Download

1 / 5
50 likes | 146 Views
Performance Profiling of NGS Genome A ssembly A lgorithms. Alex Ropelewski Pittsburgh Supercomputing Center ropelews@psc.edu 412-268-4960. NGS: Assembly Algorithm. de Bruijn Graph. ALIGNED 3-MERS ATG TGG GGC GCG CGT GTG TGC GCA CAA

E N D
Performance Profiling ofNGS Genome Assembly Algorithms Alex Ropelewski Pittsburgh Supercomputing Center ropelews@psc.edu 412-268-4960
NGS: Assembly Algorithm de Bruijn Graph ALIGNED 3-MERS ATG TGG GGC GCG CGT GTG TGC GCA CAA AAT 1.ATG AT TG 10.AAT 2.TGG AA GG 6.GTG 7.TGC 3.GGC 9.CAA CA GC 8.GCA 4.GCG Genome: ATGGCGTGCAAT GT CG 5.CGT Assembled Genome via Eulerian Cycle (reads represented as edges)
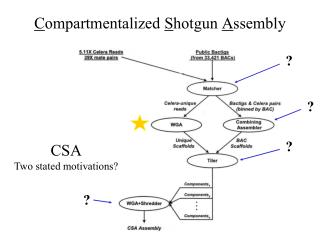
Program characteristics • 2 codes of interest: • Allpaths-LG: designed for assembling large genomes (Mostly C++, pipeline uses make) • Velvet: used frequently for small genomes (written in C; uses some OpenMP) • Both codes are: • memory intensive • time intensive • have some parallelization
Desired Profile Information • For each program/step in the assembly pipeline: • Time and Memory consumption • Identification of serial and parallel steps • Quantify I/O characteristics • Quantify how many times each step is run • For the most time consuming and most called programs/steps: • Time consumed by each function • How many times is each function called • Quantify I/O characteristics • Identify parallel steps and examine scaling • Describe the main memory consumers
General Outcome • Where should the optimization effort be focused? • Are there serial optimizations? • Additional candidates for parallelization? • Can the existing parallelization be improved? • Can the IO be improved? • Memory performance issues to address? • Something else?