Download

1 / 8
80 likes | 264 Views
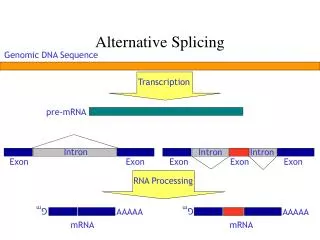
Splicing Enhancer Scoring in ISCAN. Overview. Method SC35 splicing enhancer WMM (SELEX experiments by M. Zhang & A. Krainer, CHSL) 6-base long pattern Training set “Clean†set of 6061 Refseq genes (no alternative splicing) Results WMM hits in introns tend to overlap by 2 and 4 bases

E N D
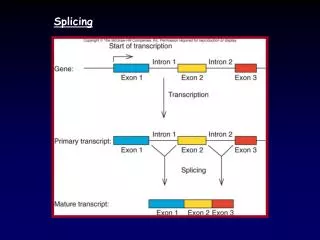
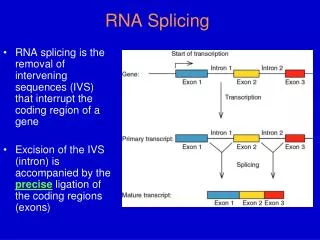
Overview • Method • SC35 splicing enhancer WMM (SELEX experiments by M. Zhang & A. Krainer, CHSL) • 6-base long pattern • Training set • “Clean” set of 6061 Refseq genes (no alternative splicing) • Results • WMM hits in introns tend to overlap by 2 and 4 bases • Hits in exons often overlap by 3 bases
Deriving Splicing Enhancer Score • Let • n2 = count of 2-base or 4-base overlaps, • n3 = count of 3-base overlaps, • z = n2 – n3 • Derive distribution P(z) from the training set • Use randomized sequences with the same length distribution to derive the null model • Compute the score S = 10*log2(P(z)/Pnull(z)) • Requires explicit intron length model
Explicit Intron Length Model X ● ● ● -∞ k-L k • Some positions have max exon score of –∞ • Can skip introns that end at such positions • If DNA sequence is masked, the number of • iterations needed is O(1000) for L ~ 105 • Run time for 1MB is of the order of 10 hours
Splicing Enhancer Model • Use 2-base overlap and 3-base overlap counts to define z • Explicit intron length up to 50 kb • z > 0: • P(z) = a/(z2+bz+c); Pnull(z) = aebz (b > 0) • z < 0: • P(z) = ae-bz; Pnull(z) = ce-dz (b, d > 0)
What next? • Use “clean” RefSeq set to re-estimate parameters • Optimize splicing enhancer model • 4-base overlap counts instead of 2-base (or both) • Better null model • Other motifs • Apply pseudogene filtering to increase specificity