Download

1 / 31
310 likes | 487 Views
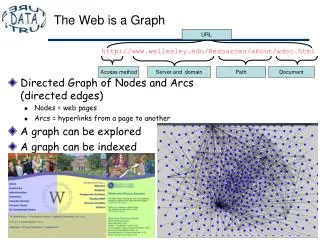
The Web as a graph. 末次 寛之 清水 伸明. 目標. www のリンク構造をグラフ化し, HIT , Hab & Authority , PageRank 等の アルゴリズムを利用して,解析する. Hubs & Authorities. Hubs Authorities. Hubs & authorities. Hubs Authorities. The HITS algorithm. 1 a sampling step 探したいクエリに対して関係すると思われる web ページを約200探す

E N D
The Web as a graph 末次 寛之 清水 伸明
目標 wwwのリンク構造をグラフ化し, HIT,Hab & Authority,PageRank等の アルゴリズムを利用して,解析する
Hubs&Authorities Hubs Authorities
Hubs&authorities Hubs Authorities
The HITS algorithm 1 a sampling step • 探したいクエリに対して関係すると思われるwebページを約200探す • その200のページからリンクを何度かたどり1000~3000のページを集める
The HITS algorithm 2 a weight-propagation step • sampling stepで集めたサイトを隣接行列にしhubやAuthorityにweightをつけていく • hubやAuthorityを見つける
Hubs&Authorities 高い 高い Hubs weight Authorities weight 低い 低い
Updated of hubs and authority Non-negative authority weight : Xp Non-negative hub weight :Yp (each page p∈V) Xp = ΣYq ←authority weight increased Yp = ΣXq ← hub weight increased q→p q→p
Update hubs and authority A : adjacency matrix (隣接行列) x = (x1,x2,…,xN) y = (y1,y2,…,yN) x = A y ←update rule y = Ax ←update rule x ← A y← A Ax = (A A)x y ← Ax← AA y = (AA )y T T T T T T
Hubs & Authorities 1 0 1 1 0 2 0 0 1 1 3 0 0 0 1 4 0 0 0 0 adjacency matrix (隣接行列) 1 3 A = 2 4
Hubs & Authorities 1 2 0 1 1 0 1 2 2 0 0 1 1 1 3 1 0 0 0 1 1 4 0 0 0 0 0 1 Hub authority Weight weight 1 3 = 2 4
Hubs & Authorities 1 0 0 0 0 0 2 2 2 1 0 0 0 2 3 4 1 1 0 0 1 4 3 0 1 1 0 0 authority Hub weight weight 1 0 0 0 0 2 1 0 0 0 3 1 1 0 0 4 0 1 1 0 = 1 3 T A 2 4 =
Authorities weight 0 0 0 0 0 1 1 0 0 1 2 1 0 0 1 2 0 0 0 0 1 61 19 6 2 1 136 42 13 4 1 108 33 10 3 1 1 3 T A A = 2 4 … ← ← ← ← ←
Authority Weightの正規化 Authority Weight が無意味に増大しないように毎回の正規化(Hub Weightについても同様) Authority weight a Initialize a = (1,…1) For I = 0,1,2,… ai+1 = A A a i Normalize a s.t. || ai+1||=1 → → T → → T → →
検索エンジンの種類 • ロボット型 ロボットがWEB上を自動的に巡回してwebページを収集し、データベースを作成する • ディレクトリ型エディタ、サーファーなどと呼ばれる人間の閲覧者がwebサイトを審査し、ユーザーにとって有益であると認めたサイトをデータベースに登録する • 複合型ロボット型とディレクトリ型を複合して検索を行う ほとんどの検索エンジンポータルで、使われている
ロボット型検索エンジンの運営プロセス • クローラー(スパイダー)と呼ばれるプログラムがWWW上のドキュメントを自動的に巡回する • クローラーで集めた情報をインデクサと呼ばれるプログラムでデータベース(インデックス)を作成する • 与えられてた検索キー(クエリ)に対して、検索アルゴリズムに従ってデータベースの中を検索し、与えられた検索キーに対する適合度の高い順にURLをリストする
-PageRank- 50 100 54 50 4 12 50 4 4 ページAからページBへのリンクをページAからページBへの支持投票とみなし その票数からそのページの重要度(PageRank)を算出する
-PageRank- web pageをノード,hyper-linkを有向辺とし www全体を有向グラフとみなす Rank(v):vのPageRank Rank(u):ページvへのリンクをもつのuのPageRank Nu : ページ u からの外向きのリンク数 Bv : vを指しているページの集合 i : 更新の回数 u1 u2 v u3
-PageRank- web pageをノード,hyper-linkを有向辺として www全体を有向グラフとみなす 初期値を1 A0 1 B0 1 C0 1 A C = B
-PageRank- 1.リンク先に重要度を均等に分配 2.分配された和を重要度として更新 Ai+1 1/2 0 1/2 Ai Bi+1 0 0 1/2 Bi Ci+1 1/2 1 0 Ci 1.Aは重要度をAとBに均等に分配 2.Ai+1 = 1/2 Ai+1 + 1/2 Ci+1 A B = C
-PageRank- i = 0 初期値 = 1 均等に分配 A=1 B=1 C=1
-PageRank- i = 1 1/2 分配された和を 均等に配分 A=1 1/2 1/2 B=1/2 1 C=3/2 1/2
-PageRank- i = 2 1/2 分配された和を 均等に配分 A=5/4 3/4 1/2 B=3/4 1/2 C=1 3/4
-PageRank- i = 3 5/8 分配された和を 均等に配分 A=8/9 1/2 5/8 B=1/2 3/4 C=11/8 1/2
-PageRank- i = 4 9/16 分配された和を 均等に配分 A=5/4 11/16 9/16 B=11/16 1/2 C=17/16 11/16
-PageRank- A0 1 B0 1 C0 1 Ai+1 1/2 0 1/2 Ai Bi+1 0 0 1/2 Bi Ci+1 1/2 1 0 Ci Ai 6/5 5/4 9/8 5/4 1 1 Bi 3/5 11/16 1/2 3/4 1/2 1 Ci6/5 17/16 11/8 1 3/2 1 = A B = C lim … = i→∞
-PageRank- Ai+1 1/2 0 1/2 Ai Bi+1 0 0 1/2 Bi Ci+1 1/2 0 0 Ci Ai 0 1/2 5/8 3/4 1 1 Bi 3 35/16 2 7/4 3/2 1 Ci0 5/16 3/8 1/2 1/2 1 Spider Trap A B = 1 C lim … = i→∞
-PageRank- Ai+1 1/2 0 1/2 Ai Bi+1 0 0 1/2 Bi Ci+1 1/2 0 0 Ci Ai 0 1/2 5/8 3/4 1 1 Bi 0 3/16 1/4 1/4 1/2 1 Ci0 5/16 3/8 1/2 1/2 1 Dead End A B = C 0 lim … = i→∞
-PageRank- Ai+1 1/2 0 1/2 Ai 1 Bi+1 (1-tax) 0 1 1/2 Bi +tax 1 Ci+1 1/2 0 0 Ci 1 sample tax = 0.2 Ai 7/11 1 Bi 21/11 1 Ci5/11 1 = Dead End 効果の回避 税金の再配分 Spider Trapの回避 重要度の1部を 税金として徴収 lim … = i→∞
-PageRank- Rank(v):vのPageRank Rank(u):ページvへのリンクをもつのuのPageRank Nu : ページ u からの外向きのリンク数 Bv : vを指しているページの集合 N : ノードの総数 c : dampening factor (通常0.1~0.2に設定) i : 更新の回数