Download

1 / 36
360 likes | 496 Views
Linguistica computazionale: come accedere all’informazione codificata nel linguaggio naturale (seconda parte). Cristina Bosco 2014 Informatica applicata alla comunicazione multimediale. NLP e subtask. Ci focalizziamo su alcuni subtask rappresentativi: Information Retrieval

E N D
Linguistica computazionale:come accedere all’informazione codificata nel linguaggio naturale(seconda parte) • Cristina Bosco • 2014 • Informatica applicata alla comunicazione multimediale
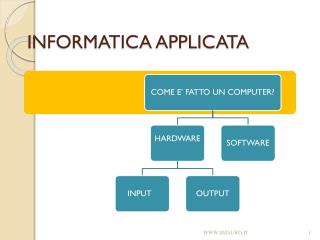
NLP e subtask • Ci focalizziamo su alcuni subtask rappresentativi: • Information Retrieval • Sentiment Analysis and Opinion Mining • • Part of Speech Tagging • Parsing
NLP, algoritmi e risorse • Per tutti i task di NLP occorrono degli algoritmi e delle risorse linguistiche: • Information Retrieval > algoritmi di matching e ranking + lessici • Sentiment Analysis and Opinion Mining > algoritmi di analisi del linguaggio + lessici affettivi e corpora annotati
NLP, algoritmi e risorse • Per tutti i task di NLP occorrono degli algoritmi e delle risorse: • • Part of Speech Tagging > algoritmi di analisi morfologica + lessico morfologico e corpora annotati • Parsing > algoritmi di analisi sintattica + base di conoscenza morfo-sintattica e corpora annotati
Information Retrieval Estrazione di informazione NON strutturata L’input è un insieme di documenti piuttosto ampio, mentre l’output è un insieme di documenti più piccolo È il lavoro che fanno i motori di ricerca su Internet
Information Retrieval In cosa consiste: dato l’input (insieme di documenti) ed una query dell’utente (una o più parole), restituisce come output un sottoinsieme dei documenti di input che comprende solo i documenti pertinenti alla query
Information Retrieval Approccio base: Documento e query sono visti come vettori di parole (bag of words o sintagmi) Valutazione della similarità tra documenti e ordinamento in base alla similarità; in questa valutazione si cerca di eliminare il “rumore” (= raffinamento) e di “pesare” i termini (= weighting)
Information Retrieval Raffinamento dell’approccio: Riconoscimento di categorie di parole Rimozione di stop words Riconoscimento di radici (stemming) Phrasing Pesatura dei termini (term weighting) Query expansion
Sentiment Analysis e opinion mining I social media (Facebook, Twitter, siti di recensione...) sono luoghi in cui le persone esprimono opinioni e sentimenti. Le tecniche di NLP consentono l’estrazione di sentimenti ed opinioni dai testi.
Sentiment Analysis e opinion mining • Lo scopo della SA & OM: • scoprire il gradimento di un prodotto • rilevare fattori socio-economici, come la felicità soggettiva • verificare l’orientamento verso personaggi pubblici • fare previsioni sulle elezioni politiche.
Sentiment Analysis e opinion mining Come funziona? L’estrazione di sentimenti e opinioni si basa sul rilevamento di parole dotate di polarità (positiva, negativa ad es.) “strage” > NEG “felice” > POS Si usano risorse: lessici appositi dove sono classificate le parole dotate di polarità.
Sentiment Analysis e opinion mining Come funziona? Si usano risorse che sono collezioni di emoticon ad emoji, quindi caratteri non testuali, con associata una polarità.
Sentiment Analysis e opinion mining Quali algoritmi si usano? In primo luogo si analizzano i post per trovarci dentro le parole e gli emoticons/emoji che hanno polarità. La polarità di un post dipende dalle parole emoticons/emoji che esso contiene, ma dipende anche dal modo in cui le parole sono associate.
Sentiment Analysis e opinion mining Quali algoritmi si usano? Per ora si applicano tecniche rozze che non tengono conto della struttura della frase. Ma senza tenere conto della struttura della frase si possono fare errori. Ad es. “io sono molto felice” e “Oggi non sono per nulla felice” contengono la stessa parola affettiva, ma non la stessa polarità.
Sentiment Analysis e opinion mining Quali algoritmi si usano? Per ora si applicano tecniche rozze che non tengono conto della pragmatica. Ma senza tenere conto del fatto ad es. che un post è ironico si possono fare errori. Ad es. “Ieri mi sono rotto un piede. Proprio una bellissima giornata!” non la stessa polarità di “Ieri mi sono davvero divertito. Proprio una bellissima giornata!”.
Sentiment Analysis e opinion mining Una soluzione è quella di basarsi sulla statistica. Percentualmente i post che contengono una certa parola avranno una certa probabilità di essere dotati di una certa polarità. Ad es. tra 100 post con la parola “felice” 90 saranno POS e 10 NEG
Sentiment Analysis e opinion mining Come si fa ad avere le informazioni che ci consentono di dire quali sono le percentuali? Si utilizzano i corpora di dati linguistici annotati. Sono raccolte di post a cui degli esseri umani hanno associato una polarità. Si tratta di un lavoro collettivo perchè non tutti sono d’accordo sull’associazione post-polarità per tutti i post.
Sentiment Analysis e opinion mining Cosa fa un sistema di sentiment analysis? Dato un insieme di post deve dire per ognuno se esprime un sentimento positivo o negativo. Per farlo guarda un corpus di post con annotata la polarità e ne estrae delle regolarità.
NLP e valutazione Per tutti i task di NLP occorrono dei metodi per la valutazione del risultato ottenuto, per capire se l’algoritmo funziona e svolge il suo compito e se le risorse utilizzate contengono tutta la conoscenza necessaria.
(Valutazione?) Per qualunque task di NLP la valutazione è un aspetto fondamentale. Si tratta di un processo complesso e sempre soggetto a revisione … le misure proposte oggi potrebbero essere criticate e sostituite domani. Il metodo più diffuso consiste nel confronto tra le prestazioni di un sistema e quelle di un essere umano.
(Valutazione?) L’idea di basare la valutazione sul confronto tra macchina ed essere umano è storicamente il primo metodo proposto per l’IA, teorizzato da Alan Turing nel 1950. Questo metodo è stato applicato in particolare alla Traduzione Automatica nell’ambito della stesura del rapporto ALPAC.
(Valutazione?) In cosa consiste il Test di Turing? È un criterio per determinare se un computer è in grado di pensare. Tale criterio era già stato delineato da Cartesio nel Discorso sul metodo (1637).
(Valutazione?) Turing si ispira al "gioco dell'imitazione” a tre partecipanti: un uomo A, una donna B, una terza persona C C è tenuto separato dagli altri due e deve porre domande per stabilire quale è l'uomo e quale la donna.
(Valutazione?) A deve ingannare C e portarlo a fare un'identificazione errata, mentre B deve aiutarlo. Affinché C non possa disporre di alcun indizio (come l'analisi della grafia o della voce), le risposte alle domande di C devono essere scritte a macchina.
(Valutazione?) Nel test di Turing una macchina si sostituisca ad A (o a B). Se C indovina chi è l'uomo e chi è la donna è in percentuale simile prima e dopo la sostituzione di A (o B) con una macchina, allora la macchina stessa dovrebbe essere considerata intelligente, dal momento che - in questa situazione - sarebbe indistinguibile da un essere umano.
(Valutazione?) Turing era convinto che entro l’anno 2000 sarebbero state create macchine in grado di replicare la mente umana e superare il “test di Turing”, a cui sottoporre una macchina per scoprire se può pensare.
Sentiment Analysis e opinion mining Cosa fa un sistema di sentiment analysis? Dato un insieme di post deve dire per ognuno se esprime un sentimento positivo o negativo. Come si valuta la prestazione di un sistema di sentiment analysis? Si costruisce un corpus di post con annotata la polarità e si confronta con il risultato restituito dal sistema.
(Valutazione?) L’entusiasmo di Turing è condiviso e continua ad esserlo nei decenni. Nel 1968, Stanley Kubrik, nel film “2001 Odissea nello spazio”, immagina che nel 2001 lo sviluppo dell’IA sia stato tale da poter costruire macchine pensanti e parlanti. Nel 1982, Ridley Scott ambienta nel 2019 il film “Blade Runner”, in cui macchine che sono in grado di superare il test di Turing sono realtà.
Information Retrieval Come si valuta il risultato? Recall = numero documenti rilevanti trovati / numero documenti rilevanti esistenti Precision = numero documenti rilevanti trovati / numero documenti trovati
Information Retrieval Come si valuta il risultato? supponiamo che la nostra query sia “gatto” e che nel nostro insieme di 100 documenti ce ne siano 10 che parlano di gatti; vorremmo che il sistema di IR trovasse questi 10. La recall è una misura di completezza che ci dice se tutti i documenti rilevanti sono stati trovati dal sistema.
Information Retrieval Come si valuta il risultato? supponiamo che la nostra query sia “gatto” e che nel nostro insieme di 100 documenti ce ne siano 10 che parlano di gatti; vorremmo che il sistema di IR trovasse questi 10. Se il sistema trova 10 documenti rilevanti sui 10 rilevanti esistenti, la recall vale 10/10 = 1. Se il sistema trova 5 documenti rilevanti sui 10 rilevanti esitenti, la recall vale 5/10 = 0,5.
Information Retrieval Come si valuta il risultato? supponiamo che la nostra query sia “gatto” e che nel nostro insieme di 100 documenti ce ne siano 10 che parlano di gatti; vorremmo che il sistema di IR trovasse questi 10. La precision è una misura di esattezza che ci quanti dei documenti che il sistema trova sono rilevanti.
Information Retrieval Come si valuta il risultato? supponiamo che la nostra query sia “gatto” e che nel nostro insieme di 100 documenti ce ne siano 10 che parlano di gatti; vorremmo che il sistema di IR trovasse questi 10. Se il sistema trova 10 documenti e tutti e 10 sono rilevanti, la precision vale 10/10 = 1. Se il sistema trova 20 documenti di cui 5 rilevanti e 15 non rilevanti, la precision vale 5/20 = 0,25.
Sentiment Analysis e opinion mining Cosa fa un sistema di sentiment analysis? Dato un insieme di post deve dire per ognuno se esprime un sentimento positivo o negativo. Come si valuta la prestazione di un sistema di sentiment analysis? Si costruisce un corpus di post con annotata la polarità e si confronta con il risultato restituito dal sistema.