Download

1 / 26
260 likes | 440 Views
Outline – DSP Processors and Hardware. Week 1 Overview of DSP Processors First, second and third generation Week 2 Implementation – FIR and IIR filters Case study using 56000 series Week 3 Finite word length effects. Resources. http://www.tech.plym.ac.uk/spmc/elec327/home.html

E N D
Outline – DSP Processors and Hardware • Week 1 • Overview of DSP Processors • First, second and third generation • Week 2 • Implementation – FIR and IIR filters • Case study using 56000 series • Week 3 • Finite word length effects
Resources • http://www.tech.plym.ac.uk/spmc/elec327/home.html • Examples of code • Instructions • Student Portal • Coming soon!
Why use a DSP - economics YES NO • Low power requirements • Low real estate (licensed core) • Very fast and repetitive arithmetic (up to 8000MIPS) • High volume low cost • Dedicated DSP instruction set • MAC(D); Circ.Buff.; bit-rev • Real-time interrupt driven software • Instructions dedicated to specific applications • Audio; Digital Comms; Filtering; FFT • Large memory requirements • Rapid application development – low TTM • Prototype design • General purpose computing • GUI; database; gaming • Cooling & large PSU available • Require RTOS facilities • Networking; queues; pipes; semaphores etc..
fixed point(INTEGER arithmetic only) floating point(full IEEE floating point) • Shorter development time • Easy to perform complex operations • Translates to high level language more easily • Dynamic range is very high • Design ambition is much higher PRO’S Low Power – High Speed Lower Cost – suits high volume Lower silicon real-estate High precision arithmetic (with careful design) Good for specific apps. • Much longer development time • Dynamic range problems • Some operations are very inefficient (divide) • Difficult to perform non-standard DSP • Design ambition is reduced • Higher power • Higher cost • Larger silicon real-estate • Potentially lower precision arithmetic CON’S
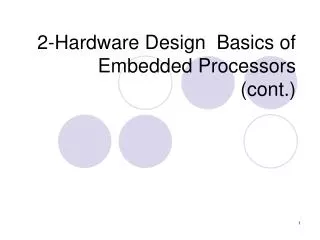
Motorola 56000 series • Key features • Generation 2 DSP • Dual Harvard Architecture • Separate Program and Data Memory • Data and coefficients fetched in 1 clock cycle • Separate X and Y data Memory • Custom DSP instructions • Supports circular addressing • Zero overhead DO loops / Repeats • MAC with shift • 24 bit word length; 56 bit accumulator • A favourite with audio
Example of a new generation DSPTMS320C64x – fixed point DSP • 1nS instruction time (1GHz) • SIMD / VLIW • 8 x 32bit instructions / cycle • 8 x independent function units • Six ALU’s • Single 32 / Dual 16 / Quad 8 • Two multipliers • Quad 16x16 • 8 of 8x8 • Up to 8000 MIPS (peak)
Revision – the FIR filter Filter Length=N h(k),k=0..N-1, are the filter coefficients x(n) are the input data samples y(n) are the output data samples acc=0.0;//Set accumulator to zero x(0) = new_sample; //new sample into buffer for (unsigned k=0; k<N; k++) //MAC acc = acc + x(k)*h(k); for (unsigned k=N-1; k>0; k++) //Shift data x(k) = x(k-1); Challenge – can you write a more efficient version with just one for-loop?
Illustrative Problem 1/2 n=1 taps=[0.25 0 0] y(n)=0.125 n=2 taps=[0.5 0.25 0] y(n)=0.4375 n=3 taps=[0.25 0.5 0.25] y(n)=0.5625 n=4 taps=[-0.25 0.25 0.5] y(n)=0.1875 n=5 taps=[0.75 -0.25 0.25] y(n)=0.25 See MATLAB code handout fir1.m
Implementation on DSP Processors • Special instructions • Multiply & Accumulate • MAC – multiply & accumulate (with shift) • MACD – MAC + move data • MACR – MAC + round result • Zero-overhead Repeat • REP • Modulo Arithmetic • Circular Addressing
56000 FIR Code example(See notes) • MOVE #XDATA,R0 ; Address register R0 = address of data samples • MOVE #COEFF,R4 ;Address register R4 = address of coefficients • MOVE #N-1,M0 ; Address modifier register M0 = buffer/modulo size • MOVEP X:INPUT,X:(R0) • ;Move (Peripheral) data into X memory at address pointed to by R0 • CLR A, X:(R0)+,X0 ,Y:(R4)+,Y0 ;Accumulator A=0, setup X0 and Y0 registers for first use** • REP #N-1 ;Repeat next instruction N-1 times • MAC X0,Y0,A X:(R0)+,X0 Y:(R4)+,Y0 • R4 = address of coefficients • MACR X0,Y0,A (R0)- • ;R0 = is decremented to position for next run, R4 is automatically correct. We could now jump to the MOVEP instruction if we so wished. **There is an error in the notes for 2004
Quantise coefficients • 2’s compliment arithmetic • For 16 bit coefficients – we call this 1.15 fixed point arithmetic • 0..65536 (0..FFFFh) • Total range is {0..(2^16)-1} • {1..(2^15)-1} are positive values • {2^15-(2^16)-1} are the negative values (msb is the sign) • Example: • 0.123 => (2^15)*0.123 = 4030 • Task: Convert this back to fractional arithmetic • Given that 65536==0, -0.123 = 65536(0)-4030=61506 • Task, calculate 0.5 - 0.123 using 16 and 24bit fixed point arithmetic - compare
Store in Y memory org y:0 ;Start address COEFF dc 0.5 ;24-bit filter coefficients dc 0.75 dc 0.25 Challenge Convert the above coefficients to 24-bit fixed point values
Multiply and Accumulate • MAC <24-bit reg>, <24-bit reg>,dest{A,B} • Can be X with X, X with Y or Y with Y • Example: A = A+0.123*0.456 • Start with A=0 • Convert 0.123 and 0.456 to 1.23 format • Multiply the result => 2.46 format • Shift left =>1.47 format • Add to result • If finished, round off result and store. • Convert back to fractional arithmetic to check result • TASK: • Repeat this twice – check result.
56K Repeat Instruction • RPT #N • Repeat the next instruction N times • N is a 16 bit value that is copied into the loop counter register (LC) • This cannot be interrupted • Fetch of next instruction is performed once • Cannot repeat itself of any type of “jump” instruction.
Modulo Arithmetic • Comes from the “remainder” of integer division • 0/4 = 0, 0%4 = 0 • 1/4 = 0, 1%4 = 1 • 2/4 = 0, 2%4 = 2 • 3/4 = 0, 3%4 = 3 • 4/4 = 1, 4%4 = 0 • 5/4 = 1, 5%4 = 1 • 6/4 = 1, 6%4 = 2 • 7/4 = 1, 7%4 = 3 • 8/4 = 2, 8%4 = 0 • Similar logic is used for the Address Registers Rn so they wrap around to the start address • TASK – What is 50%8 • 50 / 8 = 6.25 • 6 * 8 = 48, difference = 2 = modulus
IIR Filters • Advantages • Efficiency • Delay • Disadvantages • Requires high precision arithmetic • Round-off Error sensitivity • Phase distortion • More complex to implement • Overflows
IIR Filters – fixed point • Structure is important • Noise • Stability • Efficiency • Cascaded solutions are most common • Sources of noise • Summations=>round off error • Error feedback • Higher precision arithmetic • Not always effective • Complexity increases • See handout for self learning tutorial
IIR Structures • Each IIR should be of no more than 2nd order! • Cascaded 2nd order sections • Ordering is important to reduce round-off error • Parallel 2nd order sections • Partial fraction expansion – ordering not an issue • More storage and computation • (care is needed with repeated poles) • Canonic 2nd order • Less memory required, simple to implement • More noise sources • Direct 2nd order • More difficult to implement • Less noise sources – generally a better choice
Hardware constraints • Memory • Typically between 16Kb and 128Kb internal memory • Word-length • Precision of arithmetic • Overheads for extended precision • Speed • Number of clock cycles to execute: • E.g. A simple FIR filter program takes 12 + N-1 cycles to complete, where N is the filter length = 139. The clock speed is 10MHz. • What is the maximum sampling rate? • If the sampling rate is 100kHz, what is the maximum filter length N? • Delay in actual filter • Remember! Delay of a signal is not just due to clock cycles – there is inherent delay in the FIR / IIR filter itself (N-1)/2. What will be the total delay in the example above?
Finite word length effects 1 • Coefficient Quantization • Coefficients will be quantised to N bits, Q 1.(N-1) • This will effectively move the poles and zeros to “preferred positions” • Could go unstable! • Deviates from desired response • Coefficients >= 1 must be scaled
Finite word length effects 2 • Over-flow error • Result of summations over-flowing • FIR and IIR can suffer from this • IIR must never overflow as it will possibly go unstable! • FIR can overflow if it then “underflows” – also “SAT” instructions exist • Controlled with normalization (scaling) or with large accumulators
Finite word length effects 3 • Round off error • IIR only • Introduced with each SUM • Seriously affects performance of IIR • Tackled with either: • High precision arithmetic • Error feedback (ESS)
Error feedback - ESS • Critical to the success of fixed point IIR filters • (Although a bit beyond the scope of the course!) • Round-off error is fed back into the filter • Dramatically improves performance
Drills • DSP Overhead (delay and cycles) • Fixed point arithmetic • Coefficient quantisation • FIR (MAC and shift) • IIR • Round off errors
Drill 1 – Overhead calculation • MOVE #XDATA,R0 ; Address register R0 = address of data samples • MOVE #COEFF,R4 ; Address register R4 = address of coefficients • MOVE #N-1,M0 ; Address modifier register M0 = buffer/modulo size • MOVEP X:INPUT,X:(R0) • ;Move (Peripheral) data into X memory at address pointed to by R0 • CLR A, X:(R0)+,X0 ,Y:(R4)+,Y0 ;Accumulator A=0, setup X0 and Y0 registers for first use** • REP #N-1 ;Repeat next instruction N-1 times • MAC X0,Y0,A X:(R0)+,X0 Y:(R4)+,Y0 • R4 = address of coefficients • MACR X0,Y0,A (R0)- • This code is then repeated. There is some additional overhear for servicing interrupt routines, storing and writing results, serial ports etc (not shown), so assume this code takes a total of 45+(N-1) instructions to complete. • Sketch a diagram and describe how the circular buffer works • If the clock frequency Fclk=20MHz, and N=129, • what is the maximum sampling rate • What is the real-time delay through the system? • Draw a diagram to illustrate your answer • What are the possible sources of error? Can this go unstable?





![Global Digital Signal Processors [DSP] Market Forecast](https://cdn4.slideserve.com/1477223/marketsandmarkets-presents-dt.jpg)