Download
1 / 43
440 likes | 635 Views
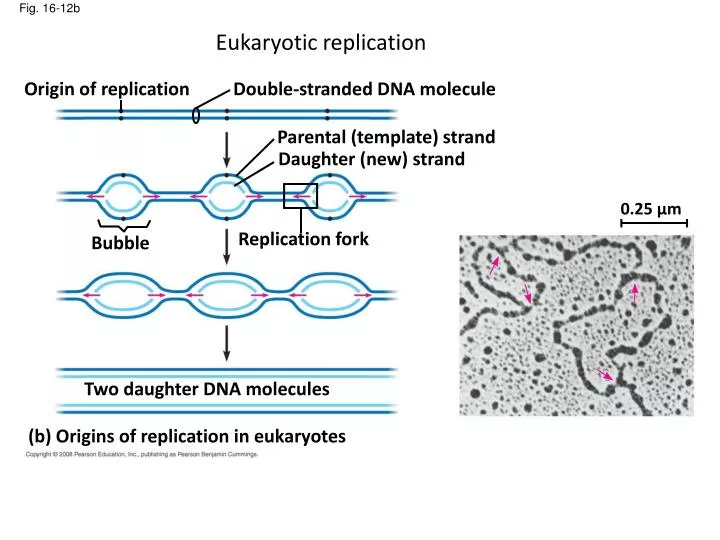
Eukaryotic replication. Origin of replication. Double - stranded DNA molecule. Parental (template ) strand. Daughter (new ) strand. Fig. 16-12b. 0.25 µm. Replication fork. Bubble. Two daughter DNA molecules. ( b ) Origins of replication in eukaryotes. 5 .

E N D
Eukaryotic replication Origin of replication Double-stranded DNA molecule Parental (template) strand Daughter (new) strand Fig. 16-12b 0.25 µm Replication fork Bubble Two daughter DNA molecules (b) Origins of replication in eukaryotes
5 Ends of parental DNA strands Leading strand Lagging strand 3 Last fragment Previous fragment RNA primer Lagging strand 5 Fig. 16-19 3 Parental strand Removal of primers and replacement with DNA where a 3 end is available 5 3 Second round of replication 5 New leading strand 3 5 New lagging strand 3 Further rounds of replication Shorter and shorter daughter molecules
5 Ends of parental DNA strands Leading strand Lagging strand 3 Last fragment Previous fragment RNA primer Lagging strand 5 Fig. 16-19 3 Parental strand Removal of primers and replacement with DNA where a 3 end is available 5 3 Second round of replication 5 New leading strand 3 5 New lagging strand 3 Further rounds of replication Shorter and shorter daughter molecules
Staining of telomeres Florescence In Situ Hybridization (FISH) Fig. 16-20 1 µm “probe” = (5’-CTAACC-3’)100
5 end Hydrogen bond 3 end 1 nm 3.4 nm Fig. 16-7a 3 end 0.34 nm 5 end (a) Key features of DNA structure (b) Partial chemical structure
Fig. 16-21a Nucleosome (10 nm in diameter) DNA double helix (2 nm in diameter) H1 Histone tail Histones DNA, the double helix Histones Nucleosomes, or “beads on a string” (10-nm fiber)
Chromatid (700 nm) 30-nm fiber Fig. 16-21b Loops Scaffold 300-nm fiber Replicated chromosome (1,400 nm) 30-nm fiber Looped domains (300-nm fiber) Metaphase chromosome
What are genes? DNA How do genes work? Mutant phenotypes Short aristae Cinnabar eyes Vestigial wings Brown eyes Black body 0 48.5 57.5 67.0 104.5
What are genes? DNA How do genes work? A gene specifies the action of an enzyme (The “one-gene, one-enzyme” hypothesis) 1909- Garrod -“Inborn errors of metabolism in man” e.g. Alkaptonuria: presence of alkapton in urine due to lack of enzyme -underappreciated at the time…. 1942- Beadle and Tatum - Genetic studies in Bread Mold (Neurospora) show that biochemical reactions are controlled by genes
Wild type Neurospora grows on minimal media Complete media (contains amino acids, nucleotides, vitamins, etc.) Minimal Media (lacks amino acids, nucleotides, vitamins, etc.)
A wt B Complete media • X-rays • Set up 1000 multiple single spore cultures (in complete media) C
A A Min. media wt B B Complete media Min. media Complete media • X-rays • Set up 1000 multiple single spore cultures (in complete media) • Test each for growth on minimal media C C Min. media Minimal Media
A A A A A A A A Min. media Min. media Min. media Min. media Min. media Min. media Min. media +Lys +Val +Arg +Phe +Trp +His +Leu A A A A A A A • X-rays • Set up 1000 multiple single spore cultures (in complete media) • Test each for growth on minimal media • Retest on minimal media plus one component Min. media Min. media Min. media Min. media Min. media Min. media Min. media +Gln +Cys +Asn +Gly +Tyr +Asp +Glu A A A A A A Min. media Min. media Min. media Min. media Min. media Min. media +Ile +Met +Pro +Ala +Ser +Thr
Multiple enzymes are required for argininebiosynthesis CONCLUSION Class Imutants (mutation in gene A) Class IImutants (mutation in gene B) Class IIImutants (mutation in gene C) Wild type Fig. 17-2c Precursor Precursor Precursor Precursor Gene A Enzyme A Enzyme A Enzyme A Enzyme A Ornithine Ornithine Ornithine Ornithine Gene B Enzyme B Enzyme B Enzyme B Enzyme B Citrulline Citrulline Citrulline Citrulline Gene C Enzyme C Enzyme C Enzyme C Enzyme C Arginine Arginine Arginine Arginine
Multiple enzymes are required for argininebiosynthesis CONCLUSION Class Imutants (mutation in gene A) Class IImutants (mutation in gene B) Class IIImutants (mutation in gene C) Wild type Fig. 17-2c Precursor Precursor Precursor Precursor Gene A Enzyme A Enzyme A Enzyme A Enzyme A Ornithine Ornithine Ornithine Ornithine Gene B Enzyme B Enzyme B Enzyme B Enzyme B Citrulline Citrulline Citrulline Citrulline Gene C Enzyme C Enzyme C Enzyme C Enzyme C Arginine Arginine Arginine Arginine If we have an Argrequiring mutant, which gene is affected?
RESULTS Classes of Neurospora crassa Wild type Class IIImutants Class Imutants Class IImutants Minimal medium (MM) (control) Fig. 17-2b MM + ornithine Condition MM + citrulline MM + arginine (control)
CONCLUSION Class Imutants (mutation in gene A) Class IImutants (mutation in gene B) Class IIImutants (mutation in gene C) Wild type Fig. 17-2c Precursor Precursor Precursor Precursor Gene A Enzyme A Enzyme A Enzyme A Enzyme A Ornithine Ornithine Ornithine Ornithine Gene B Enzyme B Enzyme B Enzyme B Enzyme B Citrulline Citrulline Citrulline Citrulline Gene C Enzyme C Enzyme C Enzyme C Enzyme C Arginine Arginine Arginine Arginine
DNA Protein RNA Replication Transcription Translation
Fig. 17-3a-1 DNA TRANSCRIPTION mRNA (a) Bacterial cell
Fig. 17-3a-2 DNA TRANSCRIPTION mRNA Ribosome TRANSLATION Polypeptide (a) Bacterial cell
E. Coli LacZ DNA sequence (1 strand shown)- 3075 base pairs ATGACCATGATTACGGATTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCAACTTAATCGCCTTGCAGCACATCCCCCTTTCGCCAGCTGGCGTAATAGCGAAGAGGCCCGCACCGATCGCCCTTCCCAACAGTTGCGCAGCCTGAATGGCGAATGGCGCTTTGCCTGGTTTCCGGCACCAGAAGCGGTGCCGGAAAGCTGGCTGGAGTGCGATCTTCCTGAGGCCGATACTGTCGTCGTCCCCTCAAACTGGCAGATGCACGGTTACGATGCGCCCATCTACACCAACGTGACCTATCCCATTACGGTCAATCCGCCGTTTGTTCCCACGGAGAATCCGACGGGTTGTTACTCGCTCACATTTAATGTTGATGAAAGCTGGCTACAGGAAGGCCAGACGCGAATTATTTTTGATGGCGTTAACTCGGCGTTTCATCTGTGGTGCAACGGGCGCTGGGTCGGTTACGGCCAGGACAGTCGTTTGCCGTCTGAATTTGACCTGAGCGCATTTTTACGCGCCGGAGAAAACCGCCTCGCGGTGATGGTGCTGCGCTGGAGTGACGGCAGTTATCTGGAAGATCAGGATATGTGGCGGATGAGCGGCATTTTCCGTGACGTCTCGTTGCTGCATAAACCGACTACACAAATCAGCGATTTCCATGTTGCCACTCGCTTTAATGATGATTTCAGCCGCGCTGTACTGGAGGCTGAAGTTCAGATGTGCGGCGAGTTGCGTGACTACCTACGGGTAACAGTTTCTTTATGGCAGGGTGAAACGCAGGTCGCCAGCGGCACCGCGCCTTTCGGCGGTGAAATTATCGATGAGCGTGGTGGTTATGCCGATCGCGTCACACTACGTCTGAACGTCGAAAACCCGAAACTGTGGAGCGCCGAAATCCCGAATCTCTATCGTGCGGTGGTTGAACTGCACACCGCCGACGGCACGCTGATTGAAGCAGAAGCCTGCGATGTCGGTTTCCGCGAGGTGCGGATTGAAAATGGTCTGCTGCTGCTGAACGGCAAGCCGTTGCTGATTCGAGGCGTTAACCGTCACGAGCATCATCCTCTGCATGGTCAGGTCATGGATGAGCAGACGATGGTGCAGGATATCCTGCTGATGAAGCAGAACAACTTTAACGCCGTGCGCTGTTCGCATTATCCGAACCATCCGCTGTGGTACACGCTGTGCGACCGCTACGGCCTGTATGTGGTGGATGAAGCCAATATTGAAACCCACGGCATGGTGCCAATGAATCGTCTGACCGATGATCCGCGCTGGCTACCGGCGATGAGCGAACGCGTAACGCGAATGGTGCAGCGCGATCGTAATCACCCGAGTGTGATCATCTGGTCGCTGGGGAATGAATCAGGCCACGGCGCTAATCACGACGCGCTGTATCGCTGGATCAAATCTGTCGATCCTTCCCGCCCGGTGCAGTATGAAGGCGGCGGAGCCGACACCACGGCCACCGATATTATTTGCCCGATGTACGCGCGCGTGGATGAAGACCAGCCCTTCCCGGCTGTGCCGAAATGGTCCATCAAAAAATGGCTTTCGCTACCTGGAGAGACGCGCCCGCTGATCCTTTGCGAATACGCCCACGCGATGGGTAACAGTCTTGGCGGTTTCGCTAAATACTGGCAGGCGTTTCGTCAGTATCCCCGTTTACAGGGCGGCTTCGTCTGGGACTGGGTGGATCAGTCGCTGATTAAATATGATGAAAACGGCAACCCGTGGTCGGCTTACGGCGGTGATTTTGGCGATACGCCGAACGATCGCCAGTTCTGTATGAACGGTCTGGTCTTTGCCGACCGCACGCCGCATCCAGCGCTGACGGAAGCAAAACACCAGCAGCAGTTTTTCCAGTTCCGTTTATCCGGGCAAACCATCGAAGTGACCAGCGAATACCTGTTCCGTCATAGCGATAACGAGCTCCTGCACTGGATGGTGGCGCTGGATGGTAAGCCGCTGGCAAGCGGTGAAGTGCCTCTGGATGTCGCTCCACAAGGTAAACAGTTGATTGAACTGCCTGAACTACCGCAGCCGGAGAGCGCCGGGCAACTCTGGCTCACAGTACGCGTAGTGCAACCGAACGCGACCGCATGGTCAGAAGCCGGGCACATCAGCGCCTGGCAGCAGTGGCGTCTGGCGGAAAACCTCAGTGTGACGCTCCCCGCCGCGTCCCACGCCATCCCGCATCTGACCACCAGCGAAATGGATTTTTGCATCGAGCTGGGTAATAAGCGTTGGCAATTTAACCGCCAGTCAGGCTTTCTTTCACAGATGTGGATTGGCGATAAAAAACAACTGCTGACGCCGCTGCGCGATCAGTTCACCCGTGCACCGCTGGATAACGACATTGGCGTAAGTGAAGCGACCCGCATTGACCCTAACGCCTGGGTCGAACGCTGGAAGGCGGCGGGCCATTACCAGGCCGAAGCAGCGTTGTTGCAGTGCACGGCAGATACACTTGCTGATGCGGTGCTGATTACGACCGCTCACGCGTGGCAGCATCAGGGGAAAACCTTATTTATCAGCCGGAAAACCTACCGGATTGATGGTAGTGGTCAAATGGCGATTACCGTTGATGTTGAAGTGGCGAGCGATACACCGCATCCGGCGCGGATTGGCCTGAACTGCCAGCTGGCGCAGGTAGCAGAGCGGGTAAACTGGCTCGGATTAGGGCCGCAAGAAAACTATCCCGACCGCCTTACTGCCGCCTGTTTTGACCGCTGGGATCTGCCATTGTCAGACATGTATACCCCGTACGTCTTCCCGAGCGAAAACGGTCTGCGCTGCGGGACGCGCGAATTGAATTATGGCCCACACCAGTGGCGCGGCGACTTCCAGTTCAACATCAGCCGCTACAGTCAACAGCAACTGATGGAAACCAGCCATCGCCATCTGCTGCACGCGGAAGAAGGCACATGGCTGAATATCGACGGTTTCCATATGGGGATTGGTGGCGACGACTCCTGGAGCCCGTCAGTATCGGCGGAATTCCAGCTGAGCGCCGGTCGCTACCATTACCAGTTGGTCTGGTGTCAAAAATAA
E. Coli LacZ RNA sequence - 3075 nucleotides AUGACCAUGAUUACGGAUUCACUGGCCGUCGUUUUACAACGUCGUGACUGGGAAAACCCUGGCGUUACCCAACUUAAUCGCCUUGCAGCACAUCCCCCUUUCGCCAGCUGGCGUAAUAGCGAAGAGGCCCGCACCGAUCGCCCUUCCCAACAGUUGCGCAGCCUGAAUGGCGAAUGGCGCUUUGCCUGGUUUCCGGCACCAGAAGCGGUGCCGGAAAGCUGGCUGGAGUGCGAUCUUCCUGAGGCCGAUACUGUCGUCGUCCCCUCAAACUGGCAGAUGCACGGUUACGAUGCGCCCAUCUACACCAACGUGACCUAUCCCAUUACGGUCAAUCCGCCGUUUGUUCCCACGGAGAAUCCGACGGGUUGUUACUCGCUCACAUUUAAUGUUGAUGAAAGCUGGCUACAGGAAGGCCAGACGCGAAUUAUUUUUGAUGGCGUUAACUCGGCGUUUCAUCUGUGGUGCAACGGGCGCUGGGUCGGUUACGGCCAGGACAGUCGUUUGCCGUCUGAAUUUGACCUGAGCGCAUUUUUACGCGCCGGAGAAAACCGCCUCGCGGUGAUGGUGCUGCGCUGGAGUGACGGCAGUUAUCUGGAAGAUCAGGAUAUGUGGCGGAUGAGCGGCAUUUUCCGUGACGUCUCGUUGCUGCAUAAACCGACUACACAAAUCAGCGAUUUCCAUGUUGCCACUCGCUUUAAUGAUGAUUUCAGCCGCGCUGUACUGGAGGCUGAAGUUCAGAUGUGCGGCGAGUUGCGUGACUACCUACGGGUAACAGUUUCUUUAUGGCAGGGUGAAACGCAGGUCGCCAGCGGCACCGCGCCUUUCGGCGGUGAAAUUAUCGAUGAGCGUGGUGGUUAUGCCGAUCGCGUCACACUACGUCUGAACGUCGAAAACCCGAAACUGUGGAGCGCCGAAAUCCCGAAUCUCUAUCGUGCGGUGGUUGAACUGCACACCGCCGACGGCACGCUGAUUGAAGCAGAAGCCUGCGAUGUCGGUUUCCGCGAGGUGCGGAUUGAAAAUGGUCUGCUGCUGCUGAACGGCAAGCCGUUGCUGAUUCGAGGCGUUAACCGUCACGAGCAUCAUCCUCUGCAUGGUCAGGUCAUGGAUGAGCAGACGAUGGUGCAGGAUAUCCUGCUGAUGAAGCAGAACAACUUUAACGCCGUGCGCUGUUCGCAUUAUCCGAACCAUCCGCUGUGGUACACGCUGUGCGACCGCUACGGCCUGUAUGUGGUGGAUGAAGCCAAUAUUGAAACCCACGGCAUGGUGCCAAUGAAUCGUCUGACCGAUGAUCCGCGCUGGCUACCGGCGAUGAGCGAACGCGUAACGCGAAUGGUGCAGCGCGAUCGUAAUCACCCGAGUGUGAUCAUCUGGUCGCUGGGGAAUGAAUCAGGCCACGGCGCUAAUCACGACGCGCUGUAUCGCUGGAUCAAAUCUGUCGAUCCUUCCCGCCCGGUGCAGUAUGAAGGCGGCGGAGCCGACACCACGGCCACCGAUAUUAUUUGCCCGAUGUACGCGCGCGUGGAUGAAGACCAGCCCUUCCCGGCUGUGCCGAAAUGGUCCAUCAAAAAAUGGCUUUCGCUACCUGGAGAGACGCGCCCGCUGAUCCUUUGCGAAUACGCCCACGCGAUGGGUAACAGUCUUGGCGGUUUCGCUAAAUACUGGCAGGCGUUUCGUCAGUAUCCCCGUUUACAGGGCGGCUUCGUCUGGGACUGGGUGGAUCAGUCGCUGAUUAAAUAUGAUGAAAACGGCAACCCGUGGUCGGCUUACGGCGGUGAUUUUGGCGAUACGCCGAACGAUCGCCAGUUCUGUAUGAACGGUCUGGUCUUUGCCGACCGCACGCCGCAUCCAGCGCUGACGGAAGCAAAACACCAGCAGCAGUUUUUCCAGUUCCGUUUAUCCGGGCAAACCAUCGAAGUGACCAGCGAAUACCUGUUCCGUCAUAGCGAUAACGAGCUCCUGCACUGGAUGGUGGCGCUGGAUGGUAAGCCGCUGGCAAGCGGUGAAGUGCCUCUGGAUGUCGCUCCACAAGGUAAACAGUUGAUUGAACUGCCUGAACUACCGCAGCCGGAGAGCGCCGGGCAACUCUGGCUCACAGUACGCGUAGUGCAACCGAACGCGACCGCAUGGUCAGAAGCCGGGCACAUCAGCGCCUGGCAGCAGUGGCGUCUGGCGGAAAACCUCAGUGUGACGCUCCCCGCCGCGUCCCACGCCAUCCCGCAUCUGACCACCAGCGAAAUGGAUUUUUGCAUCGAGCUGGGUAAUAAGCGUUGGCAAUUUAACCGCCAGUCAGGCUUUCUUUCACAGAUGUGGAUUGGCGAUAAAAAACAACUGCUGACGCCGCUGCGCGAUCAGUUCACCCGUGCACCGCUGGAUAACGACAUUGGCGUAAGUGAAGCGACCCGCAUUGACCCUAACGCCUGGGUCGAACGCUGGAAGGCGGCGGGCCAUUACCAGGCCGAAGCAGCGUUGUUGCAGUGCACGGCAGAUACACUUGCUGAUGCGGUGCUGAUUACGACCGCUCACGCGUGGCAGCAUCAGGGGAAAACCUUAUUUAUCAGCCGGAAAACCUACCGGAUUGAUGGUAGUGGUCAAAUGGCGAUUACCGUUGAUGUUGAAGUGGCGAGCGAUACACCGCAUCCGGCGCGGAUUGGCCUGAACUGCCAGCUGGCGCAGGUAGCAGAGCGGGUAAACUGGCUCGGAUUAGGGCCGCAAGAAAACUAUCCCGACCGCCUUACUGCCGCCUGUUUUGACCGCUGGGAUCUGCCAUUGUCAGACAUGUAUACCCCGUACGUCUUCCCGAGCGAAAACGGUCUGCGCUGCGGGACGCGCGAAUUGAAUUAUGGCCCACACCAGUGGCGCGGCGACUUCCAGUUCAACAUCAGCCGCUACAGUCAACAGCAACUGAUGGAAACCAGCCAUCGCCAUCUGCUGCACGCGGAAGAAGGCACAUGGCUGAAUAUCGACGGUUUCCAUAUGGGGAUUGGUGGCGACGACUCCUGGAGCCCGUCAGUAUCGGCGGAAUUCCAGCUGAGCGCCGGUCGCUACCAUUACCAGUUGGUCUGGUGUCAAAAAUAA
E. Coli LacZ protein sequence – 1024 amino acids MTMITDSLAVVLQRRDWENPGVTQLNRLAAHPPFASWRNSEEARTDRPSQQLRSLNGEWRFAWFPAPEAVPESWLECDLPEADTVVVPSNWQMHGYDAPIYTNVTYPITVNPPFVPTENPTGCYSLTFNVDESWLQEGQTRIIFDGVNSAFHLWCNGRWVGYGQDSRLPSEFDLSAFLRAGENRLAVMVLRWSDGSYLEDQDMWRMSGIFRDVSLLHKPTTQISDFHVATRFNDDFSRAVLEAEVQMCGELRDYLRVTVSLWQGETQVASGTAPFGGEIIDERGGYADRVTLRLNVENPKLWSAEIPNLYRAVVELHTADGTLIEAEACDVGFREVRIENGLLLLNGKPLLIRGVNRHEHHPLHGQVMDEQTMVQDILLMKQNNFNAVRCSHYPNHPLWYTLCDRYGLYVVDEANIETHGMVPMNRLTDDPRWLPAMSERVTRMVQRDRNHPSVIIWSLGNESGHGANHDALYRWIKSVDPSRPVQYEGGGADTTATDIICPMYARVDEDQPFPAVPKWSIKKWLSLPGETRPLILCEYAHAMGNSLGGFAKYWQAFRQYPRLQGGFVWDWVDQSLIKYDENGNPWSAYGGDFGDTPNDRQFCMNGLVFADRTPHPALTEAKHQQQFFQFRLSGQTIEVTSEYLFRHSDNELLHWMVALDGKPLASGEVPLDVAPQGKQLIELPELPQPESAGQLWLTVRVVQPNATAWSEAGHISAWQQWRLAENLSVTLPAASHAIPHLTTSEMDFCIELGNKRWQFNRQSGFLSQMWIGDKKQLLTPLRDQFTRAPLDNDIGVSEATRIDPNAWVERWKAAGHYQAEAALLQCTADTLADAVLITTAHAWQHQGKTLFISRKTYRIDGSGQMAITVDVEVASDTPHPARIGLNCQLAQVAERVNWLGLGPQENYPDRLTAACFDRWDLPLSDMYTPYVFPSENGLRCGTRELNYGPHQWRGDFQFNISRYSQQQLMETSHRHLLHAEEGTWLNIDGFHMGIGGDDSWSPSVSAEFQLSAGRYHYQLVWCQK
Fig. 17-5 Second mRNA base First mRNA base (5 end of codon) Third mRNA base (3 end of codon)
LacZ (Beta-galactosidase) gene (DNA) Beta-galactosidase protein (E. coli) LacZ mRNA
E. Coli Sliding Clamp DNA sequence (1 strand shown)- 1101 base pairs ATGAAATTTACCGTAGAACGTGAGCATTTATTAAAACCGCTACAACAGGTGAGCGGTCCGTTAGGTGGTCGTCCTACGCTACCGATTCTCGGTAATCTGCTGTTACAGGTTGCTGACGGTACGTTGTCGCTGACCGGTACTGATCTCGAGATGGAAATGGTGGCACGTGTTGCGCTGGTTCAGCCACACGAGCCAGGAGCGACGACCGTTCCGGCGCGCAAATTCTTTGATATCTGCCGTGGTCTGCCTGAAGGCGCGGAAATTGCCGTGCAGCTGGAAGGTGAACGGATGCTGGTACGCTCCGGGCGTAGCCGTTTTTCGCTGTCTACCCTGCCAGCGGCGGATTTCCCGAACCTCGATGACTGGCAGAGTGAAGTCGAATTTACCCTGCCGCAGGCAACGATGAAGCGTCTGATTGAAGCGACCCAGTTTTCTATGGCGCATCAGGACGTTCGCTATTACTTAAATGGTATGCTGTTTGAAACCGAAGGTGAAGAACTGCGCACCGTGGCAACCGACGGCCACCGTCTGGCGGTCTGTTCAATGCCAATTGGTCAATCTTTGCCAAGCCATTCGGTGATCGTACCGCGTAAAGGCGTGATTGAACTGATGCGTATGCTCGACGGCGGCGACAATCCGCTGCGCGTACAGATTGGCAGCAACAACATTCGCGCCCACGTTGGCGACTTTATCTTCACCTCCAAACTGGTGGATGGTCGCTTCCCGGATTATCGCCGCGTTCTGCCGAAGAACCCGGACAAACATCTGGAAGCTGGCTGCGATCTGCTCAAGCAGGCGTTTGCTCGCGCGGCGATTCTCTCTAACGAGAAATTCCGCGGCGTACGTCTTTATGTCAGCGAAAACCAGCTGAAAATCACCGCCAACAACCCGGAACAGGAAGAAGCGGAAGAGATCCTCGACGTTACCTATAGCGGTGCGGAGATGGAAATCGGCTTCAACGTCAGTTATGTGCTGGATGTTCTGAACGCGCTGAAATGCGAAAACGTCCGCATGATGCTGACCGATTCGGTTTCCAGCGTGCAGATTGAAGATGCGGCCAGCCAGAGCGCGGCTTATGTTGTCATGCCAATGAGACTGTAA E. Coli Sliding Clamp Protein sequence- 366 amino acids MKFTVEREHLLKPLQQVSGPLGGRPTLPILGNLLLQVADGTLSLTGTDLEMEMVARVALVQPHEPGATTVPARKFFDICRGLPEGAEIAVQLEGERMLVRSGRSRFSLSTLPAADFPNLDDWQSEVEFTLPQATMKRLIEATQFSMAHQDVRYYLNGMLFETEGEELRTVATDGHRLAVCSMPIGQSLPSHSVIVPRKGVIELMRMLDGGDNPLRVQIGSNNIRAHVGDFIFTSKLVDGRFPDYRRVLPKNPDKHLEAGCDLLKQAFARAAILSNEKFRGVRLYVSENQLKITANNPEQEEAEEILDVTYSGAEMEIGFNVSYVLDVLNALKCENVRMMLTDSVSSVQIEDAASQSAAYVVMPMRL
Origin of replication 3 5 RNA primer 5 Fig. 16-15b “Sliding clamp” 3 5 DNA pol III Parental DNA 3 5 5 3 5
Sliding clamp protein (E. coli)- shown with DNA double helix
Gene 2 DNA molecule Gene 1 Gene 3 Fig. 17-4 DNA template strand TRANSCRIPTION mRNA Codon TRANSLATION Protein Amino acid
Sugars Fig. 5-27c-2 Deoxyribose (in DNA) Ribose (in RNA) (c) Nucleoside components: sugars
Nitrogenous bases Pyrimidines Fig. 5-27c-1 Cytosine (C) Thymine (T, in DNA) Uracil (U, in RNA) Purines Adenine (A) Guanine (G) (c) Nucleoside components: nitrogenous bases
Fig. 16-5 Nitrogenous bases Sugar–phosphate backbone 5 end Chemical structure of DNA Thymine (T) Adenine (A) Cytosine (C) DNA nucleotide Phosphate Sugar (deoxyribose) 3 end Guanine (G)
Fig. 16-5 Nitrogenous bases Sugar–phosphate backbone 5 end Chemical structure of RNA -ribose instead of deoxyribose Uracilinstead of thymine OH OH OH OH Thymine (T) Uracil (U) Cytosine (C) Adenine (A) Cytosine (C) RNA DNA nucleotide Phosphate Sugar (deoxyribose) 3 end Guanine (G)
DNA Protein RNA Replication Transcription Translation Polymerase DNA Pol III (and I) dNTPs Monomers Template ssDNA Direction of synthesis 5’ to 3’ polynucleotide Product
DNA Protein RNA Replication Transcription Translation Polymerase DNA Pol III (and I) RNA Pol dNTPs NTPs Monomers ssDNA Template ssDNA 5’ to 3’ Direction of synthesis 5’ to 3’ polynucleotide polynucleotide Product
Promoter Transcription unit 5 3 3 5 DNA Start point RNA polymerase Fig. 17-7a-1
Promoter Transcription unit 5 3 3 5 DNA Start point RNA polymerase Initiation 1 5 3 Fig. 17-7a-2 3 5 Template strand of DNA RNA transcript Unwound DNA
Promoter Transcription unit 5 3 3 5 DNA Start point RNA polymerase Initiation 1 5 3 Fig. 17-7a-3 3 5 Template strand of DNA RNA transcript Unwound DNA Elongation 2 Rewound DNA 5 3 3 3 5 5 RNA transcript
Promoter Transcription unit 5 3 3 5 DNA Start point RNA polymerase Initiation 1 5 3 Fig. 17-7a-4 3 5 Template strand of DNA RNA transcript Unwound DNA Elongation 2 Rewound DNA 5 3 3 3 5 5 RNA transcript Termination 3 5 3 3 5 3 5 Completed RNA transcript
Fig. 17-7b Nontemplate strand of DNA Elongation RNA nucleotides RNA polymerase 3' 3' end 5' Direction of transcription (“downstream”) 5' Template strand of DNA Newly made RNA
A eukaryotic promoter includes a TATA box 1 Promoter Template 5 3 3 5 TATA box Template DNA strand Start point Several transcription factors must bind to the DNA before RNA polymerase II can do so. 2 Fig. 17-8 Transcription factors 5 3 3 5 Additional transcription factors bind to the DNA along with RNA polymerase II, forming the transcription initiation complex. 3 RNA polymerase II Transcription factors 3 5 5 5 3 RNA transcript Transcription initiation complex
DNA Protein RNA Replication Transcription Translation Polymerase DNA Pol III (and I) RNA Pol dNTPs NTPs Monomers ssDNA Template ssDNA 5’ to 3’ Direction of synthesis 5’ to 3’ polynucleotide polynucleotide Product