Download

1 / 272
2.72k likes | 2.74k Views
Explore the memory hierarchy including caches, virtual memory, and disk storage technologies. Learn about Dynamic RAM, magnetic disks, reliability issues, disk failure rates, and more. Understand the role of memory organization in technology systems.

E N D
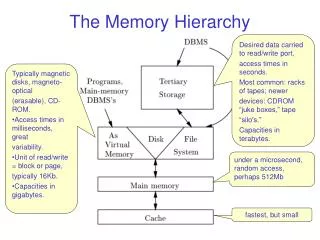
THE MEMORY HIERARCHY Jehan-François Pâris jfparis@uh.edu
Chapter Organization • Technology overview • Caches • Cache associativity, write through andwrite back, … • Virtual memory • Page table organization, the translation lookaside buffer (TLB), page fault handling, memory protection • Virtual machines • Cache consistency
Dynamic RAM • Standard solution for main memory since 70's • Replaced magnetic core memory • Bits represented stored on capacitors • Charged state represents a one • Capacitors discharge • Must be dynamically refreshed • Achieved by accessing each cell several thousand times each second
Dynamic RAM Row select nMOS transistor ColumnSelect Capacitor Ground
Row select (gate) ColumnSelect (source) drain Not on the exam The role of the nMOS transistor • Normally, no current can go from the source to the drain • When the gate is positive with respect to the ground, electrons are attracted to the gate (the "field effect")and current can go through
Magnetic disks Servo Platter Arm R/W head
Magnetic disk (I) • Data are stored into circular tracks • Tracks are partitioned into a variable number of fixed-size sectors • Ifdisk drive has more than one platter, all tracks corresponding to the same position of the R/ W head form a cylinder
Magnetic disk (II) • Disk spins at a speed varying between • 5,400 rpm (laptops) and • 15,000 rpm (Seagate Cheetah X15, …) • Accessing data requires • Positioning the head on the right track: • Seek time • Waiting for the data to reach the R/W head • On the average half a rotation
Disk access times • Dominated by seek time and rotational delay • We try to reduce seek times by placing all data that are likely to be accessed together on nearby tracks or same cylinder • Cannot do as much for rotational delay • On the average half a rotation
Overall performance • Disk access times are still dominated by rotational latency • Were 8-10 ms in the late 70's when rotational speeds were 3,000 to 3,600 RPM • Disk capacities and maximum transfer rates have done much better • Pack many more tracks per platter • Pack many more bits per track
The internal disk controller • Printed circuit board attached to disk drive • As powerful as the CPU of a personal computer of the early 80's • Functions include • Speed buffering • Disk scheduling • …
Reliability issues • Disk drives have more reliability issues than most other computer components • Moving parts eventually wear • Infant mortality • Would be too costly to produceperfect magnetic surfaces • Disks have bad blocks
Disk failure rates • Failure rates follow a bathtub curve • High infantile mortality • Low failure rate during useful life • Higher failure rates as disks wear out
Disk failure rates (II) Failurerate Wearout Infantilemortality Useful life Time
Disk failure rates (III) • Infant mortality effect can last for months for disk drives • Cheap ATA disk drives seem to age less gracefully than SCSI drives
MTTF • Disk manufacturers advertise very highMean Times To Fail (MTTF) for their products • 500,000 to 1,000,000 hours, that is,57 to 114 years • Does not mean that disk will last that long! • Means that disks will fail at an average rate of one failure per 500,000 to 100,000 hours duringtheir useful life
More MTTF Issues (I) • Manufacturers' claims are not supported by solid experimental evidence • Obtained by submitting disks to a stress test at high temperature and extrapolating results to ideal conditions • Procedure raises many issues
More MTTF Issues (II) • Failure rates observed in the field aremuch higher • Can go up to 8 to 9 percent per year • Corresponding MTTFs are 11 to 12.5 years • If we have 100 disks and a MTTF of 12.5 years, we can expect an average of 8 disk failures per year
Bad blocks (I) • Also known as • Irrecoverable read errors • Latent sector errors • Can be caused by • Defects in magnetic substrate • Problems during last write
Bad blocks (II) • Disk controller uses redundant encoding that can detect and correct many errors • When internal disk controller detects a bad block • Marks it as unusable • Remaps logical block address of bad block tospare sectors • Each disk is extensively tested duringburn in period before being released
The memory hierarchy (II) • To make sense of these numbers, let us consider an analogy
Major issues • Huge gaps between • CPU speeds and SDRAM access times • SDRAM access times and disk access times • Both problems have very different solutions • Gap between CPU speeds and SDRAM access times handled by hardware • Gap between SDRAM access times and disk access times handled by combination of software and hardware
Why? • Having hardware handle an issue • Complicates hardware design • Offers a very fast solution • Standard approach for very frequent actions • Letting software handle an issue • Cheaper • Has a much higher overhead • Standard approach for less frequent actions
Will the problem go away? • It will become worse • RAM access times are not improving as fast as CPU power • Disk access times are limited by rotational speed of disk drive
What are the solutions? • To bridge the CPU/DRAM gap: • Interposing between the CPU and the DRAM smaller, faster memories that cache the data that the CPU currently needs • Cache memories • Managed by the hardware and invisible to the software (OS included)
What are the solutions? • To bridge the DRAM/disk drive gap: • Storing in main memory the data blocks that are currently accessed (I/O buffer) • Managing memory space and disk space as a single resource (Virtual memory) • I/O buffer and virtual memory are managed by the OS and invisible to the user processes
Why do these solutions work? • Locality principle: • Spatial locality:at any time a process only accesses asmall portion of its address space • Temporal locality:this subset does not change too frequently
Can we think of examples? • The way we write programs • The way we act in everyday life • …
The technology • Caches use faster static RAM (SRAM) • Similar organization as that of D flipflops • Can have • Separate caches for instructions and data • Great for pipelining • A unified cache
A little story (I) • Consider a closed-stack library • Customers bring book requests to circulation desk • Librarians go to stack to fetch requested book • Solution is used in national libraries • Costlier than open-stack approach • Much better control of assets
A little story (II) • Librarians have noted that some books get asked again and again • Want to put them closer to the circulation desk • Would result in much faster service • The problem is how to locate these books • They will not be at the right location!
A little story (III) • Librarians come with a great solution • They put behind the circulation desk shelves with 100 book slots numbered from 00 to 99 • Each slot is a home for the most recently requested book that has a call number whose last two digits match the slot number • 3141593 can only go in slot 93 • 1234567 can only go in slot 67
A little story (IV) Let me see if it's in bin 93 The call number of the book I need is 3141593
A little story (V) • To let the librarian do her job each slot much contain either • Nothing or • A book and its reference number • There are many books whose reference number ends in 93or any two given digits
A little story (VI) Sure Could I get this time the book whose call number 4444493?
A little story (VII) • This time the librarian will • Go bin 93 • Find it contains a book with a different call number • She will • Bring back that book to the stacks • Fetch the new book
Basic principles • Assume we want to store in a faster memory 2n words that are currently accessed by the CPU • Can be instructions or data or even both • When the CPU will need to fetch an instruction or load a word into a register • It will look first into the cache • Can have a hit or a miss
Cache hits • Occur when the requested word is found in the cache • Cache avoided a memory access • CPU can proceed
Cache misses • Occur when the requested word is not found in the cache • Will need to access the main memory • Will bring the new word into the cache • Must make space for it by expelling one of the cache entries • Need to decide which one
Handling writes (I) • When CPU has to store the contents of a register into main memory • Write will update the cache • If the modified word is already in the cache • Everything is fine • Otherwise • Must make space for it by expelling one of the cache entries
Handling writes (II) • Two ways to handle writes • Write through: • Each write updates both the cache and the main memory • Write back: • Writes are not propagated to the main memory until the updated word is expelled from the cache
Write through Write back CPU Cache RAM Handling writes (II) CPU Cache later RAM