Download
1 / 15
150 likes | 322 Views
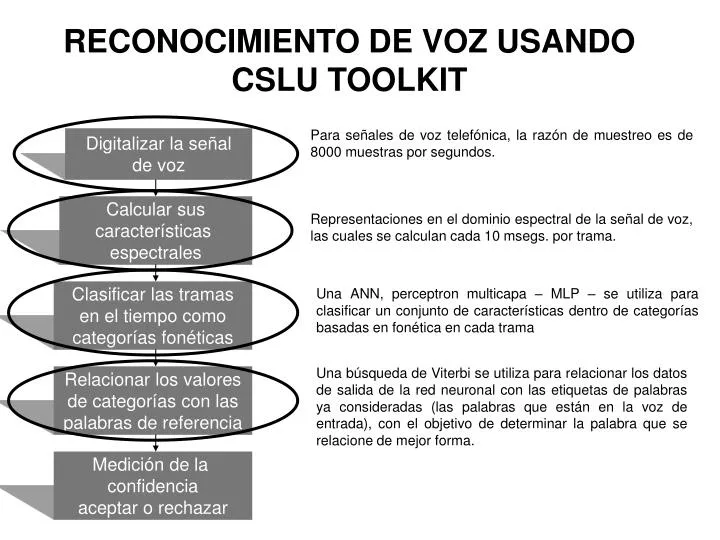
Digitalizar la señal de voz. Calcular sus características espectrales. Clasificar las tramas en el tiempo como categorías fonéticas. Relacionar los valores de categorías con las palabras de referencia. Medición de la confidencia aceptar o rechazar.

E N D
Digitalizar la señal de voz Calcular sus características espectrales Clasificar las tramas en el tiempo como categorías fonéticas Relacionar los valores de categorías con las palabras de referencia Medición de la confidencia aceptar o rechazar RECONOCIMIENTO DE VOZ USANDO CSLU TOOLKIT Para señales de voz telefónica, la razón de muestreo es de 8000 muestras por segundos. Representaciones en el dominio espectral de la señal de voz, las cuales se calculan cada 10 msegs. por trama. Una ANN, perceptron multicapa – MLP – se utiliza para clasificar un conjunto de características dentro de categorías basadas en fonética en cada trama Una búsqueda de Viterbi se utiliza para relacionar los datos de salida de la red neuronal con las etiquetas de palabras ya consideradas (las palabras que están en la voz de entrada), con el objetivo de determinar la palabra que se relacione de mejor forma.
RECONOCIMIENTO DE VOZ USANDO CSLU TOOLKIT Es posible analizar los resultados pero observando el nivel de confidencialidad que se tiene en la palabra adecuada. La palabra puede ser rechazada como no perteneciente al vocabulario si la confidencialidad cae por debajo de un umbral predeterminado. Los valores confidenciales se calcular por la etapa de reconocimiento dentro del CSLU Toolkit. Para un reconocedor de propósito general, se utilizan 12 coeficientes MFCC, 12 características delta MFCC que indican el grado de cambio espectral, una característica de energía y una características de energía delta (en total, 26 parámetros). La resta de la media cepstral (CMS) de los coeficientes MFCC se hace para eliminar algunos de los efectos del ruido. Para un reconocedor de dígitos anterior, su utilizaban 12 características MFCC con CMS, una característica de energía del análisis MFCC, 12 características PLP con reducción de ruido por el procesamiento RASTA, y una característica de energía del análisis PLP (26 parámetros en total).
RECONOCIMIENTO DE VOZ USANDO CSLU TOOLKIT Para obtener información acerca del contenido acústico se toma una ventana de características, como se ilustra en la imagen de la dispositiva anterior, las líneas verticales en el diagrama van de izquierda a derecha. Lo anterior significa tomar la trama de interés así como las tramas que se encuentran a -60, -30, 30 y 60 msegs., de la trama de interés. Esto se realiza tomando en consideración la naturaleza dinámica de la señal de voz. La identidad de un fonema regularmente no sólo depende de las características espectrales en un punto determinado a un cierto tiempo, sino también depende de la forma en la que las características cambian a lo largo del tiempo. Se envían las características en una ventana de contexto a una red neuronal para su clasificación (26 características por trama en 5 frames = 130 características). La salida de la red neuronal es una clasificación de cada trama de entrada, medida en términos de las probabilidades de categorías basadas en fonemas. Pero al enviar las ventanas de contexto para todas las tramas de la voz a la red neuronal, se puede construir una matriz de probabilidades de categorías basadas en fonemas a lo largo del tiempo. Para el ejemplo, la salida de la red neuronal es la palabra “two”, y las regiones más oscuras en la t, t<u y las categorías u indican las más altas probabilidades de aquellas clases en los tiempos indicados. Las pronunciaciones de las palabras de salida se expanden en cadenas de categorías basadas en fonética, y la búsqueda de Viterbi se utiliza para encontrar la mejor trayectoria a lo largo de la matriz de probabilidades para cada cadena legal. La salida del reconocimiento es la cadena de palabras que corresponde a la mejor trayectoria.
MODELADO DEPENDIENTE DE CONTEXTO Una vista rápida de las categorías que debe de clasificar la red neuronal la representan cada fonema, de tal forma que una palabra como día debe de contener tres categorías distintas: /d/ /í/, y /a/. Debido a los problemas de coarticulación que se presentan, la estrategia actual es dividir cada fonema en una, dos o tres partes, dependiendo de la duración típica de cada fonema así como determinado fonema se encuentra influenciado por los fonemas aledaños. En CSLU palabras con estas características, la palabra central se divide en 2 partes, una correspondiente a su interacción con el fonema inicial y la otra correspondiente a la interacción con el fonema final. El método de utilizar contextos amplios ha dado como resultado 576 categorías para todos los fonemas del inglés americano, el cual es más adecuadamente manejable por sistemas de cómputo. Además, las categorías que no se presentan de manera continua pueden ser agrupadas dentro de otras, con lo que las categorías se podrán reducir de 576 a 544. La red neuronal actualmente implementada en el sistema de CSLU tiene 544 categorías de salida, pero los fonemas que pertenecen a un contexto amplio se encontraron utilizando el método de manejo de datos en lugar del conocimiento fonético-acústico.
LA RED NEURONAL La red neuronal tiene 130 nodos de entrada, una por cada característica en el contexto de ventana de 5 frames. Tiene además, 200 nodos en la capa oculta, y 544 nodos en la capa de salida. Las salidas de la red neuronal son utilizadas como estimación de la probabilidad posterior de cada categoría, de tal forma que se puede decir que “OK, en la trama 42 se encontró un 82% de probabilidad de y>$mid, un 7% de probabilidad de y>$front, y un 7% de probabilidad de iy>$mid, un 3% de probabilidad de <iy>, y una probabilidad total de cero para las demás categorías.
BÚSQUEDA DE VITERBI Una vez que se tiene una matriz de la forma en la que las probabilidades fonéticas cambian con el tiempo, se desea encontrar la mejor palabra. Antes de hacerlo, es necesario calcular el conjunto de cadenas legales de las categorías fonéticas. Este conjunto es dependiente de las palabras que se deseen reconocer y el posible orden de palabras, de tal forma que se combinan los modelos de pronunciación por cada una de las palabras (por ejemplo, “yes”=$sil <y,y>$mid,$front<E<E>E>$fric, $mid<s,s>$sil) con una gramática (la cual específica que pueden ocurrir y en que orden). En la búsqueda, cuando se observa una nueva trama, se realiza la transición hacia un nuevo estado si la probabilidad de la nueva categoría es mayor que la probabilidad de la categoría actual. Al final de la búsqueda, se tiene un marcador para la mayor parte de las secuencias y las trayectorias a lo largo de las categorías que se utilizaron para generar la mejor puntuación. Se puede tomar esa palabra y fácilmente determinar la palabra correspondiente (o secuencia de palabras). Esta palabra tiene la mejor relación con respecto a la entrada de datos, y es la palabra que se aproxima más a la que se pronunció.
EJEMPLO DE LA BÚSQUEDA DE VITERBI La figura traza las trayectorias de búsqueda para las palabras “yes” y “no” a través de una matriz hipotética de probabilidades. Si se toma en consideración que el puntaje para la palabra “no” es muy bajo, es posible encontrar la trayectoria más probable para esta palabra, si “yes” no se encuentra en el vocabulario. La búsqueda de Viterbi puede entenderse pero leyendo por medio del algoritmo puesto en pseudo-código de la siguiente diapositiva.
EJEMPLO DE LA BÚSQUEDA DE VITERBI /* initialization */ given N is the number of categories, given T is the number of frames, given matrix B[j][t]: category probabilities (neural network outputs), with 1 <= j <= N, 1 <= t <= T given matrix A[i][j]: probability of transitioning from category i to category j, with 1 <= i <= N, 1 <= j <= N initialize delta[i][1] to B[i][1], with 1 <= i <= N initialize psi[i][1] to 0, with 1 <= i <= N /* main loop: compute delta (scores) and psi (category values corresponding */ /* to best scores). max_score is probability of being in state i and */ /* transitioning from state i to state j */ for each frame t from 2 to T { for each category j from 1 to N { max_score = LOWEST_POSSIBLE_VALUE max_index = 0 for each category i from 1 to N { if (delta[i][t-1] * A[i][j] > max_score) { max_score = delta[i][t-1] * A[i][j] max_index = i } } delta[j][t] = max_score * B[j][t] psi[j][t] = max_index } } /* backtracking to find state (category) sequence */ max_score = LOWEST_POSSIBLE_VALUE max_index = 0 for each category i from 1 to N { if (delta[i][T] > max_score) { max_score = delta[i][T] max_index = i } } state[T] = max_index for each frame t from T-1 to 1 { state[t] = psi[state[t+1]][t+1] }
LAS FORMAS DE ONDA Los sonidos de la voz son creados por la actividad vibratoria en el tracto vocal de los seres humanos. La voz normalmente se transmite a los oídos del escucha o a un micrófono por medio del aire, en donde la voz y otros sonidos toman la forma de ondas radiantes de variación en presión de aire alrededor de un valor estimado promedio en un nivel de aproximadamente 100000 Pascals. La siguiente figura es una representación visual de las vibraciones típicas encontradas en el ser humano – esto es, una señal de voz -. Descansando sobre la presión atmosférica que se encuentra representada por la línea horizontal en el centro de la imagen. Una forma de onda muestra el exceso de presión como una función del tiempo para otorgar un punto en el espacio. En una forma de onda, debajo de cero significa que la presión es mayor 100000 Pascals. Los oídos humanos son sensibles a variaciones tan pequeñas como 0.00002 Pa. Cuando se habla ante un micrófono la forma de onda que se obtiene es continua con el tiempo, por lo que debe de ser discretizada o muestreada. La frecuencia de muestreo comunmente utilizada es de 16 KHz La voz telefónica se encuentra muestreada a una razón de 8 KHz. Mientras que las grabaciones de CD lo están a 44.1 KHz, lo que lo hace tener una alta razón de muestreo, una mejor calidad de sonido, pero se requieren de mayor cantidad de bits para trabajar.
Este artículo presenta dos herramientas desarrolladas con tecnología de voz para la enseñanza del Español hablado en México. Estas son un diccionario Inglés-Español accesado por medio de la voz, y un nuevo método para la verificación de la pronunciación correcta de palabras o frases. Esta segunda herramienta es especialmente útil en los sistemas para la enseñanza de un lenguaje por medio de la computadora (CALL - Computer Aided Language Learning). Este método aprovecha las técnicas de reconocimiento de voz y las herramientas del CSLU Toolkit (del Center for Spoken Language Understanding, Oregon Graduate Institute) para reconocer la secuencia de sonidos emitidos por el usuario y marcar las partes mal pronunciadas. Cada frase o palabra pronunciada por el usuario puede evaluarse fonema por fonema detectando los errores en que incurrió el locutor. Para ello es necesario entrenar un sistema de reconocimiento de voz (una red neuronal en este caso) con los fonemas del lenguaje objetivo además de incluir los fonemas del idioma nativo del locutor. Esto se debe a que los errores de pronunciación de alguien que esta aprendiendo un nuevo idioma son causados por las costumbres de pronunciación del locutor en su lengua materna. A diferencia de otros sistemas existentes, con este método se puede proveer una retroalimentación explícita y clara al usuario, el cual podrá entonces estudiar e intentar pronunciar las frases que contengan esas partículas que requiere practicar.
Entre las aplicaciones que más sentido tienen en la aplicación de interfaces de voz son los sistemas para la enseñanza de lenguajes. Este artículo presenta un método que utiliza un sistema de reconocimiento de voz para analizar explícitamente la pronunciación correcta de palabras o frases. Asimismo se introduce una interfaz de voz para acceder a un diccionario bilingüe. La instrucción asistida por computadora (CAI) se refiere al area de estudio sobre la forma a través de la cual una computadora asiste a un usuario en el proceso de aprendizaje. CAI da a lugar al modo de enseñanza y aprendizaje por descubrimiento, en dónde el estudiante esta involucrado en una exploración intelectual del conocimiento de una manera mucho más libre y autodirigida. Es entonces una herramienta a través de la cual el aprendizaje puede ocurrir. En los últimos años más y más sistemas CAI han incorporado herramientas multimodales, interfaces que manejan audio, imágenes video, y programas interactivos que invocan a diversas aplicaciones. Recientemente, la intergación de interfaces de voz a los sistemas CALL o ICALL (Intelligent CALL) ha creado un mundo nuevo de posibilidades para el desarrollo de herramientas para la enseñanza [2].
En otro campo de aplicación, el Center for Spoken Language Understanding (CSLU) del Oregon Graduate Institute y de la Universidad de Colorado han estado colaborando con la Tucker Maxon Oral School [5], en un esfuerzo conjunto para enfocado al entrenamiento del lenguaje para niños hipoacúsicos (desde sordera ligera hasta sordera profunda). Ellos elaboraron un conjunto de herramientas que incorporan reconocimiento de voz y producción de voz, así como un agente conversacional animado, llamado Baldi [6; 7; 8]. Este agente esta representado por una cara animada en 3D que produce habla visual, es decir, produce expresiones faciales sincronizadas con el sintetizador [9]. Las expresiones faciales incluyen movimiento de labios, quijada, cejas, ojos y lengua, haciendo posible que un niño pueda leer los labios de Baldi y entender lo que esta diciendo. Baldi es también capaz de mostrar emociones de tristeza, alegría, molestia, etc. Los niños juegan con la interfaz de voz, en dónde se pueden diseñar las más variadas lecciones con imágenes, video, sonido y voz, reconocimiento y producción (véase la figura).
Sin embargo, cuando se crea un reconocedor para un idioma en particular, este rechazará cualquier fonema que no pertenezca al idioma o tratará de buscar dentro de sus fonemas el que más se le parezca. La gramática es, por otro lado, una que permite cualquier secuencia de fonemas. Pero si se deja que el reconocedor trate de reconocer todos los sonidos que lleguen al micrófono se generarían demasiados errores de inserción por ruido ambiental, etc. Para evitar este problema se utilizó una inspirada en el proceso para el etiquetado automático de voz, llamado forced alignment [11; 12; 13]. Esta técnica utiliza el grafo de pronunciaciones de una sola palabra o frase (la que se pretende reconocer) y utilizando el reconocedor busca mapear cada sonido con alguna de las posibles secuencias de fonemas para esa palabra o frase específica. Por ejemplo, si la palabra a reconocer es "abeja" las posibles pronunciaciones se generan a partir de las pronunciaciones por cada letra (tabla 1): ABEJA = {{ a | ay | e | ey | uh }{ bc b | B }{ e | ey | i }{ x | h }{ a | ay | e | ey | uh }}; Con esto se crea un grafo de pronunciaciones y la red neuronal Tradicionalmente en los sistemas de reconocimiento de voz se encuentran errores de inserción, eliminación o sustitución. El error de inserción es cuando el usuario dice más de los que debía decir. El error de eliminación ocurre cuando el usuario omite alguna letra. Estos dos errores no puedes ocurrir en nuestro caso ya que seforza la pronunciación a un conjunto limitado de fonemas. El error de sustitución por otro lado es el que se encuentra en estos casos.
Clasificación de los fonemas: • Para consistencia en el análisis y facilitan la comunicación entre investigadores se han definido diferentes sistemas notacionales para clasificar los sonidos del habla de todas las lenguas del mundo. • Sistemas notacionales: • ARPABET (1970's) • WORLDBET • IPA
Diptongos: • /ei/ • /oi/ • /ai/ • Nasal: • labial : M • Velar : N • Alveolar • nj / n • Vibrantes: • r / rr • Africativo: • ch • Semivocales: • /w/ /j/ (siempre con una vocal) • Cuatro = kc k w a tc t r o Cuento = kc k w e n tc t o • /l/ forma lateral • Fricativos : • labial /f/ • alveolar /s/ • velar /x/ • Oclusivos: • Sonoro: /b/ /d/ /g/ • Sordo: /p/ /t/ /k/ • En resúmen, la ARTICULACION provee información valiosa sobre la forma de producción de la voz.






















