Download

1 / 8
80 likes | 87 Views
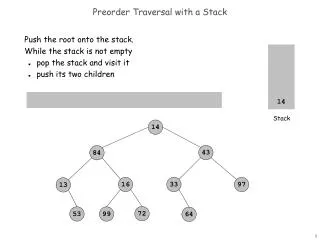
The time complexity for e-closure(T). Push all states in T onto stack; initialize e-closure(T) to T; while stack is not empty do begin pop t, the top element, off the stack for each state u with an edge from t to u labeled e do if u is not in e-closure(T) do begin

E N D
The time complexity for e-closure(T). Push all states in T onto stack; initialize e-closure(T) to T; while stack is not empty do begin pop t, the top element, off the stack for each state u with an edge from t to u labeled e do if u is not in e-closure(T) do begin add u to e-closure(T) push u onto stack end if end do end while (page 119, Fig. 3.26) Time complexity?
The complexity for the algorithm that recognizes the language accepted by NFA(revisit). • Input: an NFA (transition table) and a string x (terminated by eof). • output “yes” if accepted, “no” otherwise. S = e-closure({s0}); a = nextchar; while a != eof do begin S = e-closure(move(S, a)); a := next char; end if (intersect (S, F) != empty) then return “yes” else return “no” Time complexity ?? Space complexity ??
Algorithm to convert an NFA to a DFA that accepts the same language (algorithm 3.2, page 118) initially e-closure(s0) is the only state in Dstates and it is marked while there is an unmarked state T in Dstates do begin mark T; for each input symbol a do begin U := e-closure(move(T, a)); if (U is not in Dstates) then add U as an unmarked state to Dstates; Dtran[T, a] := U; end end; Initial state = e-closure(s0), Final state = ?
Question: • for a NFA with |S| states, at most how many states can its corresponding DFA have? • Using DFA or NFA?? Trade-off between space and time!!
The number of states determines the space complexity. • A DFA can potentially have a large number of states. • Converting an NFA to a DFA may not result in the minimum-state DFA. • In the final product, we would like to construct a DFA with the minimum number of states (while still recognizing the same language). • Basic idea: assuming all states have a transition on every input symbol (what if this is not the case??), find all groups of states that can be distinguished by some input strings. An input string w distinguishes two states s and t, if starting from s and feeding w, we end up in a nonaccepting state while starting from t and feeding w, we end up in an accepting state, or vice versa.
Algorithm (3.6, page 142): • Input: a DFA M • output: a minimum state DFA M’ • If some states in M ignore some inputs, add transitions to a “dead” state. • Let P = {All accepting states, All nonaccepting states} • Let P’ = {} • Loop: for each group G in P do Partition G into subgroups so that s and t (in G) belong to the same subgroup if and only if each input a moves s and t to the same state of the same P-groups put the new subgroups in P’ if (P != P’) {P = P’; goto loop} • Remove any dead states and unreachable states.
Example: minimize the DFA for (ab|ba)a* • Example: minimize the DFA for Fig 3.29 (pages 121) • Questions: How can we implement Lex? %% BEGIN {return(BEGINNUMBER);} END {return(ENDNUMBER);} IF {return(IFNUMBER);} %%
Lex internal: • construct an NFA to recognize the sum of all patterns • convert the NFA to a DFA (record all accepting states for each individual pattern). • Minimize the DFA (separate distinct accepting states for the initial pattern). • Simulate the DFA to termination (that is, no further transitions) • Find the last DFA state entered that holds an accepting NFA state (this picks the longest match). If no such state, then it is an invalid token.