Download

1 / 23
230 likes | 373 Views
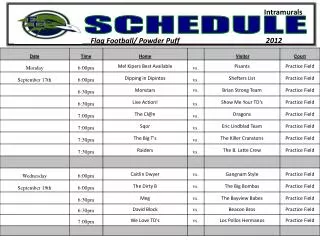
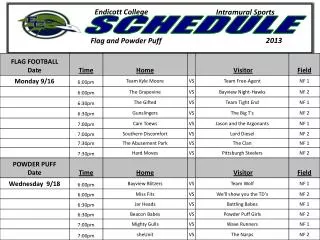
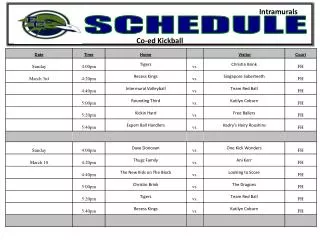
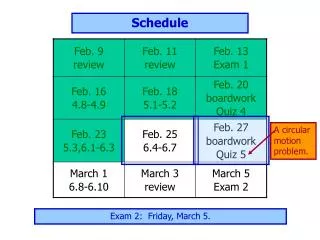
Schedule. 8 30 -9 00 Introduction 9 00 -10 00 Models: small cliques and special potentials 10 00 -10 30 Tea break 10 30 -12 00 Inference: Relaxation techniques: LP, Lagrangian , Dual Decomposition

E N D
Schedule 830-900Introduction 900-1000 Models: small cliques and special potentials 1000-1030Tea break 1030-1200Inference: Relaxation techniques: LP, Lagrangian, Dual Decomposition 1200-1230Models: global potentials and global parameters + discussion
MRF with global potentialGrabCut model [Rother et. al. ‘04] θF/B ∑ Fi(θF)xi+ Bi(θB)(1-xi) + ∑ |xi-xj| E(x,θF,θB) = i i,jЄN Fi = -log Pr(zi|θF) Bi= -log Pr(zi|θB) R Background Foreground G Image z Output x θF/B Gaussian Mixture models Problem: for unknown x,θF,θBthe optimization is NP-hard! [Vicente et al. ‘09]
GrabCut: Iterated Graph Cuts[Rother et al. Siggraph ‘04] θF/B F B min E(x, θF, θB) x min E(x, θF, θB) θF,θB Learning of the colour distributions Graph cut to infer segmentation Most systems with global variables work like that e.g. [ObjCut Kumar et. al. ‘05, PoseCutBray et al. ’06, LayoutCRF Winn et al. ’06]
GrabCut: Iterated Graph Cuts Guaranteed toconverge 1 3 4 2 Energy after each Iteration Result
Colour Model R R Background Background Iterated graph cut Foreground & Background G Foreground G
Optimizing over θ’s help no iteration [Boykov&Jolly ‘01] Input after convergence[GrabCut ‘04] after convergence[GrabCut ‘04] Input
Global optimality? GrabCut (local optimum) Global Optimum [Vicente et al. ‘09] Is it a problem of the optimization or the model?
… first attempt to solve it[Lempisky et al. ECCV ‘08] E(x,θF,θB)= ∑ Fi(θF)xi+ Bi(θB)(1-xi) + ∑ wij|xi-xj| R 5 4 3 wF,B 2 8 6 7 G 1 8 Gaussianswhole image Model a discrete subset:wF= (1,1,0,1,0,0,0,0); wB= (1,0,0,0,0,0,0,1) #solutions: wF*wB = 216 Global Optimum:Exhaustive Search: 65.536 Graph Cuts Branch-and-MinCut: ~ 130-500 Graph Cuts (depends on image)
Branch-and-MinCut wF= (*,*,*,*,*,*,*,*) wB= (*,*,*,*,*,*,*,*) wF= (0,0,*,*,*,*,*,*) wB= (0,*,*,*,*,*,*,*) wF= (1,1,1,1,0,0,0,0) wB= (1,0,1,1,0,1,0,0) min E(x,wF,wB) = min [ ∑ Fi(wF)xi+ Bi(wB)(1-xi) + ∑ wij(xi,xj) ]≥ min [∑ min Fi(wF)xi+ min Bi(wB)(1-xi) + ∑ wij(xi,xj)] x,wF,wB x,wF,wB x wF wB
Results … E=-624 (speed-up 481)Branch-and-MinCut E=-618GrabCut E=-593GrabCut E=-584 (speed-up 141)Branch-and-MinCut
Object Recognition & Segmentation w w = Templates x Position min E(x,w) with: |w| ~ 2.000.000 Given exemplar shapes: Test: Speed-up ~900; accuracy 98.8%
… second attempt to solve it[Vicente et al. ICCV ‘09] Eliminate global color model θF,θB : E’(x) = min E(x,θF,θB) θF,θB
Eliminate color model E(x,θF,θB)= ∑ Fi(θF)xi+ Bi(θB)(1-xi) + ∑ wij|xi-xj| K = 163 k Image discretized in bins Image histogram θF θB given x k k background distribution foreground distribution K K θFє [0,1]K is a distributions (∑θF = 1) (background same) Optimal θF/B given by empirical histograms: θF = nFk/nF nF= ∑xi#fgd. pixelnF= ∑xi#fgd. pixel in bin k K k k i ЄBk
Eliminate color model E(x,θF,θB)= ∑ Fi(θF)xi+ Bi(θB)(1-xi) + ∑ wij|xi-xj| i E(x,θF,θB)= ∑ -nFk log θFk-nBklog θBk + ∑ wij|xi-xj| k min θF,θB (θF = nFk/nF) K E’(x)= g(nF) + ∑hk(nF)+ ∑wij|xi-xj| with nF= ∑xi, nF= ∑xi k k k i ЄBk g concave hk convex max nF 0 n/2 n nF 0 k Each color either fore- or background Prefers “equal area” segmentation
How to optimize … Dual Decomposition E(x)= g(nF) + ∑hk(nFk) + ∑wij|xi-xj| k E1(x) E2(x) min E(x) = min [ E1(x) + yTx + E2(x) – yTx ] ≥ min [ E1(x’) + yTx’ ] + min [E2(x) – yTx] =: L(y) x x x’ x Robust Pn Potts Simple (no MRF) Goal: - maximize concave function L(y) using sub-gradient - no guarantees on E (NP-hard) E(x’) L(y) “paramtericmaxflow” gives optimal y=λ1 efficiently [Vicente et al. ICCV ‘09]
Some results… Global optimum in 61% of cases (GrabCut database) Input GrabCut Global Optimum (DD) Local Optimum (DD)
Insights on the GrabCut model g 0.3 g 0.4 g 1.5 g g convex concave hk 0 n/2 n nF max nF 0 k Prefers “equal area” segmentation Each color either fore- or background
Relationship to Soft Pn Potts Just different type of clustering: GrabCut:cluster all colors together another super-pixelization Image One super-pixelization Pairwise CRF onlyTextonBoost[Shotton et al. ‘06] robust Pn Potts [Kohli et al ‘08]
Marginal Probability Field (MPF) What is the prior of a MAP-MRF solution: 60% black, 40% white Training image: MAP: Others less likely : 8 5 3 • prior(x) = 0.6 * 0.4 = 0.005 • prior(x) = 0.6 = 0.016 • MRF is a bad prior since ignores shape of the (feature) distribution ! • Introduce a global term, which controls global statistic [Woodford et. al. ICCV ‘09]
Marginal Probability Field (MPF) max 0 True energy MRF Optimization done with Dual Decomposition (different ones) [Woodford et. al. ICCV ‘09] max 0
Examples In-painting: Noisy input Segmentation: Ground truth Pairwise MRF – Increase Prior strength Global gradient prior
Schedule 830-900Introduction 900-1000 Models: small cliques and special potentials 1000-1030Tea break 1030-1200Inference: Relaxation techniques: LP, Lagrangian, Dual Decomposition 1200-1230Models: global potentials and global parameters + discussion
Open Questions • Many exciting future directions • Exploiting latest ideas for applications (object recognition etc.) • Many other higher-order cliques:Topology, Grammars, etc. (this conference). • Comparison of inference techniques needed: • Factor graph message passing vs. transformation vs. LP relaxation? • Learning higher order Random Fields