Download

1 / 36
360 likes | 558 Views
Faktory a jejich uspořádání. Faktor (kvalitativní proměnná) factor (= categorial variable = categorical v. ) Hladina faktoru factor level Máme-li dva nebo více faktorů, záleží správná volba modelu ANOVA na jejich vzájemném vztahu (uspořádání, design )

E N D
Faktory a jejich uspořádání • Faktor (kvalitativní proměnná)factor (= categorial variable = categorical v.) • Hladina faktorufactor level • Máme-li dva nebo více faktorů, záleží správná volba modelu ANOVA na jejich vzájemném vztahu (uspořádání, design) • Faktoriální (factorial design) x hierarchické (nested = hierarchical design)
Faktoriální uspořádání • Každá hladina určitého faktoru je kombinována s každou hladinou ostatních faktorů • Mají-li naše faktory jen 2 hladiny, pakpři 2 faktorech máme 4 kombinacepři 3 faktorech máme 8 kombinací ... • Obecně, mají-li faktory A, B, C,... a, b, c,... hladin, pak je počet kombinací a*b*c*...
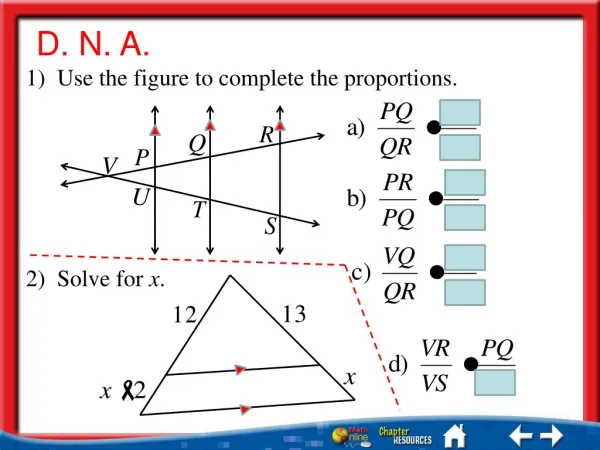
Hierarchické uspořádání • tři lokality • na každé lokalitě tři kytky • na každé pět měření Faktor Kytka je vložen (vnořen) do faktoru Lokalita(Kytka is nested in Lokalita) Kytka 1 (kyt1) z první lokality nemá nicspolečného s kytkou 1 z druhé lokality
Faktoriální uspořádání: vyváženost • Je nejlepší, pokud máme pro každou kombinaci hladin faktorů stejný počet pozorování, dostáváme pak nejsilnějšía nejvíce robustní test • Přinejmenším bychom ale měli mít proporční uspořádání
Když jsou faktory “nezávislé”, a design je vyvážený Vyvážený design Váhy krys
Když jsou faktory “nezávislé”, a design je proporční Proporční design Váhy krys
Když jsou faktory “závislé”, tj. design není vyvážený ani proporční Neproporční design Váhy krys Podle marginálnch průměrů se zdá, jako by poslech hudby ovlivňoval váhu krys. (Jsou metody, které si s tím jsou schopny částečně poradit [LS means], ale ztrácí se síla testu pro oba faktory).
Statistica spočítá cokoliv, ale • Pokud mám proporční uspořádání, výsledek by měl být vždy stejný • Dvoucestnou ANOVu mohu počítat i při neproporčním uspořádání - předvolba, která tam je (Type III sum of squares - orthogonal) je v pořádku, ale mohu se podle situace pokusu rozhodnout i pro jiný (asi Type I - sequential), a měl bych vědět, co který znamená (a proč se tedy výsledky liší).
Dvoucestná ANOVAbez interakce • Nejprve začneme s modelem, ve kterém předpokládáme, že vlivy hnojení a kosení na počet druhů jsou aditivní: Xijk = m+ ai + bj + eijk • m je celkový (společný) průměr (např. 22.5) • a je vliv kosení (např. a1=-5.0, a2=+5.0) • b je vliv hnojení (např. b1=+2.5, b2=-2.5) • e je náhodná variabilita, nezávislá na hodnotách faktorů
Dvoucestná ANOVAbez interakce • Aditivitu faktorů často nemůžeme předpokládat a priori, ověřujeme ji použitím neaditivního modelu (s interakcí): test interakčního členu a interaction plot SSTotal=SShnojeno+SSkoseno+SShnojeno*koseno+SSerror H0A: a1=a2=0 hnojení nemá vliv H0B: b1=b2=0 kosení nemá vliv H0AB: g11=g12=g21=g22=0 není interakce
Dvoucestná ANOVA s interakcí • Model bez interakce: Xijk = m+ ai + bj + eijk • Přidáme-li interakci: Xijk = m+ ai + bj + gij + eijk • Interakce mezi faktory je symetrická, a tak nám říká buď: „velikost (případně i směr) vlivu hnojení závisí na tom, zda je plocha kosená nebo ne“ nebo „velikost (případně i směr) vlivu kosení závisí na tom, zda je plocha hnojená nebo ne“ • Speciální případ: “kosení má vliv jen u nehnojených ploch“ (můžeme vyjádřit i „hnojení má vliv jen u kosených ploch“)
Dvoucestná ANOVA s interakcí • Není interakce: • Je interakce: Hlavní efekt (main effect) Je třeba zdůraznit, že spojováníprůměrů tady není interpolací:jde nám o zobrazení interakcepomocí (ne)rovnoběžnosti čar Když popisuji výsledky, nestačí říct,že interakce je průkazná, musím uvéstproč (kde a jaká je odchylka od aditivity)
Méně častý typ interakce • Vliv 2 léků (A a B) na snížení teploty testován faktoriálním experimentem • Hlavní efekt léku A vyšel neprůkazný, hlavní efekt léku B také, ale vyšla průkazná interakce • Interaction plot vypadá takto: Výsledek neznamená,že by léky nebyly účinné! Jejich účinek se přispolečném podání ruší.
F statistika v dvoucestné ANOVAfaktory s pevným efektem • Fhnojeno, Fkoseno, Fhnojeno*koseno jsou všechny počítány dělením příslušného MS hodnotou MSError • Například: Fhnojeno=352.8/8.025 = 43.963 • Není tomu ale tak v případě faktorů s náhodným efektem!
Mnohonásobná porovnání • Ve faktoriální analýze variance (s 2 a více faktory) provádím obdobně jako ve one-way ANOVA • V našem příkladu nemá smysl: máme jen dvě hladiny pro každý z faktorů • Mohu porovnávat buď pro hlavní efekty nebo i pro interakci (tj. všechny faktoriálně vytvořené skupiny mezi sebou) • Co budu porovnávat rozhoduji já (ovšems ohledem na výsledky testu)
F statistika v dvoucestné ANOVAmixed effects (náhodný+pevný) • Zkoumám vliv kosení na druhovou bohatost, máme tři lokality, na každé mám tři kosené a tři nekosené plochy Fkoseno = MSkoseno / MSlokalita*koseno tj. 206.72 / 5.39
Experimentální uspořádání:1 – úplně znáhodněné • Máme experiment se 4 zásahy (K, Z1, Z2, Z3) a se 4 opakováními pro každý typ zásahu (= pro každou hladinu faktoru) • Je-li všech 16 ploch rozmístěno zcela náhodně (completely randomised design), hodnotím jednocestnou analýzou variance
Experimentální uspořádání:2 – zcela nesprávné • Vliv zásahu nelze v datech získanýchz tohoto špatného uspořádání odlišit od vlivu umístění v prostoru • Pojem pseudoreplikace (pseudoreplication)
Experimentální uspořádání:3 – znáhodněné bloky • Randomised blocks, ale pozor, někdy též jako Completely randomised blocks nebo randomized complete blocks! • Náhodný faktor Blok, two-way ANOVA bez interakce. Silnější test, pokud se bloky liší
Experimentální uspořádání:4 – Latinský čtverec • Latin square • Známe směry prostorové variability a buď je jen jeden (např. vlhkost) nebo jsou kolmé • 3-way ANOVA, náhodné fak. řádek a sloupec
Friedmanův test • Neparametrický test pro úplné znáhodnění bloky, ale na jiném principu než Wilcoxonův test (tady mi stačí hodnoty v rámci bloku seřadit, nepotřebuju tedy odečítat) • Založeno na pořadí hodnot (pro jednotlivé hladiny faktoru) uvnitř bloků a je počet hladin studovaného faktoru b je počet bloků Rije součet hodnot pořadí pro i-tou hladinu
Transformace: problémy s aditivitou 1 • Porovnávám výšky sedmikrásek a slunečnic a jejich odpověď na přidání živin • Faktoriální uspořádání, 2 faktory s pevným efektem a 2 hladinami (druh a živiny) • Tři testovatelné hypotézy (2 hlavní efekty plus interakce): • výška sedmikrásek a slunečnic se neliší • výška rostlin se mění po přidání živin • vliv přidání živin je stejný pro oba druhy
Transformace: problémy s aditivitou 2 • Lze očekávat heterogenitu variancí (hodnoty výšky budou mít asi větší varianci u slunečnic než u sedmikrásek) S.D. bude lineárně závislá na průměru (CV bude konstantní) • Interakce v ANOVA modelu testuje aditivitu, a tedy nárůst výšky díky přidání živin stejný(v cm) u obou druhů – např. 10 cm:
Transformace: problémy s aditivitou 3 • Taková aditivita ale neodpovídá „biologické realitě“ – lze spíše očekávat nárůst proporční, např. o 100% • Odpovídající model pro vliv druhu (slunečnice je 10-krát vyšší než sedmikráska; hnojení zvýší výšku 2-krát) je: • Chceme-li dostat model ANOVA, musíme logaritmovat • Tabulka logaritmů průměrných výšek pak vypadá takto:
Logaritmická transformace • Pokud byla v původních datech S.D. lineárně závislá na průměru, vede k homogenitě var. • Mění multiplikativní efekty na aditivní • Mění lognormální rozdělení e na normální • Problém s nulami: v biologických datech časté (pokryvnost či početnost druhu ve vzorku) • X’ = log(X+c), c by mělo odpovídat škále hodnot X (c=1 vhodné pro počty, procenta) • Přičtení c narušuje (někdy ne moc) převod multiplikativity na aditivitu
Jiné transformace • Předpokládáme-li pro závislou proměnnou Poissonovu distribuci: • Pro procenta a podíly (na škále 0 – 1):
Hierarchické uspořádání(nested design) • tři lokality • na každé lokalitě tři kytky • na každé pět měření • V příkladě je faktor Kytka jasně s náhodným efektem, u faktoru Lokalita si lze představit obě možnosti. Takto vypadají nejčastější případy hierarchické analýzy variance • Vyrovnanost počtu pozorování je i zde velmi důležitá
Hierarchické uspořádánípříklad s délkou trubky 2 • Při rozkladu sumy čtverců (SS) počítáme čtverce rozdílů každého pozorování (průměru) od jeho hierarchicky nejbližšího vyššího příslušného průměru • Jsou-li hierarchicky nižší efekty náhodné, je F statistikou poměr MS efektu a MS nejbližšího hierarchicky nižšího efektu
Nejčastější použitíhierarchické analýzy variance • Rozklad variability znaků mezi jednotlivé hierarchické úrovně (taxonomické / prostorové) • Často mne zajímá především hierarchicky nejvýše postavený faktor, podřazené faktory umožňují oddělení variability na nižších úrovních zvýšení síly testu Příklad: vliv pastvy – 6 ohrad: 3 + 3ale v každé 5 ploch (zachytí variabilitu uvnitř ohrad), z každé plochy 3 vzorky pro analýzy (zachytí variabilitu v biomase a v anal. metodě)
Pseudoreplikace ještě jednou • Pozor na směsné vzorky: umožní zprůměrovat „nezajímavou variabilitu“, ale ztrácí se nezávislost pozorování v nich zahrnutých vzorků! Ale pozor – směsné vzorky samy o sobě není nic špatmného, ale musí být replikované Tohle nejsou nezávislápozorování !!
Složitější modely ANOVA • Faktoriálně a hierarchicky uspořádané faktory se mohou různě kombinovat, přičemž některé budou s pevným a některé s náhodným efektem • (Tohle nechci ke zkoušce, ale bude se vám to hodit na diplomky apod. – V mnoha diplomkách si s tím, co jste se naučili v tomhle kursu nevystačíte.)
Split plot (main plots and split plots - two error levels) 6 polí (3 vápenec, 3 žula), na každém poli 3 typy zásahů
ANOVA - Repeated measures • Mám nějaké experimentální uspořádání, a každý objekt sleduji v průběhu času, např.