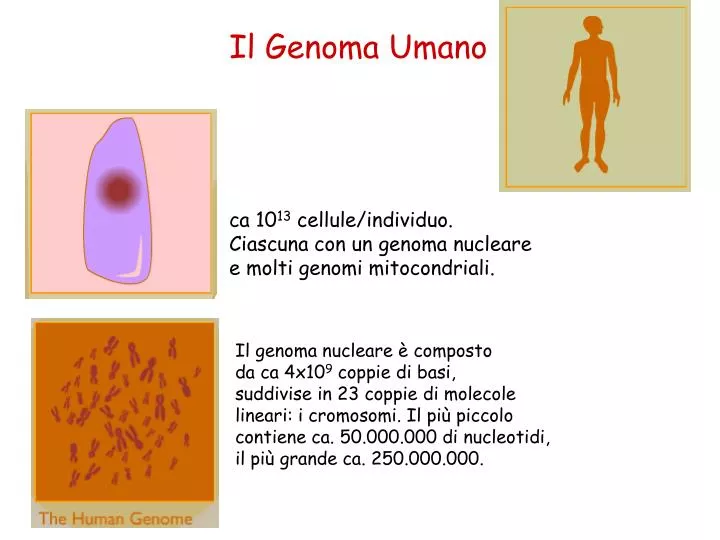
Il Genoma Umano. ca 10 13 cellule/individuo. Ciascuna con un genoma nucleare e molti genomi mitocondriali. Il genoma nucleare è composto da ca 4x10 9 coppie di basi, suddivise in 23 coppie di molecole lineari: i cromosomi. Il più piccolo contiene ca. 50.000.000 di nucleotidi,

E N D
Il Genoma Umano ca 1013 cellule/individuo. Ciascuna con un genoma nucleare e molti genomi mitocondriali. Il genoma nucleare è composto da ca 4x109 coppie di basi, suddivise in 23 coppie di molecole lineari: i cromosomi. Il più piccolo contiene ca. 50.000.000 di nucleotidi, il più grande ca. 250.000.000.
La Biologia Moderna Progetti Genoma: Perchè? La determinazione e la conoscenza dell’intera sequenza genomica sembrano essere la condizione necessaria per comprendere la completa biologia di un determinato organismo
In che modo? Sequenziamento del DNA significa determinazione della sequenza lineare delle basi che lo compongono, cioè A, T, C e G. Il DNA umano è composto da 3.12 miliardi di paia di basi
La Biologia Moderna: i Progetti Genoma Un requisito essenziale alla comprensione della biologia completa di un organismo è la determinazione della sequenza del suo intero genoma “A prerequisite to understanding the complete biology of an organism is the determination of its entire genome sequence” Fleischmann et al. 1995
2000-2001 Il Genoma Umano completamente sequenziato e assemblato
1953 James Watson e Francis Crick determinano la struttura del DNA (La doppia elica) 1977 Gli scienziati americani Allan Maxam and Walter Gilbert e l'inglese Frederick Sanger mettono a punto 2 diversi metodi per sequenziare il DNA, cioè per "leggere" la successione di basi nucleotidiche che lo compongono. Il metodo di Sanger, oggi automatizzato, è quello tuttora utilizzato. 1985 Lo scienziato americano Kary Mullis inventa la PCR, una tecnica che permette di moltiplicare artificialmente il DNA, anche se presente in quantità minima. 1986Il premio Nobel Renato Dulbecco e Leroy Hood lanciano l'idea di sequenziare l'intero genoma Umano. 1990 Negli Stati Uniti nasce ufficialmente lo Human Genome Project (HGP), sotto la guida di James Watson. Negli anni successivi Regno Unito, Giappone, Francia, Germania, Cina si uniscono al progetto formando un consorzio pubblico internazionale. In Italia il progetto genoma nasce nel 1987 ma si interrompe nel 1995. 1992 Craig Venter lascia l'NIH e il progetto pubblico. Fonderà una compagnia privata, la Celera Genomics, portando avanti un progetto genoma parallelo. 1993 Francis Collins e John Sulston diventano direttori rispettivamente del National Human Genome Research Center negli USA e del Sanger Center in Inghilterra, i 2 principali centri coinvolti nel HGP. LE TAPPE DEL PROGETTO GENOMA
1999 (Dicembre) Pubblicata su Nature la sequenza completa del cromosoma 22. 2000 (Maggio) pubblicata su Nature la sequenza completa del cromosoma 21. 2000 (Giugno) Francis Collins e Craig Venter annunciano congiuntamente di aver completato la "bozza" del genoma Umano. 2001 La bozza completa del genoma umano (che gli inglesi chiamano working draft) è pubblicata su Nature (quella del consorzio pubblico) e su Science (quella della Celera). Celera Genomics (Applera, Applied Biosystems) Istituzioni pubbliche in: USA, UK, China Francia Germania
Il genoma di un virus è composto da poche migliaia di bp Dimensioni del Genoma in Megabasi ProcariotiMycoplasma genitalium0.58 Haemophilus influenzae1.83 Escherichia coli 4.7 EucariotiSaccharomyces cerevisiae13.5 Caenorabditis elegans100 Drosophila melanogaster165 Homo sapiens3300
Geni e sequenze associate circa 900.000.000 DNA extragenico circa 2.100.000.000 Non codificante 810.000.000 Codificante 90 .000.000 DNA unico e a basso numero di copie 1.680.000.000 DNA ripetitivo 420.000.000 Introni Pseudogeni Ripetuto in tandem Disperso Regioni di controllo Minisatelliti Microsatelliti SINE LINE Satellite Retroposoni Genoma Umano >3.000.000.000 Il DNA spazzatura è veramente tale?
1-Geni • 2-pseudogeni • 3-ripetizioni • 4-minisatelliti • 5-significato ignoto
GENI E SEQUENZE CORRELATE -DNA codificante -DNA non codificante
Funzione dei geni negli eucarioti superiori • Geni che codificano per prodotti proteici; • Geni che codificano per RNA non codificanti (RNA-genes).
I geni possono essere classificati, oltre che per la funzione, anche per la rappresentatività e per l’organizzazione • Geni singoli • Geni ripetuti • Geni appartenenti a famiglie • Geni in clusters • Geni interspersi nel genoma
PSEUDOGENI: copia non funzionante di un gene • CONVENZIONALI: gene inattivato a causa di una o più mutazioni • MATURATI: anomala espressione genica
DNA RIPETUTO Il genoma nucleare contiene una grande quantità di sequenze ripetute che sono in gran parte inattive da un punto di vista trascrizionale A. DNA RIPETUTO IN TANDEM B: DNA RIPETTUTO INTERSPERSO
Classi principali del DNA ripetuto in tandem Il DNA satellite è lungo e ripetitivo (riptetizioni di 171 nucletidi) e costitutisce la massa principale dell’eterocromatina. E’ il cosiddetto DNA alfoide o satellite a, 3-5% ogni cromosoma. Funzione poco chiara, probabilmente svolgono un ruolo strutturale. Satellite 2 e 3 contengono schiere di sequenze che si basano sulla ripetizione in tandem ATTCC Il DNA minisatelliteè ipervariabile ed è altamente polimorfico. Sono più di 1000 scheramenti (100-20.000 bp) di corte unità ripetute in tandem. La sequenza centrale è GGGCAGGAXG Importante da punto di vista diagnostico: zona del DNA fingerprint. Un minisatellite particolare è costituito dall’unità ripetuta TTAGGG (10-15 kb), localizzato nei telomeri. Ha funzione protettiva dei cromosomi. Il DNA microsatellite contine sequenze di 1-4 nucletidi ripetuti in tutto il genoma. Le più comuni sono le dinucletidiche CA (0.5% del genoma; anche questo è altamente polimorfico.
DNA RIPETUTO INTERSPERSO • Viene suddiviso in due principali famiglie: • Short Interspersed Nucleotide Elements; • Long Interspersed Nucleotide Elements
Il DNA mitocondriale 0.0005% del genoma umano • doppio filamento a diversa composizione: • filamento heavy (H) e light (L) - contiene 37 geni, 28 su filamento H e 9 su filamento L • dei 37 geni, 24 codificano per prodotti maturi ad RNA e 13 per polipeptidi dei complessi multimerici del mitocondrio (concetto di semiautonomia) • i geni sono estremamente compatti: • privi di introni • sovrapposti parzialmente (subunita’ 6 e 8 dell’ATPasi) • trascritti privi di codoni di stop - eredita’ matroclina
1 2 3 X 6 16 7 mitochondria 11 4 19 20 8 5 9 10 17 18 12 13 22 15 21 14 Y .016 45 66 72 48 51 104 3.2*109 bp 86 88 100 107 163 118 148 143 142 140 176 163 148 221 279 198 197 Myoglobin *5.000 a globin 251 b-globin (chromosome 11) 6*104 bp *20 Exon 3 Exon 1 Exon 2 3*103 bp 5’ flanking 3’ flanking *103 DNA: ATTGCCATGTCGATAATTGGACTATTTGGA 30 bp Protein: aa aa aa aa aa aa aa aa aa aa