Download

1 / 185
1.86k likes | 1.99k Views
Cache & SpinLocks Udi & Haim. Agenda. Caching background Why do we need caching? Caching in modern desktop. Cache writing. Cache coherence. Cache & Spinlocks. Agenda. Concurrent Systems Synchronization Types Spinlock Semaphore Mutex Seqlocks RCU Spinlock in linux kernel

E N D
Agenda • Caching background • Why do we need caching? • Caching in modern desktop. • Cache writing. • Cache coherence. • Cache & Spinlocks
Agenda • Concurrent Systems • Synchronization Types • Spinlock • Semaphore • Mutex • Seqlocks • RCU • Spinlock in linux kernel • Caching and locking
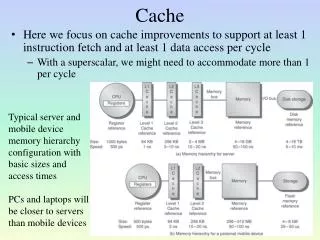
Why caching? • Accessing the main memory is expensive. • And is becoming the pc performance bottleneck. Slower CPU Faster CPU
Caching in modern desktop • What is caching? “A computer memory with very short access time used for storage of frequently used instructions or data” – webster.com Modern desktop have at least three caches: • TLB translation lookaside buffer • I-Cache instruction cache • D-Cache data cache
Caching in modern desktop • Locality • Temporal locality • Spatial locality • Cache coloring • Replacement policies • LRU • MRU • Direct Map cache • Cache performance = • The proportion of accesses that result in a cache hit
Cache writing There are two basic writing approaches: • Write-through • Write is done synchronously both to the cache and to the backing store. • Write-back (or Write-behind) • Initially, writing is done only to the cache. • The write to the backing store is postponed until the cache blocks containing the data are about to be modified/replaced by new content.
Cache writing Two approaches for situations of write-misses: • No-write allocate (aka Write around) • The missed-write location is not loaded to cache, and is written directly to the backing store. • In this approach, only system reads are being cached. • Write allocate (aka Fetch on write) • The missed-write location is loaded to cache, followed by a write-hit operation. • In this approach, write misses are similar to read-misses.
Cache coherence • Coherence defines the behavior of reads and writes to the same memory location.
Cache coherence • The coherence of caches is obtained if the following conditions are met: • In a read made by a processor P to a location X that follows a write by the same processor P to X, with no writes of X by another processor occurring between the write and the read instructions made by P, X must always return the value written by P. This condition is related with the program order preservation, and this must be achieved even in monoprocessed architectures. • A read made by a processor P1 to location X that follows a write by another processor P2 to X must return the written value made by P2 if no other writes to X made by any processor occur between the two accesses. This condition defines the concept of coherent view of memory. If processors can read the same old value after the write made by P2, we can say that the memory is incoherent. • Writes to the same location must be sequenced. In other words, if location X received two different values A and B, in this order, from any two processors, the processors can never read location X as B and then read it as A. The location X must be seen with values A and B in that order
Cache coherence • Cache coherence mechanisms • Directory-based • Snooping (BUS-based) • And many more ….
Cache coherence • Directory-based • In a directory-based system, the data being shared is placed in a common directory that maintains the coherence between caches. • The directory acts as a filter through which the processor must ask permission to load an entry from the primary memory to its cache. • When an entry is changed the directory either updates or invalidates the other caches with that entry.
Cache coherence • Snooping (BUS-based) • Snooping is the process where the individual caches monitor address lines for accesses to memory locations that they have cached. • It is called a write invalidate protocol when a write operation is observed to a location that a cache has a copy of. • There are two implementation for the invalidate protocol: • Write-update • When a local cache block is updated, the new data block is broadcast to all caches containing a copy of the block for updating them • Write-invalidate • Invalidate all remote copies of cache when a local cache block is updated.
Cache coherence Coherence protocol example: Write-invalidate Snooping Protocol For Write-through Writes invalidate all other caches
Cache coherence Write-invalidate Snooping Protocol For Write-back • When a block is first loaded in the cache it is marked "valid". • On a read miss to the local cache, the read request is broadcast on the bus. If one has cached that address and it is in the state "dirty", it changes the state to "valid" and sends the copy to requesting node. The "valid" state means that the cache line is current. • When writing a block in state "valid" its state is changed to "dirty" and a broadcast is sent out to all cache controllers to “invalidate” their copies.
Cache coherence - MESI MESI Modified Exclusive Shared Invalid
Cache coherence - MESI • Every cache line is marked with one of the four following states : • Modified - The cache line is present only in the current cache, and is dirty; it has been modified from the value in main memory. The cache is required to write the data back to main memory at some time in the future, before permitting any other read of the (no longer valid) main memory state. The write-back changes the line to the Exclusive state. • Exclusive - The cache line is present only in the current cache, but is clean; it matches main memory. It may be changed to the Shared state at any time, in response to a read request. Alternatively, it may be changed to the Modified state when writing to it. • Shared - Indicates that this cache line may be stored in other caches of the machine and is "clean" ; it matches the main memory. The line may be discarded (changed to the Invalid state) at any time. • Invalid - Indicates that this cache line is invalid (unused). • To summarize, the MESI is an extension of MSI algo. The MESI add’s division between modifying cache point the exist only in my cache AND modifying cache point the exist also in other caches
Cache coherence - MESI • For any given pair of caches, the permitted states of a given cache line are as follows: The Exclusive state is an opportunistic optimization: If the CPU wants to modify a cache line that is in state S, a bus transaction is necessary to invalidate all other cached copies. State E enables modifying a cache line with no bus transaction.
Cache • What is done by the OS and what is done by the hardware? • In Intel X86 series, caching is implement in hardware, all you need and can do it to change the configuration with registers interface called Control registers. • The control registers are sets in to 7 groups : CR0, CR1, CR2, CR3, CR4, • And another 2 groups called: EFER, CR8 (added to support X64 series) • Our main interest in the presentation revolved around caching, but bear in mind that this interface contain every parameter you can set on Intel architecture. • CR0 – CD (bit 30) Globally enables/disable the memory cache • CR0 – NW (bit 29) Globally enables/disable write-back caching (or write-throw) • flushing of TLB entries can be done in Linux using API called vpid_sync_context • The implementation is done by using: vpid_sync_vcpu_single or vpid_sync_vcpu_global for single or all Cpus
Caching & Spinlock
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret The other CPU action…
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and spin lock spin_lock: mov eax, [locked] test eax, eax jnz spin_lock mov eax, 1 xchg eax, [locked] test eax, eax jnz spin_lock ret spin_unlock: mov eax, 0 xchg eax, [locked] ret
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; } SPIN
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }
Caching and ticket lock void spin_lock(spinlock_t *lock){ t = atomic_inc(lock->next_ticket); while (t != lock->current_ticket) } void spin_unlock(spinlock_t *lock){ lock->current_ticket++; } struct spinlock_t { int current_ticket; int next_ticket; }