Download

1 / 23
230 likes | 414 Views
Computational Core for Tomato Metabolomics. PI Indira Ghosh JNU (Coordinating PI) Abhijit Mitra IIIT-H. C0-PI Vikram Pudi IIIT-H Nita Parekh IIIT-H. Importance of Metabolomics. Unraveling the complex relationship between genes molecular phenotypes and environmental and

E N D
Computational Core for Tomato Metabolomics PI Indira Ghosh JNU (Coordinating PI) Abhijit Mitra IIIT-H C0-PI Vikram Pudi IIIT-H Nita Parekh IIIT-H
Importance of Metabolomics Unraveling the complex relationship between genes molecular phenotypes and environmental and genetic stimuli Understanding of physiological and pathological state of living systems Genetic and environmental stimulus Biological systems: biofluids, cells, tissues, …… ……whole organisms Quantified analyzable response ? ??
GOAL • Develop and maintain a generic Metabolomics LIMS and Database facility: • Which seamlessly integrates with other ‘omics’ databases • Along with relevant Bioinformatics and Chemoinformatics databases, resources and tools • IIIT Hyderabad has both the expertise as well as the experience in building large systems, such as this, which can function as a core national facility supporting plant metabolomics research at a nation wide scale Document summarization E-Sagu Machine translation • To lay the foundations of such a system in close collaboration with the Tomato Metabolomics Network. The work flow and deliverables discussed here combines • Bioinformatics, chemoinformatics and system building expertise available at JNU and IIIT-H • With experimental inputs from the networked laboratories
OBJECTIVES OF THE CURRENT PROJECT • Develop a core Metabolomics LIMS and Database facility as an integral part of the tomato metabolome network project • Develop a metabolomic relational database using SQL and XML platforms for • effective and efficient handling of the volume and complexity of • metabolomic data • serving data and analyses back to experimentalists • Develop models of metabolite pathway networking and validate them against • transcriptome/metabolome data • proteome data • In concert with other groups in the tomato metabolomics network develop • software suitable for • predicting networks of metabolite formation data • analysis/ storage and retrieval of metabolites data
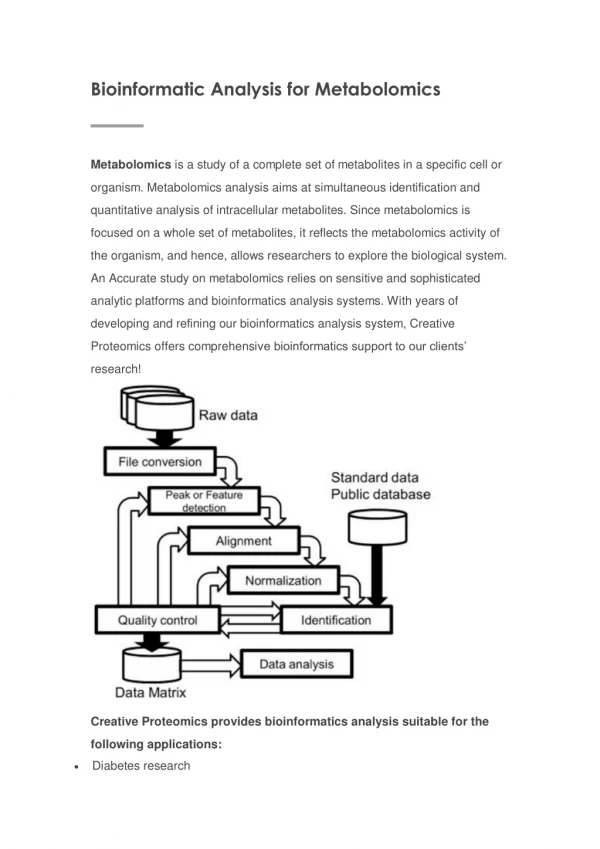
Recap of DB Challenges • Variety of data • chemical structures, reactions, metabolites, concentrations, pathways, locations, NMR spectra, MS, GC-MS retention indices, physical properties, disease associations • Non standard search • e.g. by chemical structure, MS spectrum, etc. including regular text search • Terabytes to store and analyze • Gigabytes of data transfer Work flow Comprehensive database for Data analysis and interpretation Functional annotation Metabolite identification • Noise reduction • Peak detection • Chromatogram alignment • Normalization • Format conversion Pattern recognition
Recap of LIMS Challenges • Variety of instruments • E.g. HPLC, UPLC, GC-MS, FTIR, LC-MS, NMR • Variety of routine tasks • Sample tracking, Storage of methods, protocols and SOPs, Entry of daily lab diaries, Data time-stamps, Regular data-backup, Resource and personnel management, Data validation, Lab audits, Lab and data security • Collaboration among several labs • Front-end design of a variety of reports (by molecule, by expt sample, etc.) Data integration Efficient storage, access, comparison and exchange Genomics Proteomics Metabolomics Data standardization Transcriptomics
The LIMS is the central component. It provides an interface to the users to access the data and analyze it. It accesses the data sources and stores the data in a data warehouse, suitable for user exploration and data mining analysis. Data Sources Spectral Data Data Warehouse LIMS Analysis Users • The work on this project will be organized along three interrelated activities: • Metabolomics database, metabolomic LIMS and data standards (IIIT-H) • Spectral analysis tools for metabolomics (JNU) • Bioinformatics and Modeling of pathway (IIIT-H + JNU)
Deliverables Metabolomics database, metabolomic LIMS and data standards IIIT-H Testing Requirement analysis Implementation Deployment Prototype Refactoring Software Architecture design
DATA CENTER Bioinformatics support to Data center Spectra based Computer-Assisted Structure Elucidation system (CASE) Spectral analysis tools for metabolomics JNU Bioinformatics and Modeling of pathway IIIT-H + JNU Metabolic pathway analysis Topological analysis Comparative genome analysis Deliverables
Computational Requirements (LIMS/Database) • 2 storage servers • Terabytes of data requires a dedicated storage server along with backup facility • 1 blade server • Running database queries on terabytes of data cannot be done without high-end computational resources • 1 high-end network switch • to connect the servers to each other and to the internet • 1 hardware firewall • for data and system security • Cooling equipment • PCs for staff (11 total)
Software Requirements (LIMS/Database) • Windows Server 2008 • many available metabolomics software runs only on Microsoft Windows[fiehnlab.ucdavis.edu/staff/kind/Metabolomics/Structure_Elucidation/] • Data Mining & Warehousing • needed to allow data to be integrated smoothly from a variety of sources into a single repository and for performing OLAP queries and standard data analysis
Manpower (LIMS/Database) • 1 research scientist (bioinformatician) • To provide domain expertise • 1 software engineer • To design maintainable software; ensure all software modules work together; coordinate programmers • 5 programmers • database backend implementation and data analysis • web interface • data transformation • search and reporting • scalability and security • 5 data entry personnel • actually for writing scripts for entry of existing data (explained in next slides) • 3 technical assistants • Admins for hardware, network, OS, database, LIMS, and for backup Manpower is needed not only for developing the facilities. The facilities need constant up gradation and maintenances
Experience with HMDB • Data was crawled and stored from www.hmdb.ca • All the database tables required for storing this data were designed and created • The tables were populated with crawled data • A web-interface was provided to query the database, perform standard searches and provide online reports
Experience with HMDB • Simply this much took 3 months of effort of 6 programmers • We need sufficient programmers to perform such tasks for entering data from existing sources • We have planned for multitasking by programmers and data entry personnel and have actually requested for less