Download

1 / 15
150 likes | 311 Views
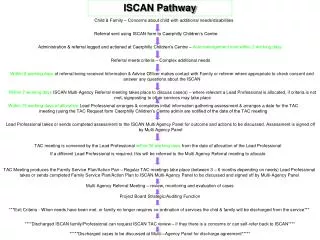
Parallel Iscan. Lab meeting 3-9-05. How did we get here. Memory problem Large chromosome sequences must be split into 1MB fragments Inherently parallel Can’t correctly predict genes which cross the 1MB boundaries Memory Solution Cpoint iscan solves memory problem. Standard Iscan example.

E N D
Parallel Iscan Lab meeting 3-9-05
How did we get here • Memory problem • Large chromosome sequences must be split into 1MB fragments • Inherently parallel • Can’t correctly predict genes which cross the 1MB boundaries • Memory Solution • Cpoint iscan solves memory problem
How did we get here • Running Time Problem • With cpoint iscan large sequences are run on a single processor • No longer parallel • Running Time Solution • Pin search allows us to split sequence into independent sub problems without losing the ability to correctly predict all genes
Experiment • Human chr 1, 15, 20, 21, 22 • Split into fragments on 1MB+ of N • For each fragment • Check for pin every 1MB from start • 298 total checks • 294 successful (98.7%) • 4 failed (1.3% - search reaches 1 end of sequence)
Successful Searches • Running Time • mean: 7 min • median: 9 min • max: 50 min • Search Length • mean: 132,000 • median: 83,000 • max: 1,120,000
Potential Strategy • Start search every N bases • For each search • If pin is found begin to decode • If next search pos is reached in decode before pin is found cancel search • Else trace back from pin state • When a search is cancelled or a traceback is complete start new search in undecoded sequence region
Other ideas • Use heuristics to identify searches which appear unlikely to complete quickly • Abandon these searches • Search until we have only a small number of live states at pin pos then run normal iscan from each of those states, determining which to actually use later • Chose most probable state and run normal iscan from there. If this state later proves not to be the pin state just rerun from the actual state.