Download
1 / 3
30 likes | 129 Views
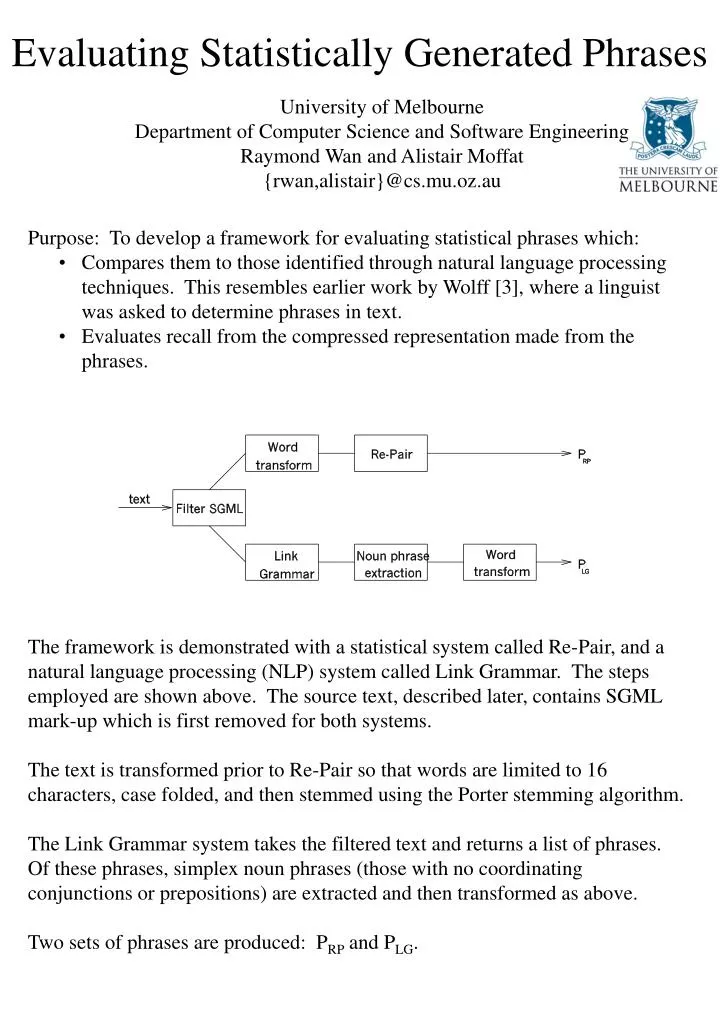
Evaluating Statistically Generated Phrases. University of Melbourne Department of Computer Science and Software Engineering Raymond Wan and Alistair Moffat {rwan,alistair}@cs.mu.oz.au. Purpose: To develop a framework for evaluating statistical phrases which:

E N D
Evaluating Statistically Generated Phrases University of Melbourne Department of Computer Science and Software Engineering Raymond Wan and Alistair Moffat {rwan,alistair}@cs.mu.oz.au • Purpose: To develop a framework for evaluating statistical phrases which: • Compares them to those identified through natural language processing techniques. This resembles earlier work by Wolff [3], where a linguist was asked to determine phrases in text. • Evaluates recall from the compressed representation made from the phrases. The framework is demonstrated with a statistical system called Re-Pair, and a natural language processing (NLP) system called Link Grammar. The steps employed are shown above. The source text, described later, contains SGML mark-up which is first removed for both systems. The text is transformed prior to Re-Pair so that words are limited to 16 characters, case folded, and then stemmed using the Porter stemming algorithm. The Link Grammar system takes the filtered text and returns a list of phrases. Of these phrases, simplex noun phrases (those with no coordinating conjunctions or prepositions) are extracted and then transformed as above. Two sets of phrases are produced: PRP and PLG.
Initially, Link Grammar [2] classifies words in the text according to their part of speech (noun, verb, etc.). Then, words are linked recursively based on a set of rules. For example, a link would be formed between the pair of words “the account” since “the” is a determiner, and “account” is a noun which accepts a determiner to its left. If the sentence is grammatical, then a valid linkage is formed, as shown in the figure above. Constituents (phrases) are then identified. For example, the above sentence would be labelled as: (S (NP South Korea) (VP ’s (NP Current Account))). “NP” and “VP” signify noun phrase and verb phrase, respectively. Re-Pair [1] is an off-line dictionary-based compression algorithm which reduces the length of a message by recursively replacing the most frequently occurring pair of symbols (word tokens, in our case), with a new symbol. A dictionary of phrases (phrase hierarchy) and the sequence of references to the hierarchy are produced. The hierarchical relationship between phrases is illustrated in the graph structure above. Every phrase can be broken into its two components, has siblings where one of the components is identical, and can be extended to phrases which contain the current one. The figure above shows some of the Re-Pair phrases identified in a sample news article. Phrases which have two words are underlined; those that use these phrases directly are highlighted. All of the simplex noun phrases identified with Link Grammar from the same sample text on the left, are underlined above.
Experiments were conducted on a 20 MB subset of Wall Street Journal news articles in SGML mark-up from 1987, which form part of Disk 1 of TREC’s TIPSTER collection. The overlap between PRP and PLG is shown in the upper table, to the right, grouped according to phrase length. As the table shows, just under 30% of the Re-Pair phrases of length 2 were also identified by Link Grammar. This value diminishes with increasing phrase lengths. Recall of the Re-Pair phrases are listed in the lower table. The unweighted recall assumes that every symbol in the phrase hierarchy is equally likely to be a queried. The weighted scheme ensures that a symbol’s recall is proportional to its frequency in the original text. The average recall for both metrics is no less than 0.600. That is, due to Re-Pair’s phrase selection heuristic, some phrases cannot be found. This is because sequences of words that form some phrases in the text are broken up by other, more frequent ones. A framework has been described which evaluates the quality of phrases derived from statistics. Two systems were suggested for the framework. Despite the <30% of phrases which overlap, statistical phrase selection with Re-Pair is still viable due to its speed. For example, Re-Pair requires 18 seconds for this test data, while Link Grammar needed about 100 hours†. A system which compromises between these two methods may provide a better solution. Recall of 1.00 can be achieved if Re-Pair is used to isolate phrases that are then explicitly indexed by an inverted file. † The test machine was a 933 MHz Pentium III with 1 GB RAM and 256 kB on-die cache. [1] N. J. Larsson and A. Moffat. Offline dictionary-based compression. Proc. IEEE, 88(11):1722-1732, November 2000. [2] D. D. K. Sleator and D. Temperley. Parsing English with a Link Grammar. Technical Report CMU-CS-91-196, Carnegie Mellon University, School of Computer Science, October 1991. Software available from http://www.link.cs.cmu.edu/link/; current version is 4.1 . [3] J. G. Wolff. Language acquisition and the discovery of phrase structure. Language and Speech, 23(3):255-269, 1980.