Download
1 / 12
120 likes | 280 Views
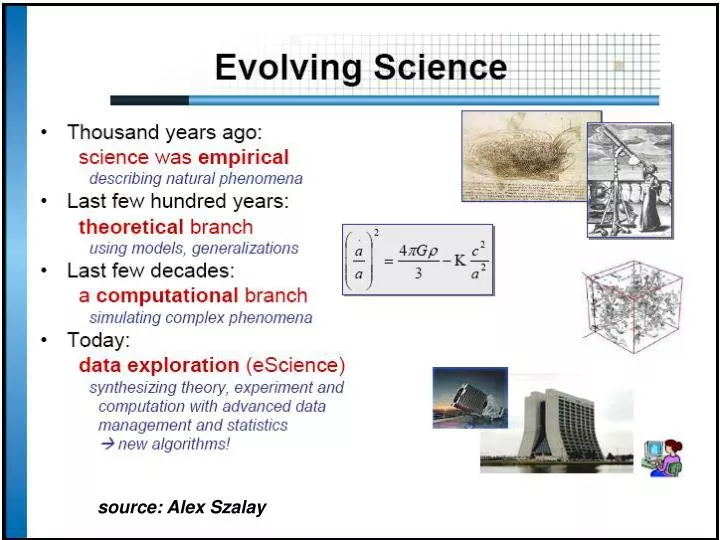
source: Alex Szalay. Example: Sloan Digital Sky Survey. The SDSS telescope array is systematically mapping ¼ of the entire sky Discoveries are made by querying the database , not through a zero-sum wrestling match for telescope time Managed by an RDBMS

E N D
Example: Sloan Digital Sky Survey The SDSS telescope array is systematically mapping ¼ of the entire sky Discoveries are made by querying the database, not through a zero-sum wrestling match for telescope time Managed by an RDBMS (MS SQL Server), equipped with a hierarchical triangular mesh index, among other customizations 15 TB in the final release in 2007 818 GB in the RDBMS (13.6B tuples)
Drowning in data; starving for information Empirical X Analytical X Computational X X-informatics Acquisition eventually outpaces analysis • Medicine: Online publishing, digital charts • Astronomy: Big telescopes (more in a bit) • Genetics: PCR, Shotgun Sequencing • Oceanography: ?? • Marine Microbiology: ?? “Increase Data Collection Exponentially in Less Time, with FlowCAM”
Cyber-Observatories • Arctic Observing Network (AON) • Ocean Observing Initiative (OOI) • National Ecological Observatory Network (NEON) • The Waters Network • The Long-Term Ecological Research (LTER) network • The Geosciences Network (GEON) • Earthscope/Incorporated Research Institutions for Seismology (IRIS) • Virtual Solar-Terrestrial Observatory (VSTO) • Linked Environments for Atmospheric Discovery (LEAD)
Relational Databases (In Codd we Trust…) At IBM Almaden in 60s and 70s, Ted Codd worked out a formal basis for tabular data representation, organization, and access1. The early systems were buggy and slow (and sometimes reviled), but programmers only had to write 5% of the code the previously did. Key Idea: Programs that manipulate tabular data exhibit an algebraic structure; proposed a relational algebra to manipulate these data sets in their logical form, indpendently of their physical representation phsyical data independence logical data independence 1 E. F. Codd, “A Relational Model of Data for Large Shared Data Banks”, Communications of the ACM 13(6), pp 377-387, 1970
Characteristicsof Cloud Computing • Virtual– Physical location and underlying infrastructure details are transparent to users • Scalable – Able to break complex workloads into pieces to be served across an incrementally expandable infrastructure • Efficient – “Services Oriented Architecture” for dynamic provisioning of shared compute resources • Flexible – Can serve a variety of workload types – both consumer and commercial
Cloud Computing as Hosted Data Management Services • Yahoo • Yahoo Distributed Hash Tables: Key/value pairs • Yahoo Distributed Ordered Tables: Ordered ranges • PNUTS: Relational-style storage, indexing and query • Amazon • S3: Simple Storage • SimpleDB: Quasi-Relational features • Google • APIs for: Storage, Visualization, Document processing, Images, Mail • Microsoft: • CloudDB: Relational-style features
Workflow at CMOP Washington University Cloud PNNL OHSU Cloning/ cDNA/… plates Sequencing FASTA files Inspection FASTA files e.g., trim bad reads at the end Cleaning BLAST Post processing Hit tables Link Analyze Hit tables + metadata synopsis Shared Knowledge




















