Download
1 / 3
30 likes | 211 Views
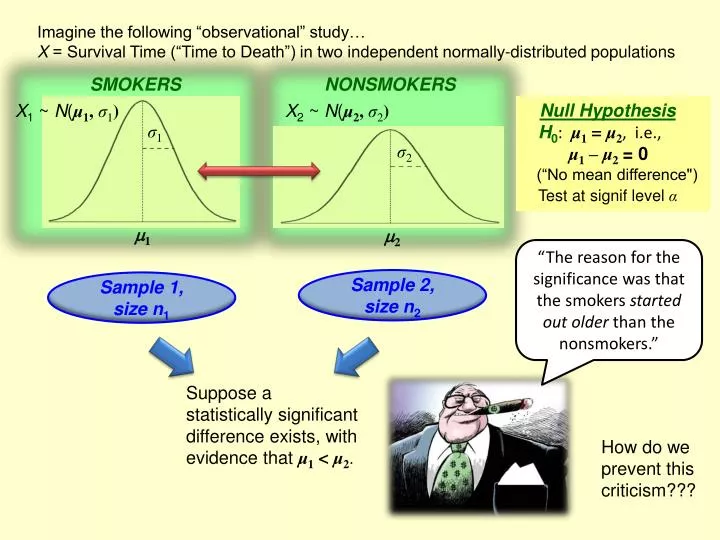
Imagine the following “observational” study… X = Survival Time (“Time to Death”) in two independent normally-distributed populations . SMOKERS. NONSMOKERS. X 1 ~ N ( μ 1 , σ 1 ). X 2 ~ N ( μ 2 , σ 2 ). Null Hypothesis H 0 : μ 1 = μ 2 , i.e., μ 1 – μ 2 = 0

E N D
Imagine the following “observational” study… X = Survival Time (“Time to Death”) in two independent normally-distributed populations SMOKERS NONSMOKERS X1~ N(μ1, σ1) X2 ~ N(μ2, σ2) Null Hypothesis H0: μ1 = μ2, i.e., μ1 – μ2= 0 (“No mean difference") Test at signif level α σ1 σ2 1 2 “The reason for the significance was that the smokers started out older than the nonsmokers.” Sample 2, size n2 Sample 1, size n1 Suppose a statistically significant difference exists, with evidence that μ1 < μ2. How do we prevent this criticism???
Now consider two dependent (“matched,” “paired”) populations… X and Ynormally distributed. POPULATION 1 POPULATION 2 X ~ N(μ1, σ1) Y ~ N(μ2, σ2) Null Hypothesis H0: μ1 = μ2, i.e., μ1 – μ2= 0 (“No mean difference") Test at signif level α σ1 σ2 1 2 Classic Examples: Twin studies, Left vs. Right, Pre-Tx (Baseline) vs. Post-Tx, etc. Common in human trials to match on Age, Sex, Race,… By design, every individual in Sample 1 is “paired” or “matched” with an individual in Sample 2, on potential confounding variables. … etc…. … etc….
Now consider two dependent (“matched,” “paired”) populations… X, and Ynormally distributed. POPULATION 1 POPULATION 2 X ~ N(μ1, σ1) Y ~ N(μ2, σ2) Null Hypothesis H0: μ1 = μ2, i.e., μ1 – μ2= 0 (“No mean difference") Test at signif level α σ1 σ2 D= 1 2 Classic Examples: Twin studies, Left vs. Right, Pre-Tx (Baseline) vs. Post Tx, etc. Common in human trials to match on Age, Sex, Race,… NOTE: Sample sizes are equal! … etc…. … etc…. Sample 2, size n Sample 1, size n Since they are paired, subtract! Treat as one sample of the normally distributed variable D = X – Y.