Download

1 / 25
250 likes | 503 Views
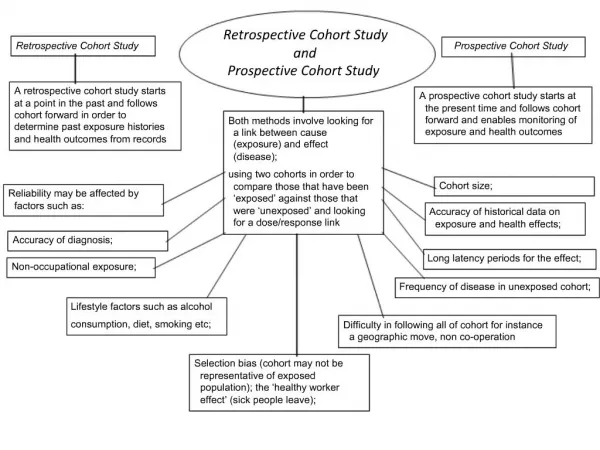
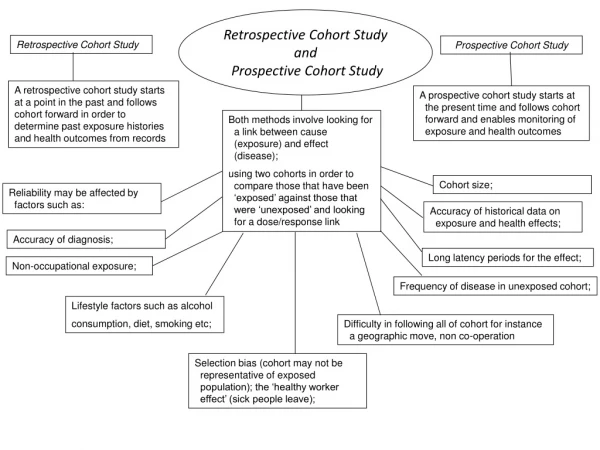
Design and Analysis of Clinical Study 11. Analysis of Cohort Study. Dr. Tuan V. Nguyen Garvan Institute of Medical Research Sydney, Australia. Overview. Incidence, person-years, hazard Relative risk Logistic regression analysis Lifetable Cox’s regression analysis

E N D
Design and Analysis of Clinical Study 11. Analysis of Cohort Study Dr. Tuan V. Nguyen Garvan Institute of Medical Research Sydney, Australia
Overview • Incidence, person-years, hazard • Relative risk • Logistic regression analysis • Lifetable • Cox’s regression analysis • Diagnosis and prognosis
Person-time • Person-time = # persons x duration 1 2 2 4 3 4 4 8 5 2 0 2 4 6 8 Time Incidence rate (IR). During (2+4+4+8+2)=20 person-years, there were 2 incident cases: IR = 2/20 = 0.1
Estimation of Incidence Rates • Consider a study where P patient-years have been followed and N cases (eg deaths, survivors, diseased, etc.) were recorded. • Assumption: Poisson distribution. • The estimate of incidence rate is: I = N / P • Standard error of I is: • 95% confidence interval of “true” incidence rate: I+ 1.96 x SD(I)
Relative Risk • Relative risk (RR): Incidence rate of ischemic heart disease (IHD) <2750 kcal >2750 kcal ______________________________________________________________ Person-years 1858 2769 New cases 28 17 ______________________________________________________________ Estimate rate 15.1 6.1 SD of est. rate 2.8 1.5 • L = log(RR) = 0.908 • Standard error of log(RR) • 95% of L: L ±1.96xSE = 0.908 ± 1.96x0.3075 = 0.3055, 1.51 • 95% of RR: = exp(0.3055), exp(1.51) = 1.36, 4.53
Analysis of Difference in Incidence Rates • Difference: D = 15.1 – 6.1 = 8.93 Incidence rate of ischemic heart disease (IHD) <2750 kcal >2750 kcal ______________________________________________________________ Person-years 1858 2769 New cases 28 17 ______________________________________________________________ Estimate rate 15.1 6.1 SD of est. rate 2.8 1.5 • Standard error (SE) of D • 95% of D = D ±1.96xSE = 8.93 ± 1.96x0.032 = 3.65, 14.2
Logistic Regression Analysis • Example: A prospective of the association between BMI, BMD and bone turnover markers and fracture in 139 men. The risk factors were measured at baseline, and fracture was recorded during the 10-year follow-up: id fx age bmi bmd ictp pinp 1 1 79 24.7252 0.818 9.170 37.383 2 1 89 25.9909 0.871 7.561 24.685 3 1 70 25.3934 1.358 5.347 40.620 4 1 88 23.2254 0.714 7.354 56.782 5 1 85 24.6097 0.748 6.760 58.358 6 0 68 25.0762 0.935 4.939 67.123 7 0 70 19.8839 1.040 4.321 26.399 8 0 69 25.0593 1.002 4.212 47.515 9 0 74 25.6544 0.987 5.605 26.132 10 0 79 19.9594 0.863 5.204 60.267 ... 137 0 64 38.0762 1.086 5.043 32.835 138 1 80 23.3887 0.875 4.086 23.837 139 0 67 25.9455 0.983 4.328 71.334
Logistic Regression: Model • p = probability of fracture • odds: • Logit of p: • X is a risk factor. Linear logistic model: L = a + bX + e • Expected value of e = 0. Expected value of L is: L = a + bX • Odds = ea+bX • Odds ratio (OR)
Logistic Regression Analysis using R fracture <- read.table(“fracture.txt”, header=TRUE, na.string=”.”) attach(fulldata) results <- glm(fx ~ bmd, family=”binomial”) summary(results) Deviance Residuals: Min 1Q Median 3Q Max -1.0287 -0.8242 -0.7020 1.3780 2.0709 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 1.063 1.342 0.792 0.428 bmd -2.270 1.455 -1.560 0.119 (Dispersion parameter for binomial family taken to be 1) Null deviance: 157.81 on 136 degrees of freedom Residual deviance: 155.27 on 135 degrees of freedom AIC: 159.27
Model of Prediction > sd(bmd) [1] 0.1406543 • OR per SD increase in BMD: e-2.27*0.1406 = 0.7267 • Predictive model:
Model of Prediction plot(bmd, fitted(glm(fx ~ bmd, family=”binomial”)))
Problem of Time-to-event Data • Non-normally distribution • Lost to follow-up • Censored observations (eg patients are still alive at the last follow-up) • A class of statistical methods to study the occurrence and timing of events. • Its applications are found in medicine and engineering science. • Lifetime of machine components • Time from diagnosis to death • Time from infection to disease onset (latency time)
Definition of “Failure Time” • Time origin • Time origin = starting time of the experiment/study • Scale of measurement • Chronological time, but not necessary • Must be non-negative • Precise definition • Death • Death with a specified reason 1 Censored obs 2 Observed failure 3 4 5 6 c
Construction of Lifetable • Survival time (in years) of 18 patients after diagnosis of parathyroid cancer: 10 13* 18* 19 23* 30 36 38* 54* 56* 59 75 93 97 104* 107 107* 107* *: censored (= survived) • Arrange the observed failure times in an increasing order (tj) • Calculate the number of failures (dj) during [tj-1 to tj] • Calculate the number of censored observations (cj) during [tj-1 to tj] • Calculate the number of subjects at risk up to time tj-1 • Compute the proportion of deaths for each interval • Compute the estimate of survivor function
Lifetable analysis using R library(survival) weeks <- c(10, 13, 18, 19, 23, 30, 36, 38, 54, 56, 59, 75, 93, 97, 104, 107, 107, 107) status <- c(1, 0, 0, 1, 0, 1, 1,0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0) data <- data.frame(duration, status) survtime <- Surv(weeks, status==1) kp <- survfit(survtime) summary(kp) time n.risk n.event survival std.err lower 95% CI upper 95% CI 10 18 1 0.944 0.0540 0.844 1.000 19 15 1 0.881 0.0790 0.739 1.000 30 13 1 0.814 0.0978 0.643 1.000 36 12 1 0.746 0.1107 0.558 0.998 59 8 1 0.653 0.1303 0.441 0.965 75 7 1 0.559 0.1412 0.341 0.917 93 6 1 0.466 0.1452 0.253 0.858 97 5 1 0.373 0.1430 0.176 0.791 107 3 1 0.249 0.1392 0.083 0.745
Lifetable analysis using R plot(kp, xlab="Time (weeks)", ylab="Cumulative survival probability")
Example of Cox’s Survival Data Time to infection among patients with herpes. 25 patients were treated with gd2 and 23 patients were not treated. Risk factor is the number of infectious episodes in previous year.
Cox’s Regression Model: Theory • Setting: a prospective study (or randomized clinical trial) • Risk factors were measured at baseline • Patients were follow-up for T time • Event occurred during that time • Risk of having the event was related to baseline risk ? • Let x1, x2, x3, … xp be risk factors. X could be continuous or discrete variables. • Model: Risk = (base risk) x b(risk factor) h(t) : hazard / risk of having the event l(t) : base risk b1x1 + b2x2 + … : coefficient associated with each risk factor
Cox’s Regression Model: Data • Relative risk (relative hazards - RH) b1 represents the relative hazards or treatment effect
Cox’s Regression Model Using R group <- c(1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2) episode <- c(12, 10, 7, 10, 6, 8, 8, 9, 11, 13, 7, 13, 9, 12, 13, 8, 10, 16, 6, 14, 13, 13, 16, 13, 9, 9, 10, 12, 7, 7, 7, 7, 11, 16, 16, 6, 15, 9, 10, 17, 8, 8, 8, 8, 14, 13, 9, 15) time <- c(8, 12, 52, 28, 44, 14, 3, 52, 35, 6, 12, 7, 52, 52, 36, 52, 9, 11, 52,15, 13, 21,24, 52,28, 15,44, 2, 8,12,52,21,19, 6,10,15, 4, 9,27, 1, 12,20,32,15, 5,35,28, 6) infected <- c(1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1) data <- data.frame(group, episode, time, infected)
Cox’s Regression Model Using R library(survival) kp.by.group <- survfit(Surv(time, infected==1) ~ group) # Kaplan Meier curve summary(kp.by.group) plot(kp.by.group, xlab="Time", ylab="Cum. survival probability", col=c(“black”, “red”)) # Cox’s regression model 1 analysis <- coxph(Surv(time, infected==1) ~ group) summary(analysis) # Cox’s regression model 2 analysis <- coxph(Surv(time, infected==1) ~ group + episode) summary(analysis) Cox.model <- survfit(coxph(Surv(time, infected==1)~episode+strata(group)))
Cox’s Regression Model Using R analysis <- coxph(Surv(time, infected==1) ~ group + episode) summary(analysis) coef exp(coef) se(coef) z p group 0.874 2.40 0.3712 2.35 0.0190 episode 0.172 1.19 0.0648 2.66 0.0079 exp(coef) exp(-coef) lower .95 upper .95 group 2.40 0.417 1.16 4.96 episode 1.19 0.842 1.05 1.35 Rsquare= 0.196 (max possible= 0.986 ) Likelihood ratio test= 10.5 on 2 df, p=0.00537 Wald test = 10.4 on 2 df, p=0.00555 Score (logrank) test = 10.6 on 2 df, p=0.00489