Download

1 / 12
• 120 likes • 179 Views
Synthesis Data Sets from Process Studies.

E N D
Synthesis Data Sets from Process Studies Synthesis data set: An integrated data set from a field campaign (e.g., ocean, atmosphere, land observations) including basic and derived fields as required, placed in a format in which budgets can be computed, simple models can be run, and comparisons with model output can readily be made. Objectives: • To motivate and facilitate integrative diagnostic and modeling studies • To serve as benchmarks for assessing and validating models, and improving parameterizations • To bring additional value to process studies beyond individual PI contributing elements
GARP Atlantic Tropical Experiment What is GATE The Global Atmospheric Research Program's (GARP) Atlantic Tropical Experiment (GATE) was conducted in the summer of 1974. One of the central objectives of GATE was to understand the scale interactions between convective activity and large-scale weather systems (ICSU/WMO, 1972); i.e., to better understand the mechanism or mechanisms by which deep cumulus convection is organized by the synoptic or large-scale motions and how the resulting convective activity affects the synoptic motions that can be resolved in large-scale models. Phase III of GATE covers the period from 00 GMT 30 August to 24 GMT 18 September. The data residing at Colorado State University (CSU) came originally from Prof. Michio Yanai's group at UCLA, which were objectively analyzed by Esbensen and Ooyoma of Oregon State University. The variables were gridded on 1x1 degree square grid box, covering an area of 9x9 degree square. There are 19 layers in the vertical. See gate.rad file for the coordinate information. Purpose This data set was assembled by Dave Randall’s group at CSU, originally for use in SCMs, but it also has been used for forcing CRMs. http://kiwi.atmos.colostate.edu/scm/gate.html “SCM GATE”
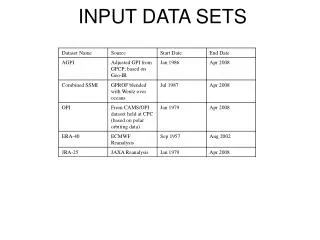
About the Dataset Files The format of files shown below can be found in README.GATE. It is advisable to download and "save to file" the datafiles with your browser as some are over 2MB in size. All files below may also be retrieved via the Data link above. Moist static energy, GATE.H Saturation moist static energy, GATE.HS Vertical velocity in pressure coordinate, GATE.OMG Water vapor mixing ratio, GATE.Q Apparent heat source, GATE.Q1 Apparent moisture sink, GATE.Q2 Radiative heating rate as calcualted by Cox and Griffith (1979), gate.rad Dry static energy, GATE.S Temperature, GATE.T X-component wind, GATE.U Y-component wind, GATE.V Vertical vorticity, GATE.VOR Outgoing longwave radiation fluxes can be read from NCAR mass storage usingmurakami-olr.F Horizontal advection of temperature, gate.Htemp_sui Horizontal advection of water vapor mixing ratio, gateHqv_sui Sea surface temperature, GATE.daily-sst
(NOV 92 – FEB 93) MOIST (~2-3% moist bias) DRY (~5% dry bias)
Major change in cloud mass flux following humidity correction DOUBLE ITCZ Ciesielski et al. (2003 J.Climate) SINGLE ITCZ BETTER AGREEMENT Vaisala (dry) VIZ (moist)
http://tornado.atmos.colostate.edu/togadata/ifa_data.html Version 2.1 IFA-averaged fields for TOGA COARE in support of SCMs, CRMs (v2.0 released 04/26/02, v2.1 released 10/21/02) <> New COARE synthesis data set released 10 years after experiment following correction of sounding humidity data • basic fields (u, v, T, q, z) • derived fields (advective tendencies) • radiation • SST, surface sensible and latent heat fluxes
Development and Application of EPIC Integrated Datasets for Atmospheric and Coupled Modeling PI: Christopher S. Bretherton, University of Washington Co-I: Robert Cifelli, Colorado State University Funding Period: 05/01/06 - 04/30/09 We propose to create and publicize two such integrated datasets, one describing a mean cross-section of both the atmosphere and ocean along the 95W TAO buoy line between 1S and 12N, and a second describing three weeks of variability in the ITCZ around 10N 95W. Each dataset is primarily based on distillations of existing EPIC data products, though we include a subcontract to the Co-I for enhancing the C-band radar data and its implications for rainfall distribution in the ITCZ dataset. We will use these datasets to force and compare with cloud-resolving model simulations, single-column and short-term forecast, versions of the GFDL, NCEP GFS/CFS (using the NOAA Climate Testbed), and NCAR global atmospheric models, and 95W climatologies from coupled versions of these models. We will work with model developers from these centers to do sensitivity studies aimed at improving relevant physical parameterizations and reducing their biases in the tropical Pacific Ocean.
NAME Synthesis Data Sets (November 2005) SWG7.5 Report The NAME Data Management team is willing to support a unified land surface data set. Update of NAME Value-added data products List of recently ‘delivered’ value added data products: NAME Radar composites; jointly developed by Col. State U. and NCAR NAME atmospheric analyses; developed by Col. State U. NAME data impact on RCDAS; performed by NCEP/CPC List of ‘forthcoming’ value-added data products: Merged rain gauge data set (hourly and daily) for 2004; developed by NCAR/EOL and the NAME Precip. Analysis Group Merged atmospheric sounding composite; NCAR/EOL and NAME sounding teams Land surface dataset; NCAR/EOL, U. Washington, NCEP
Creation of Synthesis Data Sets: Issues • Past synthesis data sets have come about through workshops, working groups, and individual or joint PI-driven efforts. Is this process optimal? Have there been missed opportunities? • Should there be “standard” synthesis data sets (e.g., forcing fields for models) from every field campaign? If so, what types are most useful, who should create them, and how should they be funded? • Different components of field campaigns have varying timetables for QC and release of data. Some take months, some years. How will this affect the creation of synthesis data sets? • How do we communicate information about such data sets, and what tools should be provided to query and access data? • Who maintains stewardship of the data sets, and for how long? Are there cost-effective solutions? • How to follow up with action on this problem: workshops, telecons, side meetings?