Download
1 / 19
290 likes | 771 Views
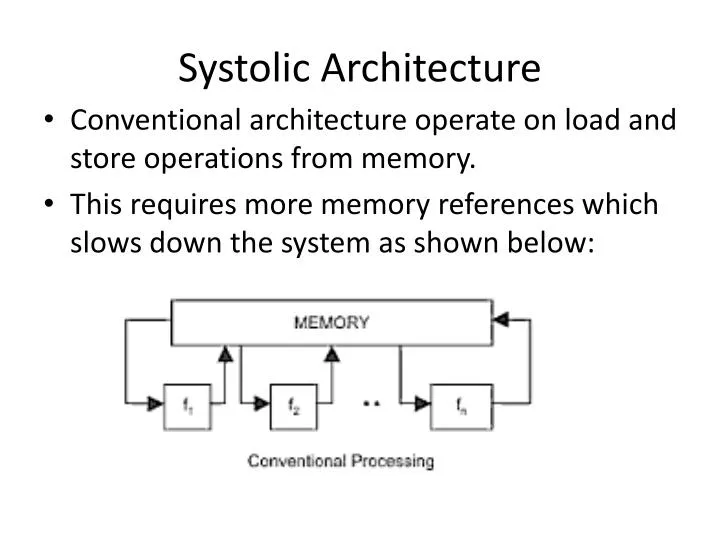
Systolic Architecture. Conventional architecture operate on load and store operations from memory. This requires more memory references which slows down the system as shown below:. Systolic Architecture.

E N D
Systolic Architecture • Conventional architecture operate on load and store operations from memory. • This requires more memory references which slows down the system as shown below:
Systolic Architecture • In systolic processing, data to be processed flows through various operation stages and finally put in memory as shown below:
Systolic Architecture • The basic architecture constitutes processing elements (PEs) that are simple and identical in behavior at all instants. • Each PE may have some registers and an ALU. • PEs are interlinked in a manner dictated by the requirements of the specific algorithm. • E.g. 2D mesh, hexagonal arrays etc.
Systolic Architecture • PEs at the boundary of structure are connected to memory • Data picked up from memory is circulated among PEs which require it in a rhythmic manner and the result is fed back to memory and hence the name systolic • Example : Multiplication of two n x n matrices
Example : Multiplication of two n x n matrices • Every element in input is picked up n times from memory as it contributes to n elements in the output. • To reduce this memory access, systolic architecture ensures that each element is pulled only once • Consider an example where n = 3
Matrix Multiplication a11 a12 a13 a21 a22 a23 a31 a32 a33 b11 b12 b13 b21 b22 b23 b31 b32 b33 c11 c12 c13 c21 c22 c23 c31 c32 c33 * = Conventional Method: O(n3) For I = 1 to N For J = 1 to N For K = 1 to N C[I,J] = C[I,J] + A[J,K] * B[K,J];
Systolic Method This will run in O(n) time! To run in n time we need n x n processing units, in our example n = 9. P1 P2 P3 P4 P5 P6 P7 P8 P9
For systolic processing, the input data need to be modified as: a13 a12 a11 a23 a22 a21 a33 a32 a31 Flip columns 1 & 3 b31 b32 b33 b21 b22 b23 b11 b12 b13 Flip rows 1 & 3 and finally stagger the data sets for input.
b33 b23 b13 b32 b22 b12 b31 b21 b11 a13 a12 a11 P1 P2 P3 a23 a22 a21 P4 P5 P6 a33 a32 a31 P7 P8 P9 At every tick of the global system clock, data is passed to each processor from two different directions, then it is multiplied and the result is saved in a register.
5 3 2 3 4 2 2 5 3 3 2 5 3 4 2 2 5 3 3 2 5 23 36 28 25 39 34 28 32 37 2 5 4 * 3 2 3 = Using a systolic array. 2 4 3 P1 P2 P3 3 5 2 P4 P5 P6 5 2 3 P7 P8 P9
Clock tick : 1 5 3 2 2 5 4 3 2 2 4 3*3 P2 P3 3 5 2 P4 P5 P6 5 2 3 P7 P8 P9
Clock tick : 2 5 3 2 2 5 3 2 4*2 3*4 P3 3 5 2*3 P5 P6 5 2 3 P7 P8 P9
Clock tick : 3 5 3 2 2*3 4*5 3*2 3 5*2 2*4 P6 5 2 3*3 P8 P9
Clock tick : 4 5 23 2*2 4*3 3*3 5*5 2*2 5 2*2 3*4 P9
Clock tick : 5 23 36 2*5 25 3*2 5*3 5*3 2*5 3*2
Clock tick : 6 23 36 28 25 39 3*5 28 5*2 2*3
Clock tick : 7 23 36 28 25 39 34 28 32 5*5
End 23 36 28 25 39 34 28 32 37
Samba: Systolic Accelerator for Molecular Biological Applications This systolic array contains 128 processors shared into 32 full custom VLSI chips. One chip houses 4 processors, and one processor performs 10 millions matrix cells per second.