Download
1 / 1
10 likes | 179 Views
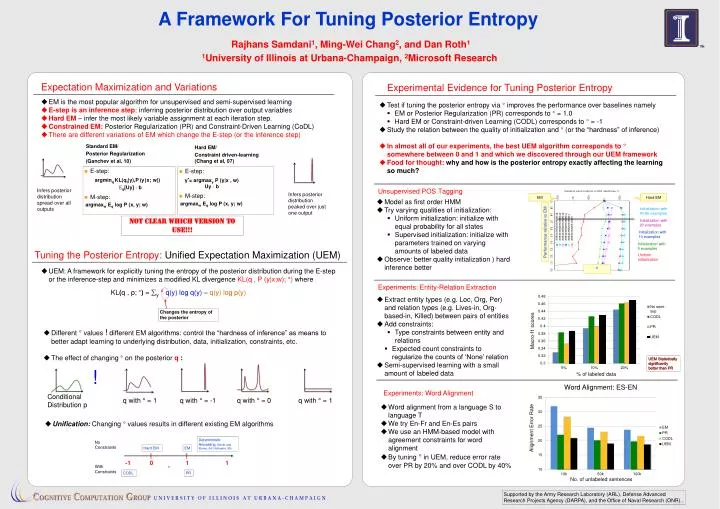
A Framework For Tuning Posterior Entropy R ajhans Samdani 1 , Ming-Wei Chang 2 , and Dan Roth 1 1 University of Illinois at Urbana- Champaign, 2 Microsoft Research. - 1. 0. 1. 1. Expectation Maximization and Variations. Experimental Evidence for Tuning Posterior Entropy.

E N D
A Framework For Tuning Posterior Entropy Rajhans Samdani1, Ming-Wei Chang2, and Dan Roth1 1University of Illinois at Urbana-Champaign, 2Microsoft Research -1 0 1 1 Expectation Maximization and Variations Experimental Evidence for Tuning Posterior Entropy • EM is the most popular algorithm for unsupervised and semi-supervised learning • E-step is an inference step: inferring posterior distribution over output variables • Hard EM – infer the most likely variable assignment at each iteration step. • Constrained EM: Posterior Regularization (PR) and Constraint-Driven Learning (CoDL) • There are different variations of EM which change the E-step (or the inference step) • Test if tuning the posterior entropy via °improves the performance over baselines namely • EM or Posterior Regularization (PR) corresponds to ° = 1.0 • Hard EM or Constraint-driven Learning (CODL) corresponds to °= -1 • Study the relation between the quality of initialization and ° (or the “hardness” of inference) • In almost all of our experiments, the best UEM algorithm corresponds to ° somewhere between 0 and 1 and which we discovered through our UEM framework • Food for thought: why and how is the posterior entropy exactly affecting the learning so much? StandardEM/ Posterior Regularization (Ganchev et al, 10) Hard EM/ Constraint driven-learning (Chang et al, 07) • E-step: • M-step: argmaxwEqlog P (x, y; w) • E-step: • M-step: argmaxwEqlog P (x, y; w) • argminqKL(qt(y),P(y|x; w)) • Eq[Uy] ·b y*= argmaxyP (y|x, w) Uy·b Infers posterior distribution spread over all outputs Unsupervised POS Tagging Infers posterior distribution peaked over just one output EM Hard EM • Model as first order HMM • Try varying qualities of initialization: • Uniform initialization: initialize with equal probability for all states • Supervised initialization: initialize with parameters trained on varying amounts of labeled data • Observe: better quality initialization )hard inference better Initialization with 40-80 examples Not clear which version To use!!! Initialization with 20 examples Performance relative to EM Initialization with 10 examples Initialization with 5 examples Tuning the Posterior Entropy: Unified Expectation Maximization (UEM) Uniform Initialization ° • UEM: A framework for explicitly tuning the entropy of the posterior distribution during the E-step or the inference-step and minimizes a modified KL divergence KL(q , P (y|x;w); °) where Experiments: Entity-Relation Extraction • KL(q, p; °)= y°q(y) log q(y) – q(y) log p(y) • Extract entity types (e.g. Loc, Org, Per) and relation types (e.g. Lives-in, Org-based-in, Killed) between pairs of entities • Add constraints: • Type constraints between entity and relations • Expected count constraints to regularize the counts of ‘None’ relation • Semi-supervised learning with a small amount of labeled data Changes the entropy of the posterior • Different ° values ! different EM algorithms: control the “hardness of inference” as means to better adapt learning to underlying distribution, data, initialization, constraints, etc. • The effect of changing °on the posterior q : Macro-f1 scores UEM Statistically significantly better than PR ! % of labeled data Word Alignment: ES-EN Experiments: Word Alignment Conditional Distribution p q with ° = 1 q with ° = -1 q with ° = 0 q with ° = 1 • Word alignment from a language S to language T • We try En-Fr and En-Es pairs • We use an HMM-based model with agreement constraints for word alignment • By tuning °in UEM, reduce error rate over PR by 20% and over CODL by 40% • Unification: Changing ° values results in different existing EM algorithms Alignment Error Rate Deterministic Annealing (Smith and Eisner, 04; Hofmann, 99) No Constraints Hard EM EM With Constraints ° CODL PR No. of unlabeled sentences Supported by the Army Research Laboratory (ARL), Defense Advanced Research Projects Agency (DARPA), and the Office of Naval Research (ONR)..