Download

1 / 41
410 likes | 427 Views
Learn about the AMI system, its features, utilities, and data sources for Atlas Metadata. Discover how AMI serves as a mediator interface for various data sources.

E N D
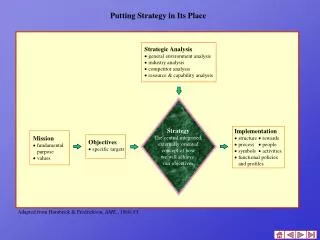
AMI and its place in ATLAS Metadata Solveig AlbrandJerome FulachierFabian Lambert 05/01/2020 S.A. S.A. 1
Part I Introduction to AMI Data sources Known problems S.A.
Brief Intoduction to AMI ATLAS Metadata Interface A generic catalogue application. Used by several ATLAS applications. AMI TagCollector Application specific layer Datasets SQ NICOS When you make a catalogue in AMI you immediately get a web browser interface, a python CLI + generic query and data manipulation functions. Generic functions Connections ORACLE mySQL S.A.
Interfaces ami.in2p3.fr pyAMI AMI dataPuller • Web interface : • Browsing + all server commands (add, clone, update) if authorised. • Personal pages with bookmarks • pyAMI : • A SOAP web service + examples of use in the ATLAS release. All server commands accessible. • Data Puller Tasks (see next slide) S.A.
Data Puller Tasks • Run in a separate instance of AMI. • Each task runs in its own thread. • TaskThreads managed by a “master” thread and database tables. • Can modify frequency of tasks, and mutual exclusion dynamically. • Email alerts • Watch dog mechanism. S.A.
AMI Features • Uses "MQL" from GLite. Users do not need to know the relational structure of the tables. • A powerful graphic query builder for ad-hoc queries. • Multi-threaded queries and "natural" partioning. • Supports some schema evolution. • Indirect DB connections. RDBMS & database site transparent for user. • Efficient connection pool and transaction management. • Exploits prepared statements. • Manages its own user database, and autorisation. (users roles commands catalogues). VOMS proxy upload possible. • Possibility to browse third party databases if they have a simple relational structure. (Primary key/ Foreign key) S.A.
OVERVIEW PAGE • AMI catalogues OFFICIAL datasets (data_*, mc_*, and SOME physics group datasets.No USER datasets as yet. • By default :- • No searching in "archived" catalogues. • Datasets known to be bad are hidden. S.A.
Search Results S.A.
AMI is a MEDIATOR interface • “a software module that exploits encoded knowledge about some sets or subsets of data to create information for a higher layer of applications”. (Gio Wiederhold, Mediators in the architecture of future information systems, IEEE Computer Magazine, Vol 25, No3, p38-49 March 1993) • To put it another way, a mediator is an application which puts some domain expertise between the user and a group of data sources, so that information coming from these different sources can be aggregated. S.A.
Sources of AMI data Real data : From the Tier 0 : DAQ data, and first reconstruction is registered in AMI < 5 minutes after it is declared “ready” (both datasets and files). Monte Carlo and reprocessing. From the Task Request DB : Tasks, dataset names, MC and reprocessing configuration tags ("AMI tags") From the production DB : Finished tasks – files and metadata. From physicists with AMI writer role. M.C. GEN datasets MC Dataset number info, physics group owner,… Corrected cross sections and comments. (coordinated by Borut K and Claire Gwenlan.) Tier0 configuration tags (AMI tags for real data.) … N.B. I have neglected Tag Collector here and in what follows – for clarity 05/01/2020 S.A. S.A. 10
Tier 0 "AMITags" are written in AMI before use Ready Tier 0 Done This AMI task reads datasets, files and some metadata from Tier 0 using a semaphore mechanism. Simple and efficient – AMI only get datasets when they are completed. AMI S.A.
AKTR (Task Request) AKTR Read AMITags AMI • Reads new tasks, once they are no longer pending, if they are not aborted before submission. • Reads provenance, • Reads updates to a bad status. • Reads MC and reprocessing AMITags. • N.B. Does NOT read finished/done status here. S.A.
ProdDB ProdDB AMI • Follows RUNNING status of tasks. • When FINISHED reads metadata.xml for all jobs of the task. S.A.
DQ2 DQ2 DQ2Info Data deleted nomenclature AMI S.A.
PROBLEMS • Problems we've been dealing with for such a long time that it's almost not worth mentioning them, as I fear that in some cases nothing will ever get done. "Minor Problems" • Mechanism problems. Major problems we really SHOULD do something about • Content problems. I am not competent to say anything about these, so I won't. S.A.
Minor Problems • Tier 0 : No update mechanism. (Have not needed one up to now.) • AKTR : • Provenance very acrobatic. (c.f. AMI Review 2006). Input Dataset column in AKTR DB very messy. • No "dataset container" "task number" link • General : No finite state description as far as I know. We had to guess. It is sometimes confusing for users. Dataset states need some work from the collaboration. S.A.
Important Problems - 1 • Validation of metadata.xml • Validation of metadata output is not part of release validation, and it should be. • Is it entirely reliable even when it works? There have been many examples of one job out of many which fails to produce metadata. Why are these jobs still declared "done"? The result is that a wrong number of files/events is reported. (https://savannah.cern.ch/bugs/?70591It's because we run with "--ignoreerror=True" . Pavel suggested how to fix it. Alvin agreed. Will anything get done?) S.A.
Important problems - 2 • Relation between TRANSFORMS (e.g.https://twiki.cern.ch/twiki/bin/view/Atlas/RecoTrf ) and METADATA. • An improved grammar for metadata.xml (task aware so more compact) is available, but has never been put into production. • Manpower - Who is going to replace Alvin Tan? S.A.
Important problems - 3 • Lack of coherence between AMI and DQ2 for dataset container contents (and status). • At the moment AMI guesses that a finished TID dataset will be placed in its container by the production system when the task is declared FINISHED, using information from AKTR/ProdDB) This is sometimes the case, but not always. What is the logic? Is it documented? • Solution Stop guessing and get the info from DQ2. Have not done this up to now, but currently working on improving AMI DQ2 information exchange using ACTIVE MQ server. Need confirmation that this can go into production. • Need a policy for file status, but that can come later when we have more Active MQ experience. S.A.
Requirements • Our requirements come from many sources. • Data Preparation coordination + physics groups. • Reprocessing Coordination • Metadata coordination • MC generator group • Fast Reconstruction/Tier 0 • DA tools (Ganga) • ADC (DQ2) • User suggestions. • Coming soon : • better treatment of Physics Containers, • better support for physics groups, • User datasets ??? • Reported until recently to DB, and "close contact" with Data preparation (AMI review recommendations). Now in ADC dev (as well as? instead of ?) S.A.
Part II The ATLAS metadata context S.A.
Other Metadata Applications in ATLAS • There are many metadata applications in ATLAS and many granularities of data/metadata. • Metadata Task Force Report 2006/2007 S.A.
Metadata use (MTF report) • To determine the status of a process such as calibration or analysis (e.g. stage of processing). • To provide statistics on some process without having to read in large amounts of data (e.g. run completed gracefully or terminated abnormally). • To provide early indications of problems and clear indications of their source (e.g. detector status summary). • To allow the cross referencing of data in different data stores or different formats (conditions, events, TDAQ), (POOL, n-tuple), … • To locate other types of data. • To encapsulate the state of a process so that it can be repeated or easily modified (e.g.versions of software and configuration used for a process). S.A.
Granularity of metadata (MTF Report) Event ; 1 File ; 102 – 104 Luminosity Block ; 104 Run ; 105-106 Datastream per run;104 – 106 Dataset ;105 – 109 "A means to navigate between these granularities of scale will be needed to support queries where the user indicates a requirement on a given granularity but where the data needed is stored in a different granularity." S.A.
Metadata Flow (MTF Report) • From the detector to analysis • From the MC production to analysis • Through different granularities S.A.
There are many metadata applications in ATLAS • Developed independently. • Different positions in the metadata flow. • Different DB structures and interface choices. • Links are ad hoc – these has never been any concerted design or effort to develop an overall metadata structure (with the notable exception of dataset nomenclature). S.A.
It is too complicated to try and classify all of them by granularity. And not very useful! Application S.A.
User Data Discovery Intefaces • The AIM of AMI is to show physicists the DATASETS which are available for analysis, and to allow SEARCHING on PHYSICS criteria. • There are two other important ATLAS mediator applications for Data Discovery at other granularities. • RunQuery (Runs) • ELSSI/TAG DB (Events) • Granularity Clouds ? (c.f. Grid architecture) S.A.
Overview of Data Discovery in ATLAS "Navigation Parameters" runNumber eventNumber datasetName Dataset AMI Event Run RunQuery ELSSI S.A.
Inside the Dataset cloud AMI on-line DQ2 off-line AKTR Tier0 PANDA PRODDB S.A.
Links from (and to) AMI SVN/NICOS Run Query Run Summary COMA Twiki AMI ELSII Geometry Config DB GANGA Trigger ProdDB Panda pAThena S.A.
Links from Run Query (taken from RQ tutorial) The actual call of AtlRunQuery after parsing Which criterion are applied Total number of runs / events selected and execution time Table with runs selected with showresults (run, links, LB, time, #events always shown) Links to other run information (DS, BS, AMI, DQ, E-log) Summary (where useful) S.A.
TAG DB Structure & Processes COOL COMA RunFillProgs TAG DB Trigger DB Conditions Metadata DB (MC and Prod) Repro Data Loader DQ2 Application and Service Knowledge DB POOL Relational Collections AMI TAG Upload Tier-0 S.A. Slide from Florbela Viegas, SW week July 2010 05/01/2020 33
Some "Blue Sky" Questions • Remove the "ad-hoc" mechanisms for communication? • Generalise Active MQ communication between applications? • Move to an ATLAS wide query grammar for data discovery? • "Ontology" (http://en.wikipedia.org/wiki/Ontology_%28computer_science%29) • A common vocabulary for sharing information about a domain. It includes definitions of the basic concepts in the domain, and the relations among them. Each actor would then implement its own adaptor to translate to and from the common language S.A.
Result User Query AMI METADATA PORTAL Metadata Dictionary Result Aggregation Query Builder ATLAS METADATA ONTOLOGY Translations done by each application Each application implements an adaptor to a common language. The Good Run List is almost a prototype for this! S.A.
? • A very interesting long term project for a real computer scientist, but do we really need it? • Implies a common desire to achieve such an interface. S.A.
AMI RunQuery ELSSI Conclusions. • It is important that each mediator interface is well anchored in its granularity cloud. • It is equally important to keep good coordination between them. • The physicist user is the boss! Make it easy for him/her. S.A.
Extra slides S.A.
ami.in2p3.fr pyAMI AMI Data Puller Tasks triggerDB AMI prodDB AMI Tier0 AMI Key for interface diagrams Key AMI links to AMI reads from AMI writes to S.A.
Granularity S.A.
Container incoherence example • Task 73194, marked "finished" in AKTR 2010-04-22 11:03:54.0 (actually was probably finished on 2009-07-16 09:44:24) • All containers are empty. • data09_cos.00121238.physics_RPCwBeam.recon.TAG_COMM.r733/ • data09_cos.00121238.physics_RPCwBeam.recon.NTUP_MUONCALIB.r733/ • data09_cos.00121238.physics_RPCwBeam.recon.ESD.r733/ • data09_cos.00121238.physics_RPCwBeam.recon.AOD.r733/ • data09_cos.00121238.physics_RPCwBeam.recon.log.r733/ • data09_cos.00121238.physics_RPCwBeam.recon.HIST.r733/ • But the TID datasets exist in DQ2 (i.e. the data is not deleted) • Example : data09_cos.00121238.physics_RPCwBeam.recon.TAG_COMM.r733_tid073194 (3827 files) S.A.