Download

1 / 29
290 likes | 511 Views
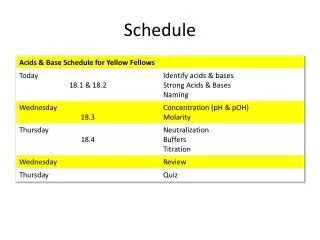
Schedule. Today: Query Processing overview. Steps in Query Processing. 1. Parsing and translation 2. Optimization 3. Evaluation. Steps in Query Processing. Parsing and translation translate the query into its internal form. This is then translated into relational algebra.

E N D
Schedule • Today: • Query Processing overview Holliday - COEN 178
Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation Holliday - COEN 178
Steps in Query Processing • Parsing and translation • translate the query into its internal form. This is then translated into relational algebra. • Parser checks syntax, verifies relations • Optimization • Evaluation • The query-execution engine takes a query-evaluation plan, executes that plan, and returns the answers to the query. Holliday - COEN 178
Optimization • A relational algebra expression may have many equivalent expressions • E.g., balance2500(balance(account)) is equivalent to balance(balance2500(account)) • Each relational algebra operation can be evaluated using one of several different algorithms • Annotated expression specifying detailed evaluation strategy is called an evaluation-plan. • E.g., can use an index on balance to find accounts with balance < 2500, • or can perform complete relation scan and discard accounts with balance 2500 Holliday - COEN 178
Query Optimization • Amongst all equivalent evaluation plans choose the one with lowest cost. • Cost is estimated using statistical information from the database catalog • e.g. number of tuples in each relation, size of tuples, etc. • We want to know • How to measure query costs • Algorithms for evaluating relational algebra operations • How to combine algorithms for individual operations in order to evaluate a complete expression Holliday - COEN 178
Measures of Query Cost • Cost is generally measured as total elapsed time for answering query • Many factors contribute to time cost • disk accesses, CPU, or even network communication • Typically disk access is the predominant cost, and is also relatively easy to estimate. Measured by taking into account • Number of seeks * average-seek-cost • Number of blocks read * average-block-read-cost • Number of blocks written * average-block-write-cost • Cost to write a block is greater than cost to read a block • data is read back after being written to ensure that the write was successful Holliday - COEN 178
Cost • For simplicity we just use number of block transfers from disk as the cost measure • We also ignore CPU costs for simplicity • Costs depends on the size of the buffer in main memory • Having more memory reduces need for disk access • Amount of real memory available to buffer depends on other concurrent OS processes, and hard to determine ahead of actual execution • We often use worst case estimates, assuming only the minimum amount of memory needed for the operation is available • Real systems take CPU cost into account, differentiate between sequential and random I/O, and take buffer size into account Holliday - COEN 178
Example R A B C S C D E a 1 10 10 x 2 b 1 20 20 y 2 c 2 10 30 z 2 d 2 35 40 x 1 e 3 45 50 y 3 Holliday - COEN 178
Example Select B,D From R,S Where R.A = “c” and S.E = 2 and R.C=S.C B,D(sR.A=“c” S.E=2 R.C=S.C)(R X S) Holliday - COEN 178
Answer B D 2 x R A B C S C D E a 1 10 10 x 2 b 1 20 20 y 2 c 2 10 30 z 2 d 2 35 40 x 1 e 3 45 50 y 3 Holliday - COEN 178
How do we execute query? - Do Cartesian product - Select tuples - Do projection One idea Holliday - COEN 178
Bingo! Got one... RXS R.A R.B R.C S.C S.D S.E a 1 10 10 x 2 a 1 10 20 y 2 . . C 2 10 10 x 2 . . Holliday - COEN 178
Relational Algebra - can be used to describe plans... Ex: Plan I B,D sR.A=“c” S.E=2 R.C=S.C X R S OR: B,D [sR.A=“c” S.E=2 R.C = S.C (RXS)] Holliday - COEN 178
Another idea: B,D sR.A = “c”sS.E = 2 R S Plan II natural join Holliday - COEN 178
R S A B C s (R) s(S) C D E a 1 10 A B C C D E 10 x 2 b 1 20 c 2 10 10 x 2 20 y 2 c 2 10 20 y 2 30 z 2 d 2 35 30 z 2 40 x 1 e 3 45 50 y 3 Holliday - COEN 178
Plan III Use R.A and S.C Indexes (1) Use R.A index to select R tuples with R.A = “c” (2) For each R.C value found, use S.C index to find matching tuples (3) Eliminate S tuples S.E 2 (4) Join matching R,S tuples, project B,D attributes and place in result Holliday - COEN 178
=“c” <c,2,10> <10,x,2> check=2? output: <2,x> next tuple: <c,7,15> R S A B C C D E a 1 10 10 x 2 b 1 20 20 y 2 c 2 10 30 z 2 d 2 35 40 x 1 e 3 45 50 y 3 A C I1 I2 Holliday - COEN 178
Example: SQL query SELECT title FROM StarsIn WHERE starName IN ( SELECT name FROM MovieStar WHERE birthdate LIKE ‘%1960’ ); (Find the movies with stars born in 1960) Holliday - COEN 178
Example: Parse Tree <Query> <SFW> SELECT <SelList> FROM <FromList> WHERE <Condition> <Attribute> <RelName> <Tuple> IN <Query> title StarsIn <Attribute> ( <Query> ) starName <SFW> SELECT <SelList> FROM <FromList> WHERE <Condition> <Attribute> <RelName> <Attribute> LIKE <Pattern> name MovieStar birthDate ‘%1960’ Holliday - COEN 178
Example: Generating Relational Algebra title StarsIn <condition> <tuple> IN name <attribute> birthdate LIKE ‘%1960’ starName MovieStar Fig. 7.15: An expression using a two-argument , midway between a parse tree and relational algebra Holliday - COEN 178
Example: Logical Query Plan title starName=name StarsIn name birthdate LIKE ‘%1960’ MovieStar Fig. 7.18: Applying the rule for IN conditions Holliday - COEN 178
Example: Improved Logical Query Plan title Question: Push project to StarsIn? starName=name StarsIn name birthdate LIKE ‘%1960’ MovieStar Fig. 7.20: An improvement on fig. 7.18. Holliday - COEN 178
Example: Estimate Result Sizes Need expected size StarsIn MovieStar P s Holliday - COEN 178
Selection Operation • File scan – search algorithms that locate and retrieve records that fulfill a selection condition. • Algorithm A1 (linear search). Scan each file block and test all records to see whether they satisfy the selection condition. • Cost estimate (number of disk blocks scanned) = br • If selection is on a key attribute, cost = (br /2) • stop on finding record • Linear search can be applied regardless of • selection condition or • ordering of records in the file, or • availability of indices Holliday - COEN 178
Selection continued • A2 (binary search). Applicable if selection is an equality comparison on the attribute on which file is ordered. • Assume that the blocks of a relation are stored contiguously • Cost estimate (number of disk blocks to be scanned): • log2(br) — cost of locating the first tuple by a binary search on the blocks • Plus number of blocks containing records that satisfy selection condition Holliday - COEN 178
Selection with Index Scan • A3 (primary index on candidate key, equality). Retrieve a single record that satisfies the corresponding equality condition • A4 (primary index on nonkey, equality) Retrieve multiple records. • Records will be on consecutive blocks • A5 (equality on search-key of secondary index). • Retrieve a single record if the search-key is a candidate key • Retrieve multiple records if search-key is not a candidate key • Can be very expensive! • each record may be on a different block • one block access for each retrieved record Holliday - COEN 178
Cross Product and Join • We want a way to estimate the size of the results of joins and cross products. • The cross product r s contains nr * ns tuples and each tuple occupies br + bs bytes • If R S =, then r s is the same as r s Holliday - COEN 178
Join Size Estimation • If R S is a key for R, then we know that a tuple of s will join with at most one tuple from r, so the number of tuples in r s is no greater than the number of tuples in s. • If R S is a foreign key for S referencing R, then the number of tuples in r s is exactly the number of tuples in s. R S Holliday - COEN 178
SQL query parse parse tree convert answer logical query plan execute apply laws statistics Pi “improved” l.q.p pick best estimate result sizes {(P1,C1),(P2,C2)...} l.q.p. +sizes estimate costs consider physical plans {P1,P2,…..} Holliday - COEN 178