Download

1 / 74
740 likes | 754 Views
This paper discusses the use of graphics hardware to solve compute-intensive problems, focusing on the example of Singular Value Decomposition (SVD) on the GPU. The paper explores the benefits and challenges of utilizing the GPU for high-performance computing and proposes a hybrid algorithm for SVD computation.

E N D
Sheetal Lahabar and P. J. Narayanan Center for Visual Information Technology, IIIT - Hyderabad Exploiting the Graphics Hardware to solve two compute intensive problems
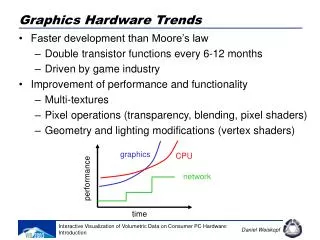
General-Purpose Computation on GPUs Why GPGPU? • Computational Power • Pentium 4: 12 GFLOPS, GTX 280: 1 TFLOPS • High Performance Growth: Faster than Moore's law • CPU: 1.4x, GPU: 1.7x ~ 2.3x for every year • Disparity in performance: CPU(caches and branch prediction), GPU(arithmetic intensity) • Flexible and precise • Programmability • High-level language support • Economics • Gaming market
The Problem: Difficult to use • GPUs are designed for and driven by graphics • Model is unusual & tied to graphics • Environment is tightly constrained • Underlying architectures • Inherently parallel • Rapidly evolving • Largely secret • Can’t simply “port” code written for the CPU!
Mapping Computations to GPU • Data-parallel processing • GPU architecture is ALU-heavy • Performance depends on • Arithmetic intensity = Computation / Bandwidth ratio • Hide memory latency with more computation
Singular Value Decomposition on the GPU using CUDA Proceedings of IEEE International Parallel Distributed Processing Symposium(IPDPS 09), 25-29 May, 2009, Rome, Italy
Problem Statement SVD of matrix A(mxn)for m>n U and V are orthogonal and Σis a diagonal matrix
Motivation • SVD has many applications in Image Processing, Pattern Recognition etc. • High computational complexity • GPUs have high computing power • Teraflop performance • Exploit the GPU for high performance
Related Work • Ma et al. implemented two sided rotation Jacobi on 2 million gate FPGA (2006) • Yamamoto et al. proposed a method on CSX600 (2007) • Only for large rectangular matrices • Bobda et al. proposed a implemention on Distributed reconfigurable system (2001) • Zhang Shu et al. implemented One Sided Jacobi • Works for small matrices • Bondhugula et al. proposed a hybrid implementation on GPU • Using frame buffer objects
Methods • SVD algorithms • Golub Reinsch (Bidiagonalization and Diagonalization) • Hestenes algorithm(Jacobi) • Golub Reinsch method • Simple and compact • Maps well to the GPU • Popular in numerical libraries
Golub Reinsch algorithm • Bidiagonalization: • Series of householder transformations • Diagonalization: • Implicitly Shifted QR iterations
SVD • Overall algorithm • B ← QTAP Bidiagonalization of A to B • Σ← XTBY Diagonalization of B to Σ • U ← QX , V T ← (PY ) T Compute orthogonal matrices U andV T • Complexity: O(mn2) for m>n
Bidiagonalization Simple Bidiagonalization QT A P As QT ith update A(i+1:m, i+1:n) = A(i+1:m, i+1:n) – uif(ui,vi ) - f(vi)vi QT(i:m, 1:m) = QT(i:m, 1:m) – f(Q,ui)ui P(1:n, i:n) = P(1:n, i:n) – f(P,vi)vi Identity matrix
Contd… • Many Reads and writes • Use block updates • Divide matrix into n/L blocks • Eliminate L rows and columns at once • n/L block transformations
Contd… • A Block transformation, L=3 QT A P ith block transformation updates trailing A(iL+1:m, iL+1:n), Q(1:m, iL+1:m) and PT(iL+1:n, 1:n) Update using BLAS operations L
Contd… • Final bidiagonal matrix B = QTAP • Store Lui’s and vi’s • Additional space complexity O(mL) • Partial Bidiagonalization only computes B
Challenges • Iterative algorithm • Repeated data transfer • High precision requirements • Irregular data access • Matrix size affects performance
Bidiagonalization on GPU • Block updates require Level 3 BLAS • CUBLAS functions used, single precision • High performance for smaller dimension • Matrix dimension are multiple of 32 • Operations on data local to the GPU • Expensive GPU CPU transfers avoided
Contd… • Inplace bidiagonalization • Efficient GPU implementation • Bidiagonal matrix copied to the CPU
Diagonalization • Implicitly shifted QR algorithm Iteration 1 Iteration 2 k1 k1 k2 k2 XBYT Identity matrix
Diagonalization • Apply implicitly shifted QR algorithm • In every iteration, until convergence • Find matrix indexes k1and k2 • Apply Given’s rotations on B • Store coefficient vectors (C1, S1) and (C2, S2) of length k2-k1 • Transform k2-k1+1 rows of YT using (C1, S1) • Transformk2-k1+1 columns of X using (C2, S2)
Contd… • Forward transformation on YT C1S1 j=0 j=1 j=2 YT for(j=k1; j<k2; j++) YT(j,1:n) =f (YT(j,1:n), YT(j+1,1:n), C1(j-k1+1), S1(j-k1+1)) YT(j+1,1:n) = g (YT(j,1:n), YT(j+1,1:n), C1(j-k1+1), S1(j-k1+1))
Diagonalization on GPU • Hybrid algorithm • Given rotations modifies B on CPU • Transfer coefficient vectors to GPU • Row transformations • Transform k2-k1+1 rows of YT and XT on GPU
Contd… • A row element depends on next or previous row element • A row is divided into blocks blockDim.x tx ty=0 m k1 Bn B1 Bk n k2
Contd… • Kernel modifies k2-k1+1 rows • Kernel loops over k2-k1 rows • Two rows in shared memory • Requires k2-k1+1 coefficient vectors • Coefficient vectors copied to shared memory • Efficient division of rows • Each thread works independently
Orthogonal matrices • CUBLAS matrix multiplication for U and VT • Good performance even for small matrices
Results • Intel 2.66 Ghz Dual Core CPU used • Speedup on NVIDIA GTX 280: • 3-8 over MKL LAPACK • 3-60 over MATLAB
Contd… • CPU outperforms for smaller matrices • Speedup increases with matrix size
Contd… • SVD timing for rectangular matrices (m=8K) • Speedup increases with varying dimension
Contd… • SVD of upto 14K x 14K on Tesla S1070 takes 76 mins on GPU • 10K x 10K SVD takes 4.5 hours on CPU, 25.6 minutes on GPU
Contd… • Yamamoto achieved a speedup of 4 on CSX600 for very large matrices • Bobda report the time for 106 x 106 matrix which takes 17 hours • Bondhugula report only the partial bidiagonalization time
Timing for Partial Bidiagonalization • Speedup:1.5-16.5 over Intel MKL • CPU outperforms for small matrices • Timing comparable to Bondhugula e.g 11 secs on GTX 280 compared to 19 secs on 7900 Time in secs
Timing for Diagonalization • Speedup:1.5-18 over Intel MKL • Maximum Occupancy: 83% • Data coalescing achieved • Performance increases with matrix size • Performs well even for small matrices Time in secs
Limitations • Limited double precision support • High performance penalty • Discrepancy due to reduced precision m=3K, n=3K
Contd… • Max singular value discrepancy = 0.013% Average discrepancy < 0.00005% • Average discrepancy < 0.001% for U and VT • Limited by device memory
SVD on GPU using CUDA Summary • SVD algorithm on GPU • Exploits the GPU parallelism • High performance achieved • Bidiagonalization using CUBLAS • Hybrid algorithm for diagonalization • Error due to low precision < 0.001% • SVD of very large matrices
Ray Tracing Parametric Patches on GPU
Problem Statement • Direct ray trace parametric patches • Exact point of intersection • High visual quality images • Less artifacts • Fast preprocessing • Less memory requirement • Better rendering
Motivation • Describes 3D geometrical figures • Foundation of most CAD systems • Computationally expensive process • Graphics Processing Units (GPU) • High Computational Power, 1 TFLOPS • Exploit the Graphics hardware
Bezier patch • 16 control points • Better continuity properties, compact • Difficult to render directly • Tessellated to polygons • Patch equation Q(u, v) = [u3u2 u 1] P [v3 v2 v 1]T
Methods • Uniformly refine on the fly • Expensive tests to avoid recursion • Approximates to triangles • Rendering artifacts • Find exact hit point of a ray with a patch • High computational complexity • Prone to numerical errors
Related Work • Toth’s algorithm (1985) • Applies multivariate Newton iteration • Dependent on calculation of interval extension; numerical errors • Manocha’s and Krishnan’s method (1993) • Algebraic pruning based approaches • Eigen value formation of the problem • Does not map well to GPU • Kajiya’s method (1982) • Finds roots of a 18-degree polynomial • Maps well to parallel architectures
Kajiya’s algorithm l1 a b P l0 R v - Intersect a and b u - gcd(a,b)
Advantages • Finds the exact point of intersection • Uses robust root finding procedure • No memory overhead required • Requires double precision arithmetic • Able to trace secondary rays • On the downside; computationally expensive • Suitable for parallel implementation • Can be implemented on GPU
Overview of ray tracing algorithm Traverse BVH for all pixels/rays (GPU) Create BVH (CPU) Every frame Compute Plane Equations (GPU) Preprocessing For all intersections Compute 18 degree polynomials (GPU) Spawn Secondary Rays (GPU) Find the roots of the polynomials (GPU) Accumulate shading data recursively and render Compute point and normal (GPU) Compute the GCD of bicubic polynomials (GPU)
Compute Plane Equations • M+N planes represent MxN rays • Thread computes a plane equation • Use frustum corner information • Device occupancy: 100% Pixel Eye
BVH traversal on the GPU • Create BVH, traverse depth first • Invoke traverse, scan, rearrange • Store Num_Intersect intersection data • Device occupancy: 100% (x,y) rearrange 4,5 4,6 5,5 5,6 4 4 4 4 5 5 5 5 traverse pixel_x 0 2 3 4 5 5 5 6 5 5 6 6 1 4 5 pixel_y 2 3 1 2 2 0 1 2 2 3 4 4 5 Sum scan patch_ID 0 3 4 6 Prefix_Sum
Computing the 18 degree polynomial • Intersection of a and b • 32 A and B coefficients • Evaluate R = [a b c; b d e; c e f] for v • bezout kernel • grid = Num_Intersect/16, threads = 21*16 • 6-6 degree, 6-12 degree, 3-18 degree 16 Threads active 19*21 Threads active 21*16 Threads active 13*16 21
Contd… • Configuration uses resources well • Avoids uncoalesced read and write • Row major layout • Reduced divergence • Device occupancy: 69% • Performance limited by registers
Finding the polynomial roots • 18 roots using Laguerre’s method • Guarantees convergence • Iterative and cubically convergent • Thread evaluates an intersection • grid = Num_Intersect/64, threads = 64 • Kernel invoked from the CPU while(i < 18) call <laguerre> kernel, finds ith root xi call <deflate> kernel, deflates polynomial by xi End • Iteration update: xi = xi – g(p(x), p’(x)) • Each invocation finds a root in the block • Store real v count in d_countv