Download
1 / 55
550 likes | 811 Views
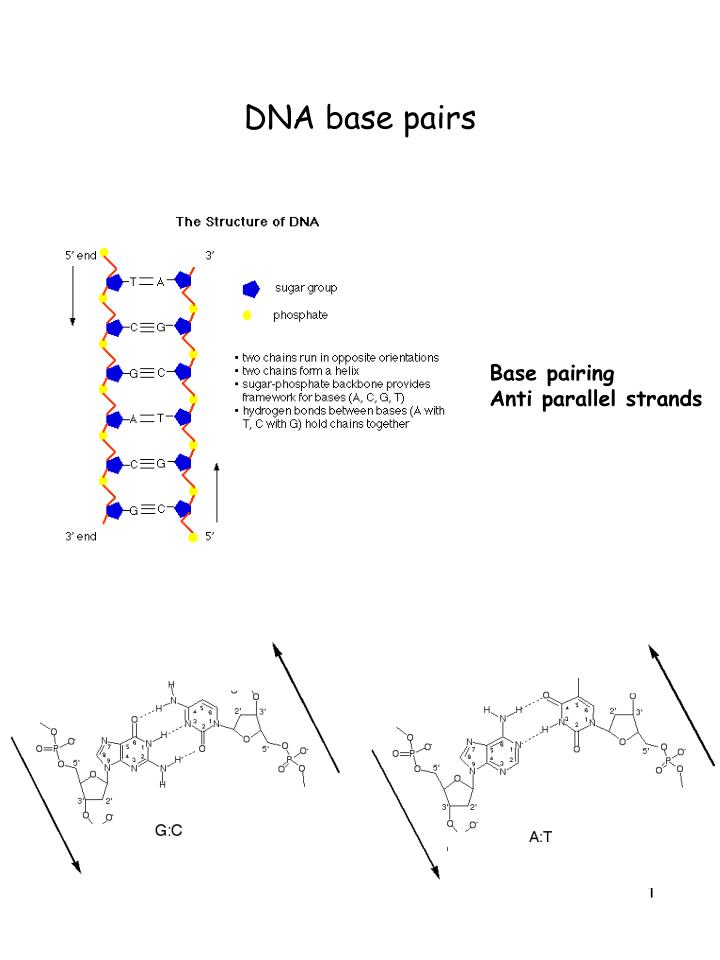
DNA base pairs. Base pairing Anti parallel strands. Base pairing. DNA sequence (5 ’ to 3 ’ ) Gene sequence Intergenic sequence. Eukaryotic Information Transfer: Transcription & Translation. ****Beadle and Tatum: Gene = polypeptide****. DNA. Protein.

E N D
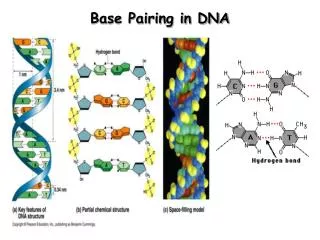
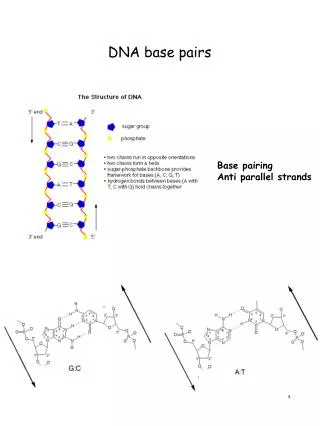
DNA base pairs Base pairing Anti parallel strands
Base pairing DNA sequence (5’ to 3’) Gene sequence Intergenic sequence
Eukaryotic Information Transfer:Transcription & Translation ****Beadle and Tatum: Gene = polypeptide**** DNA Protein
RNA serves as the intermediarybetween DNA and proteins Genes are in the nucleus Proteins are made in cytoplasm Although RNA and DNA are structurally analogous, Three major differences RNA DNA Most DNA is nuclear Most RNA is cytoplasmic
Transcription mRNA is an exact copy of a gene that is exported to the cytoplasm The synthesis of RNA by the enzyme RNA polymerase using DNA as the template is called transcription For each gene, only one of the two strands of DNA is transcribed
Transcription involves THREE distinct processes RNA polymerase catalyzes the synthesis of RNA using the DNA as a template RNA polymerase is a multi-protein complex It consists of four proteins in bacteria (E. coli) A GENE is a defined region of DNA It has a start, a body a end. Transcription Initiation Transcription Elongation 3) Transcription Termination
Initiation of Transcription Initiation involves RNA polymerase recognizing and binding to a specific sequence on the DNA The recognition sequence is called a PROMOTER PROMOTER 3’ 5’ antisense ----TTGACAT---------------TATAAT----------AT----ATG CCC GGG TTT TAA ----AACTGTA---------------ATATTA----------TA----TAC GGG CCC AAA ATT sense 3’ 5’ (-35) (15-17) (-10) The sequences are present in the promoters of most E. coli genes These sequences are conserved They are critical for proper functioning of the promoter What do we mean by conserved sequence? Regions of the DNA (gene or non-gene) or protein that share similar nucleotide sequence
Homology (molecular biology) Regions of the DNA (gene or non-gene) that share similar nucleotide sequence Sequence homology is a very important concept Structural homology (nucleotide sequence) implies functional homology Conservation of sequence = Conservation of function Genes with a similar sequence are likely to function in a similar manner (Homologous genes encode for similar proteins, which will have similar functions)
Consensus sequences of promoters ----TTGACAT---------------TATAAA----------AT----ATG CCC (-35) (-10) (+1) (15-17 bp) Homology is never perfect The sequence homology between genes is not usually perfect Once all the genes are aligned, the most common residue at each position is used to construct a consensus sequence M A R T K Q T A R K S T G G K A P R K Q L A T mouse H3 M A R T K Q T A R K S T G G K A P R K Q L A T Dros H3 M A R T K Q T A R K S T G V K A P R K Q L A T Tetra H3 M A R T K Q T A R K S T G G K A P R K Q L A S Yeast H3 M A R T K Q T A R K S T G G K A P R K Q L A T Consensus T C C G T T G G A C A T T G T T A G T C G C G - C T T G G T A T A A T C G G C FD8 C G T G T T G A C T A T T T T A C C T C T G G - - C G G T T A T A A T G G T C LPR T C C G C T T G A C A T C C T G A T T G C C G A C T C C C T A T A A A G C G C RRNX1 A A C G G T T G A C A A C A T G A A G T A A A - C A C G G T A T G A A G T G A T7A3 T C C G T T T G A C A T T X T G A X T C X C G - C T C G G T A T A A T G G G C Concensus
Consensus sequences of promoters ----TTGACAT---------------TATAAA----------AT----ATG CCC (-35) (-10) (+1) (15-17 bp) RNA polymerase Bacterial RNA polymerase Core enzyme: four polypeptide subunits: alpha (a), beta (b), beta' (b'), and omega (w) Stoichiometry : 2a:1b:1b’:1w Core RNA polymerase can bind to DNA It catalyzes the synthesis of RNA but it has no specificity. Holo Enzyme: The RNA polymerase holoenzyme contains an additional subunit - sigma (s). The sigma subunit does two things: It reduces the affinity of the enzyme for non-specific DNA. It greatly increases the affinity of the enzyme for promoters.
RNA polymerase RNA polymerase searches for the promoter RNA promoter binds the promoter and unwinds the DNA RNA polymerase synthesizes RNA
Promoter asymmetry and direction of transcription RNA chain length ranges from ~70 to 10,000 nucleotides The orientation of the promoter defines which DNA strand will be transcribed --TTGACAT---------------TATAAA----------AT--//-ATG CCC GGG TAA --AACTGTA---------------ATATTT----------TA--//-TAC GGG CCC ATT template Promoter sequence is asymmetrical and orients the binding of the polymerase
RNA is synthesized in 5’ to 3’ direction mRNA has the same sequence as the non-template strand Once the polymerase orientation is established only one DNA strand is read RNA chains are ONLY made in the 5’ to 3’ direction The template DNA strand is read in the opposite direction (3’ to 5’)
Gene orientations For each gene, RNA is transcribed from ONLY ONE DNA strand (template strand) However different genes may use different DNA strands Over the entire chromosome, different regions of both DNA strands will be Transcribed Orientation of genes is the direction in which they are transcribed
Transcription termination 5’ 3’ 5’ 3’ 3’ 5’ 3’ 5’ Termination of transcription also requires specific DNA sequences A protein, that associates with the RNA polymerase, recognizes this sequence This causes the polymerase to first pause and then dissociate from the DNA sense strand Upon termination, the RNA is released from the DNA Most terminators contain a region rich in GC bases followed by polyU tract. This adopts a hairpin structure in the RNA.
Eukaryotic RNA Prokaryotes have a single RNA polymerase This enzyme synthesizes mRNA, tRNA and rRNA Eukaryotes have three RNA polymerases RNA PolymeraseI----rRNA RNA polymeraseII---mRNA RNA polymeraseIII--tRNA RNA is synthesized in the nucleus This is the Primary transcript It is processed before being transported to the cytoplasm 5’ cap of 7-methylguanosine is added 3’ polyA tail is added: usually about 150-200 nucleotides long
Upstream elements TATA +/- These elements function to activate genes
Upstream element function Gene Inr TATA
Properties of Enhancers (and Silencers) Enhancers are orientation independent Enhancers are distance independent Enhancers can activate heterologous genes The enhancer acts as a unit that can be moved relative to the promoter Cooperative assembly of different factors Integrity of the element depends upon all/most of the factors Spacing of factor binding sites is important
TATA Mechanism of enhancer function • Most enhancers function within open chromatin domains • Transcriptional activators bind to enhancers • - Aid in recruitment of the general transcription machinery and assembly of the initiation complex • - Alter binding and/or function of other transcription factors • Alter rate of transcription initiation • - May aid in recruitment of enzymes that modify chromatin at the promoter
Sequence specific proteins bind sites and open the chromatin domain Model of enhancer function Architectural proteins help bend DNA via protein-protein interactions Stable enhanceosome formed with a distinct protein surface Enhanceosome surface interacts with complementary surface displayed by promoter bound complexes Interactions induce recruitment of PIC factors and stabilize binding of the factors Allowing multiple rounds of transcription
m1Gppp m1Gppp Processing DNA Primary transcript AAAA Splicing
Splicing Internal portions of the primary transcript are removed This is called splicing Regions of a gene that code for a protein are interrupted by regions called intervening sequences (introns) This was discovered by comparing the DNA sequence with the mature cytoplasmic mRNA sequence 1 2 3 4 5 6 7 Gene 7700 nt Ovalbumin Capping, polyA Splicing mRNA 1872 nt
Splicing Primary transcripts are a mosaic of exons and introns Exons are portions of the mRNA that are translated into protein Introns (intervening sequences) are segments of the primary Transcript that are removed or spliced out. The function of the intron is not known. Shuffling of exons allows genes to evolve Alternative splicing- Different related proteins are synthesized
Exon1 Exon2 Exon1 Exon2 Exon1 Exon2 Splicing Short sequences dictate where splicing occurs Exon1 PuPuGUPuPu--------------Py12-14AG Exon2 Splice donor Splice acceptor Splicing requires a enzyme complex called a spliceosome Consists of several small RNAs complexed with ~50 proteins The snRNA basepair with the splice donor and acceptor sites and are important for holding the two Exons together during splicing
Mechanism of silencer function Silencers generate inaccessible chromatin domains Silencers prevent binding of transcription factors Silencers prevent transcription They recruit repressors They recruit enzymes that modify chromatin Silencers are orientation independent Silencers are distance independent Silencers can repress heterologous genes The silencer acts as a unit that can be moved relative to the promoter
Ac Ac Ac Ac Ac Ac 1 Rap1 Rap1 Rap1 ORC ORC Rap1 ORC Rap1 ORC ORC Abf1 Abf1 Abf1 Abf1 Abf1 Ac Ac Ac Ac Ac Ac Ac Ac 2 2 2 1 4 1 1 4 4 3 3 Ac Ac Ac Ac Ac Ac Ac 2 1 4 3 Ac Ac Ac Ac Ac Ac Ac 2 4 2 2 2 2 2 2 4 4 4 3 Ac 3 4 3 4 4 3 3 Establishment of Silencing
Translation Translation is the production of a polypeptide whose amino acid sequence is derived from the nucleotide sequence of the mRNA mRNA is a simple linear molecule made of an array of FOUR different nucleotides Proteins are complex three dimensional structures made of arrays of 20 amino acids How do simple mRNA molecules specify complex proteins?
Genes, RNA, proteins Genes synthesize RNAs that are converted to proteins Genes also encode for RNAs that are NOT converted to proteins Two major classes of non-protein RNA tRNA = Transfer RNA rRNA = Ribosomal RNA
Adaptor hypothesis 1958 Crick analyzed how RNA made proteins There are 20 AA The previous models stated that the mRNA would adopt a Structural configuration forming 20 different cavities- one specific cavity for each AA. Crick discounted this:”……On physical-chemical grounds, the idea does not seem plausible” He went on ……”A natural hypothesis is that the amino acid is carried to the template (mRNA) by an adaptor. The adaptor fits onto the mRNA…. And in its simplest form the Hypothesis would require 20 adaptors (one for each amino acid). “What sort of molecule such adaptors might be is anybody’s guess One possibility more likely than any other - they contain nucleotides” “A separate enzyme would join each adaptor to each amino acid”
Proline Adaptor hypothesis GGG ||| AAACCCGGG tRNA molecules act as adaptors that translate the nucleotide sequence into protein sequence Each tRNA has two functional sites Each tRNA is covalently linked to one of the 20 amino acids (a tRNA that specifically carries the amino acid proline is called tRNA-pro) Each tRNA includes a specific loop (ANTI-CODON loop) that is used to read the mRNA
tRNA has a cloverleaf structure Even though RNA is single stranded and linear, the bases will pair with one another. Complementary bases within the tRNA can pair to form double-stranded regions. This leads to the tRNA adopting a secondary structure (primary structure of a tRNA is the linear nucleotide sequence) A complete description of all of these base-pairing associations is called the tRNA secondary structure. This structure is represented as a clover leaf The three dimensional tertiary structure of tRNA is an L-shaped configuration
Charged tRNA tRNA are synthesized from genes as RNA A specific amino acid is covalently attached to the 3’ end of the tRNA by a specific AA-tRNA synthase (the true translators) 20 synthase enzymes for the 20 amino acids This tRNA+AA is called a charged tRNA Pro
AA-tRNA synthase Gene tRNA Charged tRNA tRNA genes, tRNA and charged tRNA tRNA gene1 tRNA1 UAC anticodon Met-tRNA synthase Met-tRNA UAC tRNA gene2 tRNA2 AAA anticodon Phe-tRNA synthase Phe-tRNA AAA tRNA gene3 tRNA3 UUU anticodon Lys-tRNA synthase Lys-tRNA UUU mRNA AUG UUU AAA UAA ||| ||| ||| tRNA UAC AAA UUU AA Met Phe Lys STP
The mRNA sequence complementary to the tRNA anticodon is called a codon The sequence of aminoacids along a protein is specified by the anticodon-codon alignment Alignment is anti-parallel If anticodon is 3’CCU5’, complementary mRNA codon is 5’GGA3’ Codon-anticodon tRNA translate the sequence of nucleotides present in the mRNA into a sequence of amino acids in the protein.
A T G T T T A A A T A G C C C 5’ 3’ RNA A U G U U U A A A U A G C C C 5’ 3’ Reading the genetic code DNA C A T A A A T T T C T A G G G 3’ 5’
5’ 5’ 3’ 3’ A U G A U G U U U U U U A A A A A A U A G U A G C C C C C C A A A U U U U A C Lys Phe Met No Gaps S T P
5’ 5’ 3’ 3’ A U G A U G A A A A A A C C C C C C U A G U A G C C C C C C U U U G G G U A C Pro Lys Met No overlaps S T P
aa1 aa1 aa2 aa2 aa3 aa2 aa2 Protein synthesis is a stepwise process 5’ 5’ 3’ 3’ aa1 5’ 5’ 3’ 3’ aa1
Enzymes are required for protein synthesis Mixing mRNA with charged tRNA’s does not lead to protein synthesis The enzyme necessary for catalysis of protein synthesis is the RIBOSOME Ribosomes are complex enzymes made of more than 50 proteins and 3 RNA molecules The RNA molecules in ribosomes are called ribosomal RNA (rRNA) The Ribosome has several functional sites Peptidyl transferase P A E 3 tRNA binding sites mRNA binding site
Met Met Met Met Ala Ala Ala Ala Leu Leu Leu Leu Phe Phe Phe Phe Trp Trp Phe Trp Trp ACC ACC AAG AAG ACC AAA AAG ACC AAG STEPS 5’-----UUCUGG-----3’ 5’-----UUCUGG-----3’ 5’-----UUCUGG-----3’ 5’-----UUCUGGUUU--3’
Translation Initiation What about the first aminoacid? Does the ribosome start synthesis at the start of the mRNA? Translation of an mRNA by the ribosome always initiates at the INITIATION Codon- AUG AUG is normally recognized by a tRNA charged with the amino acid Methionine When an AUG occurs near the 5’ end of the mRNA (at a special initiation position), it is recognized by a special tRNA charged with N-formylmethionine = fMet
Special Initiation position (rRNA) UCCUCCA- 5’-----AGGAGGU--AUGUCUAUGACC-----3’ (mRNA) What is the special initiation position Most mRNAs will have more than one AUG codons. How is the initiation codon specified? Upstream (5’) of the start codon AUG is a sequence in the mRNA that is Complementary to a sequence in one of the ribosomal rRNAs Pairing of the ribosomal RNA with the mRNA serves to align the ribosome with the mRNA
Met Ala Leu Phe Trp ACC Translation termination The growing polypeptide chain is released when a stop codon is reached There are three stop codons: UAA UAG UGA These codons are not recognized by a tRNA They are recognized by a protein- Release factor. This causes the ribosome to release the mRNA and the newly synthesized polypeptide The release factor binds to the STOP codon 5’-----UGGUAA-----3’ (mRNA)
Homology (molecular biology) Regions of the DNA (gene or non-gene) that share similar nucleotide sequence Sequence homology is a very important concept Structural homology (nucleotide sequence) implies functional homology Conservation of sequence = Conservation of function Genes with a similar sequence are likely to function in a similar manner (Homologous genes encode for similar proteins, which will have similar functions)
Consensus sequences of promoters ----TTGACAT---------------TATAAA----------AT----ATG CCC (-35) (-10) (+1) (15-17 bp) Homology is never perfect The sequence homology between genes is not usually perfect Once all the genes are aligned, the most common residue at each position is used to construct a consensus sequence M A R T K Q T A R K S T G G K A P R K Q L A T mouse H3 M A R T K Q T A R K S T G G K A P R K Q L A T Dros H3 M A R T K Q T A R K S T G V K A P R K Q L A T Tetra H3 M A R T K Q T A R K S T G G K A P R K Q L A S Yeast H3 M A R T K Q T A R K S T G G K A P R K Q L A T Consensus T C C G T T G G A C A T T G T T A G T C G C G - C T T G G T A T A A T C G G C FD8 C G T G T T G A C T A T T T T A C C T C T G G - - C G G T T A T A A T G G T C LPR T C C G C T T G A C A T C C T G A T T G C C G A C T C C C T A T A A A G C G C RRNX1 A A C G G T T G A C A A C A T G A A G T A A A - C A C G G T A T G A A G T G A T7A3 T C C G T T T G A C A T T X T G A X T C X C G - C T C G G T A T A A T G G G C Concensus
Predicting Genes If you sequence a large region of DNA, how do you determine if the region codes for a protein or not? 5’ 3’ 3’ 5’ 5’ ATG GCC TAT GAG AAT TAATGA CCC GGG -- 5’ ATG GCC T ATG AGA ATT AAT GAC CCG GG-- Start codon = ATG Stop codon = UAA UAG UGA Start/Stop method 0 100 200 300 400 1 2 3 4 5 6