Download

1 / 17
170 likes | 289 Views
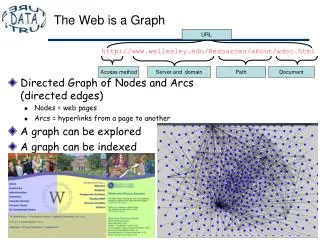
Web as a graph. Anna Karpovsky. Anna Karpovsky: Web Search and more accurate topic-classification algorithms, enumerating emergent cyber-communities. Motivation. Is Web graph really random? Can it be described by Erdos-Renyi or Watts-Strogatz Models?

E N D
Web as a graph Anna Karpovsky
Anna Karpovsky: Web Search and more accurate topic-classification algorithms, enumerating emergent cyber-communities Motivation • Is Web graph really random? • Can it be described by Erdos-Renyi or Watts-Strogatz Models? • Web graph is a fascinating object of study • Unregulated growth • Variety • Improved Web algorithms • Sociological information
Anna Karpovsky: They are both driven by the presence of certain structures in the Web graph. These structures appear to be fundamental by product of the manner in which Web content is created Outline • HITS algorithm + Trawling • Web graph properties • Random graph models
Anna Karpovsky: Power iteration to AAT, converge to principle eigenvalues, weights are intrinsic feature of collection of linked pages. Pages with large weights represent a very dense pattern of linkage form pages of large hub weight to pages of large authority weight. HITS Algorithm: revisited • Sampling step: • Root set (200 pages) • Base set (1000-3000 pages) • Weight-propagation step • Authority weight: • Hub weight: • Compact way:
Trawling Algorithm • Definitions: • Complete bipartite clique • Bipartite core • On any sufficiently well represented topic on the Web, there will be a bipartite core in the Web graph
Elimination-generation paradigm • Elimination • Necessary conditions – elimination filters • Generation • Identify barely-qualifying nodes – generation filter
Anna Karpovsky: The probability of finding documents with a large number if links is rather significant, the network connectivity being dominated by highly connected web pages. The probability of finding very popular addresses, to which a large number of other documents point, is a non-negligible, an indication of the flocking sociology of www. While the owner of each web page has completely freedom in choosing the number of links on a document and he addresses to which they point, the overall scaling laws characteristic only of highly interactive self-organized systems and critical phenomena Properties • Degree distribution • Prob(D=i) proportional to 1/i^a – power law • Prob of finding documents with a large number of links and finding very popular addresses is rather significant
Properties • Number of bipartite cores • Experiments generated well over 100,000 bipartite cores • Diameter of the web graph = 19 links
Random Graph Models • Erdos-Renyi Model • N nodes, each pair of nodes is connected with probability p • Watts-Strogatz Model • N nodes form regular lattice. With probability p, each edge is rewired randomly.
Traditional Random Graph Models • Random Graph • Degree distribution • Poisson or binomial • Number of bipartite cores • Negligible • Number of vertices • Fixed • Connectivity • Random and uniform
Anna Karpovsky: Intuition: author decides to create a new web page, more likely to choose larger topics. New viewpoint about the topic will probably link to many pages “within” the topic, but also probably introduce a new spin on the topic, linking to some new pages whose connection to the topic previously unrecognized Copying process • Create and delete nodes at random • Linear growth – links available right away • Exponential growth – only see the previous “epochs” of pages • With some probability, b, add k edges from v to random nodes • With probability 1-b, copy k edges from randomly chosen node to v • Two probabilistic processes: which to copy from and how many to copy
Anna Karpovsky: Power-law for degrees is an intrinsic feature, rather than emerging Do not explain large number of bipartite cliques observed in the web Not clear how to adopt to evolving graph ACL(Aiello, Chung, Lu) • Degree sequence is given by a power-law – fixes number of vertices and edges a is the logarithm of the size of the graph and b can be regarded as the log-log growth rate of the graph, y vertices of degree x • Set is constructed with as many copies of each vertex as its degree • Random matching in this set is chosen
Anna Karpovsky: Power law observed describes systems of different sizes at different stages of their development Scale-free Model • Preferential connectivity • Higher prob to be linked to a vertex that already has a large number of connections • (kj) = ki/kj • Independent of time
Analysis on number of cliques • Evolving copying models • There are many (t^) large cliques • Idea: Let vt’ called a leader if at least one of its d out-links is chosen uniformly. Let v be duplicator if it copies all d of its out-links. On each epoch there is some probability that at least one vertex copies from vt’. So can derive expected number of duplicators of vt’. vt’ and its duplicators form a complete bipartite subgraph.
Analysis on number of cliques • Evolving uniform model • Number of Cij is negligible for ij > i+j • Idea: observed out-degree = 7.2
Analysis on number of cliques • Cliques in the ACL model • Number of Cij is constant for i > 2/(-2) • Idea: Summing over all i-tuples and j-tuples of vertices, the probability that all the edges exist between them. We know: maximum degree of a vertex is given by exp(/) (0<= logy = - logx) and the probability that a vertex has degree d is given by exp()/d^ .
Comments • Links are not invariant in time • Documents are not stable • Hierarchical structure of the web pages