Download

1 / 17
170 likes | 186 Views
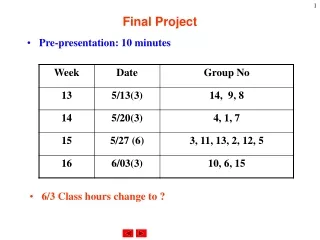
Final project overview on EM method for spell correction in search queries, using noisy channel model and probabilistic edit distance.

E N D
Probabilistic Spelling Correction for Search Queries Cmput 650 Final Project
Overview • Motivation • Problem Statement • Noisy Channel Model • EM Background • EM for Spelling Correction
Search Query Spelling Correction • Motivation • Over 700 M search queries made every day • 10% misspelled • Problems • Queries are often not found in a dictionary • Many possible candidate corrections for any given misspelled query
Possible Approaches • Naïve Method • search a dictionary for the closest match, using levenshtein edit distance • return closest match • Better method • search a dictionary for closest matches • use levenshtein edit distance and word unigram probability to select best match
Noisy Channel Model • Basic Noisy Channel Model • Given v, find best w • argmax n P(wn) = argmax n P(v|wn) * P(wn) • error model: P(v|w); language model P(w) • Why not just use Levenshtein Distance? • eg. britny -> briny vs britney • Further Improvement • Use probabalistic edit distance (error model) and N-gram probability (language model)
Error Model P(v|w) • Standard (Levenshtein) Edit Distance • algorithm, ins,del,sub costs, example n = length (target) m = length(source) for i = 0 to n for j = 0 to m d[i,j] = MIN(d[i-1,j] + ins-cost(targeti), d[i-1,j-1] + sub-cost(sourcej, targeti), d[i,j-1] + del-cost(sourcej) )
Better Error Model P(v|w) • Probabilistic Edit Distance • ED proportional to probability of the edit • Different probability/cost for each edit pair • eg. P(e->i) > P(e->z) • How do we relate edit distance (lower is “better”) and probability (higher is “better”)? • d(v,w) = -log(P(v|w))
What we want • Error Model (Unknown) • P(v|w) • P(w): Language Model (known) • P(w) = c(w) / Σwc(w) • Use query logs and the language model to determine the error model
Probabilistic Edit Distance • Determining the probabilistic edit model • Expectation Maximization • For each query v • Determine the most likely “corrections” using the existing edit distance model and language model • for each word within ED(x) • candidates = args max n P(v|wn)P(wn) • one candidate may be the word itself • Update the edit distance model • What is EM?
Clustering and EM • Hard Clustering (K-means)
Hard and Soft Clustering • Soft Clustering (EM)
Expectation Maximization • E-Step • Assign each data point to each cluster in proportion to how well it fits the cluster • M-Step • Update the cluster centers to reflect the addition of the point
EM for Spelling Correction • For a given query v • Find all candidate words w within ED(x); • E-Step • For each candidate word • E[zvw] =P(w|v)= P(v|w)P(w)/ Σw P(v|w)P(w) • P(v|w) = ΠP(ecij) • P(ecij) is the Probability of edit [letter i-> letter j]
EM for Spelling Correction • M-Step • Given P(v) = P(e1...en|w)P(w) • each ei is a single ins, del, or sub of two letters • want to adjust P(e1).. P(e2) accordingly • f(ei) += P(w) • P(ei) += f(ei) / N • N total number of edit operations for that letter • D(ei) = -log(P(ei))
M-Step • E and M-Step working together E-Step Edit Sequences, P(ES|D) D = -log(P(l1,l2))
Results • Example • Robert is a frequent search term, Qbert is not. • Atari makes a comeback...