Download

1 / 38
380 likes | 608 Views
Dietmar Janetzko Non-reactive Data Collection on the Internet. Dr. Dietmar Janetzko National College of Ireland Mayor Street, IFSC, Dublin Telephone +353 1 4498-610 Fax: +353 1 406 0559 Mobile +353 8640 82891 E-Mail: dietmarja@gmail.com. Outline.

E N D
Dietmar JanetzkoNon-reactive Data Collection on the Internet Dr. Dietmar Janetzko National College of Ireland Mayor Street, IFSC, Dublin Telephone +353 1 4498-610 Fax: +353 1 406 0559 Mobile +353 8640 82891 E-Mail: dietmarja@gmail.com
Outline • The Concept of Non Reactive Data Collection • The Technical Perspective • The Methodological Perspective • Thin and Rich Descriptions • Two ways to deal with thin descriptions: Horizontal and vertical enlargement of data sets • Extensions & Recent Developments • The Enron Data Set (E-Mail) • The AOL Data Set (Search Requests) • Collection all Data about a Person • Discussion
The Concept of Non Reactive Data Collection • Non reactive data collection is conducted in a naturalistic setting in such a way that persons studied are not aware of it. • Thus, non-reactivity is not a characteristic of the data or the data collection procedure per se, but of the awareness of the persons (not) studied. • Three kinds of non reactive data: • Environmental (PhysicaL) Traces • Simple Observations • Archival Sources (Frankfort-Nachmias & Nachmias, 2000).
Motivation for Non Reactive Data Collection on the Internet A) Why non reactive? B) Why using the Internet/Internet technologies? C) What are the limits of using non reactive data collected on the Internet?
Why non reactive? • Often, a reactive equivalent to NRD does not exist. It would be cumbersome to develop or it would severely interfere with the phenomena studied. • The phenomenon of interest would be distorted or disappear if studied in a reactive way Example: Studying dating on the Internet via reactive measures would defeat its purpose and/or would be open to criticism that an unsuitable method has been used.
Why using the Internet/Internet Technologies? • Today, many social phenomena (e.g., communication in organisations) unfold especially or even exclusively via the Internet. • NRD collected on the Internet highlight behavioral & social phenomena, but is also indispensable for organising online research. Example: Using cookies, IP-Addresses or time stamps to control if persons participate several times in an online study • Data collection • is relatively simple • not limited to a fixed area/time • may yield Data may be collected in large quantities • can be done in an automated and objective way • may cover “sub-symbolic information” (e.g., hesitations to make a decision, Hofmann, Reed, & Holz, 2006)
Limits of Non Reactive Data Collection on the Internet • Many techniques used for NRDCI have not been designed for online research studies in the first place. Example: Log files have been devised to allow technical staff to control the proper working of systems like web server • NRDC techniques facilitate studying a very small part of the spectrum of behavioral or social phenomena. • Person characteristics like appearance, height and weight, attire, gender, age, ethnic group, facial expressions, eye contact, body language, gestures and emotive responses are filtered away (Dholakia & Zhang, 2000).
Perspectives on Non Reactive Data Collection on the Internet Non reactive data collection on the Internet can be viewed from different vantage points, e.g., • Technological Perspective • Privacy Perspective • Methodological Perspective • Data Mining Perspective (Web Usage Mining) • Commercial Perspective (e.g., marketing) …
Techniques used for Non-Reactive Data Collection on the Internet
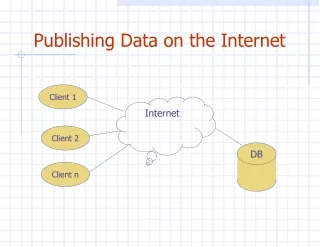
Client & Server Client Client Web-Server Client Client
5 4 5 2 1 2 4 2 1 3 2 1 Client & Server (cont.) Browser asks (=requests) a document from a server available via a URL (Unique Resource Locator) Server allocates values to environment variables Server retrieves the document (usually HTML code), generates a header, sends it to the client Server writes entries into its log-files Client presents the HTML code in a readable way (“renders the HTML code”) Browser may also call and thus cause to execute a program (-> CGI) If the access fails, the server will generate error-reports instead - Client-Server Interaction follows HTTP (Hypertext Transfer Protocol)
Environment Variables • To pass data about the information request from the server to the script, the server uses environment variables as well as the standard input and output streams of a CGI-script. • Environment variables are set when the server executes the gateway program. There are some environment variables set for request-specific and some of set for all requests. • Selection of some environment variables • SERVER_SOFTWARE • SERVER_NAME • REQUEST_METHOD • REMOTE_ADDR
Environment Variables (cont.) • The Common Gateway Interface (CGI) is a standard for external gateway programs to interface with information servers such as HTTP servers. A HTTP server usually supports all environment variables of the CGI-Version to which it complies. • The current version is still CGI/1.1. The CGI/1.2 ("Next Generation") Specification is still in the limbo. • http://www.w3.org/CGI/ • http://hoohoo.ncsa.uiuc.edu/cgi/intro.html
Log Files • Servers (HTTP Server, Web server) or clients keep a track of system or user activities by generating so-called log files. Log files provide valuable information, e.g., on the security of the server or the activities of the user • There are different types of log files • Standard log files that follow a specific format • Vendor-specific Log Files • Client-Side or Server-Side Log-Files • Specifically Tailored Log Files
Log Files • There are different Types of Standard Log Files generated by a HTTP Server (Web server): • Access/Transfer Log information about who visited a site • Error Log information on the errors that occurred while accessing the server • Referer Log information on the source that referred a visitor has visited before • Agent Log information on the client´s browser and operating system
Log-Files / Entries („Tokens“) of Log-Files (Selection) • AG Type of Browser used (Agent) • B Number of Bytes transferred from Server to Client • BR Number of Bytes transferred from Client to Server • D Data/Time of the Request • S Service Requested • H Client’s domain Name or IP-AddressI Identification of the User on the Client Side • NTSC Status Code (Win NT)O Operation carried out (e.g., GET) • P Files (including Path) requested • SA IP-Address of the ServerSC Status CodeSN Name of the ServerREF URL of the Site where the Client has been immediately before
IP Addresses • Every computer connected to the Internet has a 32 Bit IP or Internet Protocol address. It consits of 4 octets (Bytes) separated by dots (e.g., 192.168.1.1). • IANA (Internet Assigned Names Authority, http://www.iana.org/) is responsible for the world wide administration of IP-Addresses • An IP-Address is unique, but one computer may have several IP- Addresses – one for each connection to the Internet. Vice versa, one IP Address can be used by several computers to access the Internet. • „Behind“ one computer there may be a complete network. This is the idea of a gateway. The gateway has a address that is visible from the outside. Thus, other computers within the network are not visible.
Cookies: Introduction • What is a Cookie? “A cookie is an element of data that a Web site can send to your browser, which may then store it on your system. You can set your browser to notify you when you receive a cookie, giving you the chance to decide whether to accept it.” Source: http://www.w3.org/2001/10/glance/doc/privacy.html • Why are Cookies so popular? Not the kind of information per se that is managed by cookies makes them interesting. This means, cookies do not give youa privileged access to some pieces of information that you can’t access via other techniques. What makes cookies interesting is the kind of information management they allow.
Non-Persisten Cookies (Session IDs) Session identification URIs permit HTTP transactions to be linked within a limited domain. This allows a content provider to track activities within sites on their network but does not permit data from different sites to be correlated without specific user authorization in advance. Example of a session-id:http://www.sun.com/2000-1121/wlc/;$sessionid$AY2D5XQAAB42RAMTA1LU45Q http://subscriptions.sun.com/optin?id=7289675917258240725 http://www.amazon.com/exec/obidos/subst/home/home.html/103-6371678-0789449 You will often see session-IDs as a string of numbers in the browser address bar. These numbers will track you via cookies and serve pages specific to your "session". A session can be any time limit and then it expires. Sites use these sessions to serve custom content, defeat browser caching, and to direct the flow of visitors through the website.. http://www.webmasterworld.com/glossary/session_id.htm http://www.w3.org/TR/WD-session-id.html
Generation of Cookies • How are cookies generated? • Cookies can be sent by the server with a HTTP-responseor they can be set by a server-side (CGI) or client-side (JavaScript) program. JavaScript can also be used to read cookies - in accordance to the limitation of cookie usage. • There are different types of Cookies • Persistent Cookies vs. Non-persistent cookies.
Thin Descriptions – Rich Descriptions • Usage of NRD leads to thin descriptions. • Like all behavioral data, NRD gives no access to internal states. Example: E-mail logs might indicate the “intensity” of a relationship between two communication persons. In itself, however, they do not indicate why they communicate in the first place. Likewise they do not reveal the content of the communication.
Two ways to deal with thin descriptions Enlargement of a 2-dimensional Data Set Horizontal Enlargement(„data enrichment“) Vertical Enlargement
Two ways to deal with thin descriptions (cont.) • Vertical Enlargment • Merging same-format data of different sources • Horizontal Enlargement • Merging data / Triangualation (e.g., Webb et al., 2000) • Inferring attributes Example: Horizontal enlargement may violate the user‘s privacy, e.g, when click-stream information is linked registration information. In this way data become personally identifiable
Vertical & horizontal Enlargement („validation & class prediction“) Step1:Validation Step2:Prediction Combining two ways to deal with thin descriptions • Example: How can one predict the size of a household on the basis of • the web sites viewed? • Record the web sites viewed, the time spend etc. (non-reactive) • Find out the size of the household (reactive) • Record the web sites viewed, the time spend etc. (non-reactive) • Predict the size of the household
Two ways to deal with thin descriptions (cont.) • Vertical Enlargment • Merging same-format data of different sources • Buying addresses • Horizontal Enlargement • Merging data (online & online, e.g., registration information; online & offline, e.g., operational data) • Infering attributes • GOFAST, e.g., regression analysis, • data mining, e.g., probabilistic techniques, • others, e.g., affinity scoring
The Enron Data Set (E-Mails) • In December 2001, the Enron Corporation, an American energy company based in Houston Texas, collapsed and had to declare bankruptcy. • Originally made public by the Federal Energy Regulatory Commission as part of the legal proceedings against the Enron Corporation. • The data cover a huge collection of real e-mail messages sent and received by employees of the Enron corporation. • The data set was purchased by Leslie Kaelbling of MIT, who discovered that it had integrity problems. • People at CMU, led by Melinda Gervasio corrected these problems and deleted too sensitive/personal e-mails. • Distributed in its present form by William Cohen. http://www.cs.cmu.edu/~enron/ • The Enron Data Set has become a kind of Drosophila for data mining researchers who want to use non reactive data.
The AOL Data Set (Search Requests) • In August 2006, AOL (America Online) published a huge data set of search requests of 650,000 subscribers. Making this data set public was motivated partly in compliance to requests by US state authorities, partly due to errors by employees (Wray, 2006). • The data have been sorted by anonymous user IDs. But soon it became obvious that it is possible that the queries in the data set can be traced back to the persons that entered them (Barbaro & Zeller, 2006). • As a consequence, AOL quickly closed down the Web site where the data has been published. • In the meantime, the data set has been downloaded several hundred times. A number of mirror sites have been set up such that the data is in fact available. • The AOL data set provoked a debate among the privacy “The number of things it reveals about individual people seems much too much. In general, you don’t want to do research on tainted data.” (Hafner, 2006)
Collecting all Data about a Person A number of projects work towards tracking a person’s entire existence • DARPA´s LifeLog Project (2003-2004) Cancelled for an unknown reason. It is possible, however, that LifeLog is still, but clandestinely still in development. • Microsoft‘s MyLifeBit Project • ACM Workshop on Continuous Archival & Retrieval of Personal Experiences (CARPE)
“A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility” Full-text search, text & audio annotations, and hyperlinks Vannevar Bush’s Memex Vision (1945)
A Personal Transaction Processing System for Everything Inspired by Memexwww.MyLifeBits.com
Import files MyLifeBits Shell GPS import & Map display Voice annotation tool VIBE logging Text annotation tool SenseCam Screen saver Legacy applications Internet Radio capture & EPG PocketPC transfer tool MAPI interface TV capture tool Browser tool files Outlook interface Legacy email client Telephone capture tool PocketRadio player IM capture TV EPG download tool MyLifeBits Software MyLifeBits store database
Discussion • Often, when studying social phenomena on the Internet, there is hardly any alternative to non reactive data. • Non reactive data may shed light on new social phenomena and facilitates studying the inner life of institutions • There are, however, many challenges • Turning thin data into rich and meaningful data (horizontal/vertical enlargement of data sets, usage of data mining techniques) • Addressing privacy issues carefully. • Data catastrophes (Enron, AOL) may give insight into social processes and/or institutions but raise severe ethical questions.
References Dholakia, N., & Zhang, D. (2000). Online Qualitative Research in the Age of E-Commerce: Data Sources and Approaches. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 5 (2). Retrieved September 4, 2006 from http://www.qualitative-research.net/fqs-texte/2-04/2-04dholakiazhang-e.htm. Frankfort-Nachmias, C., & Nachmias, D. (2000). Research methods in the social sciences (6th ed.).New York, NY: Wadsworth. Hofmann, K., Reed, C., & Holz, H. (2006). Unobtrusive Data Collection for Web-Based Social Navigation.In Workshop on the Social Navigation and Community-Based Adaptation Technologiesin Conjunction with Adaptive Hypermedia and Adaptive Web-Based Systems (AH’06) June 10 20th, 2006, Dublin, Ireland. Hafner, K. (2006). Researchers Yearn to Use AOL Logs, but They Hesitate. New York Times, August, 23. Webb, E. J., Campbell, D. T., Schwartz, R. D. D., & Sechrest, L. (2000). Unobtrusive measures. Thousand Oaks, CA: Sage. The Enron E-Mail Data Set http://www.cs.cmu.edu/~enron/ Environment Variables on HTTP Servers http://publib.boulder.ibm.com/infocenter/iseries/v5r3/index.jsp?topic=/rzaie/rzaieenvvar.htm Microsifts MyLifeBits Project www.MyLifeBits.com Comments on the End of the Lifelog Project http://www.defensetech.org/archives/000757.html