Download
1 / 1
10 likes | 161 Views
Modeling Clutter Perception using Parametric Proto-object Partitioning. Experiments and Results. Method.

E N D
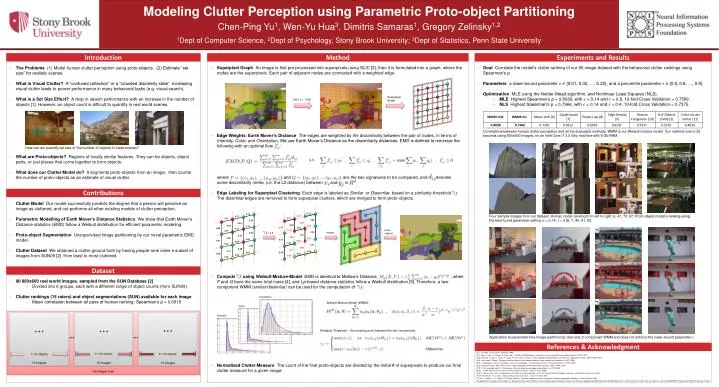
Modeling Clutter Perception using Parametric Proto-object Partitioning Experiments and Results Method Superpixel Graph An image is first pre-processed into superpixels using SLIC [3], then it is formulated into a graph, where the nodes are the superpixels. Each pair of adjacent nodes are connected with a weighted edge. Edge Weights: Earth Mover’s Distance The edges are weighted by the dissimilarity between the pair of nodes, in terms of Intensity, Color, and Orientation. We use Earth Mover’s Distance as the dissimilarity distances. EMD is defined to minimize the following with an optimal flow : where and are the two signatures to be compared, and denotes some dissimilarity metric (i.e. the L2 distance) between and in . Edge Labeling for Superpixel Clustering Each edge is labeled as Similar or Dissimilar, based on a similarity-threshold . The dissimilar edges are removed to form superpixel clusters, which are merged to form proto-objects. Compute using Weibull-Mixture-Model EMD is identical to Mallow’s Distance, , when P and Q have the same total mass [4], and Lp-based distance statistics follow a Weibulldistribution [5]. Therefore, a two-component WMM (similar/dissimilar) can be used for the computation of . Normalized Clutter Measure The count of the final proto-objects are divided by the initial # of superpixelsto produce our final clutter measure for a given image. Contributions Clutter Model Our model successfully predicts the degree that a person will perceive an image as cluttered, and out-performs all other existing models of clutter perception. Parametric Modelling of Earth Mover’s Distance Statistics We show that Earth Mover’s Distance statistics (EMD) follow a Weibull distribution for efficient parametric modeling. Proto-object Segmentation Unsupervised image partitioning by our novel parametric EMD model. Clutter Dataset We obtained a clutter ground truth by having people rank order a subset of images from SUN09 [2] from least to most cluttered. 1Dept of Computer Science, 2Dept of Psychology, Stony Brook University; 3Dept of Statistics, Penn State University [1] J. M. Wolfe. Visual search. Attention, 1998. [2] J. Xiao, J. Hays, K. Ehinger, A. Oliva, and A. Torralba. SUN database: Large-scale scene recognition from abbey to zoo. In CVPR, 2010. [3] R. Achanta, A. Shaji, L. Smith, A. Lucchi, P. Fua, and S. Susstrunk. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE TPAMI, 2012. [4] E. Levina and P. Bickel. The earth mover’s distance is the mallows distance: some insights from statistics. In ICCV, 2001. [5] G. J. Burghouts, A. W. M. Smeulders, and J.-M. Geusebroek. The distribution family of similarity distances. In NIPS, 2007. [6] D. Comaniciu and P. Meer. Mean shift: A robust approach toward feature space analysis. IEEE TPAMI, 2002. [7] P. F. Felzenszwalb and D. P. Huttenlocher. Efficient graph-based image segmentation. In ICCV, 2004. [8] M. J. Bravo and H. Farid. A scale invariant measure of clutter. Jounal of Vision, 2008. [9] M. L. Mack and A. Oliva. Computational estimation of visual complexity. In the 12th Annual Object, Perception, Attention, and Memory Conference, 2004. [10] R. Rosenholtz, Y. Li, and L. Nakano. Measuring visual clutter. Journal of Vision, 2007. [11] M. C. Lohrenz, J. G. Trafton, R. M. Beck, and M. L. Gendron. Amodel of clutter for complex, multivariate geospatial displays. Human Factors, 2009. We appreciate the authors of C3 model, Dr. Burghouts of [5], and Dr. Matthew Asher for discussions and code sharing. This work was supported by NIMH Grant R01-MH064748 to G.J.Z., NSF Grant IIS-1111047 to G.J.Z. and D.S., and the SUBSAMPLE Project of the DIGITEO Institute, France. Chen-Ping Yu1, Wen-Yu Hua3, Dimitris Samaras1, Gregory Zelinsky1,2 References & Acknowledgment 90 800x600 real world images, sampled from the SUN Database [2] • Divided into 6 groups, each with a different range of object counts (from SUN09). Clutter rankings (15 raters) and object segmentations (SUN) available for each image • Mean correlation between all pairs of human ranking: Spearman’s ρ = 0.6919 Dataset Introduction The Problems (1) Model human clutter perception using proto-objects. (2) Estimate “set size” for realistic scenes. What is Visual Clutter? A “confused collection” or a “crowded disorderly state”. Increasing visual clutter leads to poorer performance in many behavioral tasks (e.g. visual search). What is a Set Size Effect? A drop in search performance with an increase in the number of objects [1]. However, an object count is difficult to quantify in real world scenes. What are Proto-objects? Regions of locally similar features. They can be objects, object parts, or just pieces that come together to form objects. What does our Clutter Model do? It segments proto-objects from an image, then counts the number of proto-objects as an estimate of visual clutter. Goal Correlate the model's clutter ranking of our 90 image dataset with the behavioral clutter rankings using Spearman's ρ. Parametersa lower-bound parameter {0.01, 0.02, …, 0.20}, and a percentile parameter {0.5, 0.6, …, 0.9}. Optimization MLE using the Nelder-Mead algorithm, and Nonlinear Least Squares (NLS). • MLE Highest Spearman’s ρ = 0.8038, with = 0.14 and = 0.8. 10-fold Cross Validation = 0.7599. • NLS Highest Spearman’s ρ = 0.7966, with = 0.14 and = 0.4. 10-fold Cross Validation = 0.7375. Superpixel Graph SLIC k = 1000 at TLT Media Lab of Stony Brook University Correlations between human clutter perception and all the evaluated methods. WMM is our Weibull mixture model. Our method runs in 20 seconds using 800x600 images, on an Intel Core i7 3.0 Ghz machine with 8 Gb RAM. How can we quantify set size or the number of objects in these scenes? Four sample images from our dataset. Human clutter ranking from left to right: 6, 47, 70, 87; Proto-object model’s ranking using the best-tuned parameter setting (= 0.14, = 0.8): 7, 40, 81, 83. proto-objects merge = 0.6 0.15 0.15 0.77 0.77 0.11 0.11 0.35 0.35 0.63 0.63 0.28 0.75 0.28 0.86 0.75 0.12 0.86 0.12 0.77 0.77 0.04 0.04 0.31 0.31 0.82 0.81 0.82 0.21 0.81 0.93 0.21 0.93 0.32 0.32 0.65 0.65 0.68 0.68 0.71 0.05 0.71 0.38 0.05 0.23 0.38 0.23 0.75 0.75 Weibull-Mixture Model (WMM): Orientation Color Intensity Similarity Threshold – the crossing point between the two components: Application to parameter-free Image partitioning: Use only 2-component WMM and does not enforce the lower-bound parameter . 1~10 objects 51~60 objects 31~40 objects 15 images 15 images 15 images 90 images total






















