Download

1 / 11
110 likes | 223 Views
Web Graph Characteristics. Kira Radinsky. All of the following slides are courtesy of Ronny Lempel (Yahoo!). The Web as a Graph. Pages as graph nodes, hyperlinks as edges. Sometimes sites are taken as the nodes Some natural questions: Distribution of the number of in-links to a page.

E N D
Web Graph Characteristics Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!)
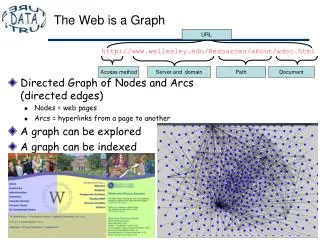
The Web as a Graph Pages as graph nodes, hyperlinks as edges. • Sometimes sites are taken as the nodes Some natural questions: • Distribution of the number of in-links to a page. • Distribution of the number of out-links from a page. • Distribution of the number of pages in a site. • Connectivity: is it possible to reach most pages from most pages? • Is there a theoretical model that fits the graph?
Mathematical Background:Power-Law Distributions • A non-negative random variable X is said to have a Power-Law distribution if, for some constants c>0 and α>0: Prob[X>x] ~ x-α,or equivalently f(x) ~ x-(α+1) • Taking logs from both sides, we have: log Prob[X>x] = -αlog(x) + c • Power Law distributions have “heavy/long tails”, i.e. the probability mass of events whose value is far from the expectancy or median of the distribution is significant • Unlike Normal or Geometric/Exponential distributions, where the probability mass of the tail decreases exponentially, in Power Law distributions the mass of the tail decreases by the constant power of α • Another point of view: in an Exponential distribution, f(x)/f(x+k) is constant, whereas in a Power-Law distribution, f(x)/f(kx) is constant. • The “average” quantity in a Power-Law distribution is not “typical” • Examples of Power-Law distributions are Pareto and Zipf distributions (see next slides)
Mathematical Background:The Pareto Distribution • A continuous, positive random variable X in the range [L,] is said to be distributed Pareto(L,k) if its probability density function is: f(X=x;k;L) = k Lk / xk+1 • This implies that Prob(X>x) = (L/x)k • Has finite expectancy of Lk/(k-1) only for k>1 • Has finite variance only for k>2 • Named after the Italian economist Vilfredo Pareto (1848-1923), who modeled with it the distribution of wealth in society • Most people have little income; 20% of society holds 80% of the wealth
Mathematical Background:Zipf’s Law • A random variable X follows Zipf’s Law (is “Zipfian”) with parameter α when the j’th most popular value of X occurs with probability that is proportional to j-α • Essentially the distribution is over the discrete ranks • Whenever α>1, X may take an infinite number of values (i.e. have infinitely many different value popularities) • Named after the American Linguist George Kingsley Zipf (1902-1950), who observed it on the frequencies of words in the English language • On a large corpus of English text, the 135 most frequently occurring words accounted for half of the text
Mathematical Background:An Observed Zipfian Sample Implies a Power-Law The following analysis is due to LadaAdamic: • Assume that N units of wealth (coins) are distributed to M individuals • There are N observations of a random variable Y that can take on the discrete values 1,2,…,M • Yk=j (k=1,…N, j=1..M) means that person j got coin k • Denote by X1[Xm] the number of coins of the richest[poorest] individual at the end of the process • For simplicity, assume that N>>M and the Xj’s are all distinct • Assume that a perfect Zipfian behavior is observed, i.e. Xr/N ~ r-b for all r=1,…M • This trivially implies Xr ~ r-b
Mathematical Background:An Observed Zipfian Sample Implies a Power-Law (cont.) • Recap: we distributed N coins to M individuals, and denoted by X1[Xm] the number of coins of the richest[poorest] individual at the end of the process • By assuming Zipfian wealth: Xr ~ r-b, or Xr=cr-b • Let Z be the random variable of a person’s wealth, i.e. the number of coins a person gets by this process • Observation: if the r’th richest person got Xr coins, then exactly r people out of M got Xr coins or more • Pr[Z Xr]=Pr[Z cr-b]=r/M • Define y= cr-b, and so r=(y/c)-(1/b), and so Pr[Z y]= y-(1/b) c(1/b)/M • Hence Pr[Z y] ~ y-(1/b), and Z obeys a Power-Law
Distribution of Inlinks A plot of the number of nodes having each value of in-degree Both axes are in log-scale Denoting the size of the sample crawl by N (over 200M here), we have: Log (N*Prob[node has in-degree x]) -a*log(x)+c Log (Prob[node has in-degree x]) -a*log(x)+c’ Which indicates the Power-Law Prob[node has in-degree x] ~ x-a Note that the number of nodes with small in-degree is over-estimated while the number of nodes with very high in-degree is under-estimated * Image taken from “Graph Structure in the Web”, Broder et al., WWW’2000.
More Power-Laws on the Web We’ve seen that the in-degree of pages exhibits a Power-Law. Furthermore: • Out-degree (somewhat surprising) • Degrees of the inter-host graph • Number of pages in Web sites • Number of visits to Web sites/pages • PageRank scores • With an exponent very close to that of the in-degree distribution • Curiously, degrees in the telephone call graph have the same 2.1 exponent • Frequencies of words (as observed by Zipf) • Popularities of queries submitted to search engines (will be discussed later in the course)
The Web as a Graph Connectivity: is it possible to reach most pages from most pages? The Web is a bow-tie! The Web graph is also scale-free, fractal: many slices and subgraphs exhibit similar properties. Image taken from “Graph Structure in the Web”, Broder et al., WWW’2000.
Self-Similarity on the WebDill et al., ACM TOIT 2002 • Created large Thematically Unified Clusters (TUCs) • Pages containing a certain keyword • Pages of large Web sites/Intranets • Pages containing a geographical reference in the Western US • The host graph • In general, the TUCs display very similar graph properties, e.g. • In/out degree distributions • Bow-tie structure (relative sizes of the components) • Also discovered that the SCC of the different TUCs are strongly connected, i.e. it is possible to browse between the TUCs