Download
1 / 36
360 likes | 617 Views
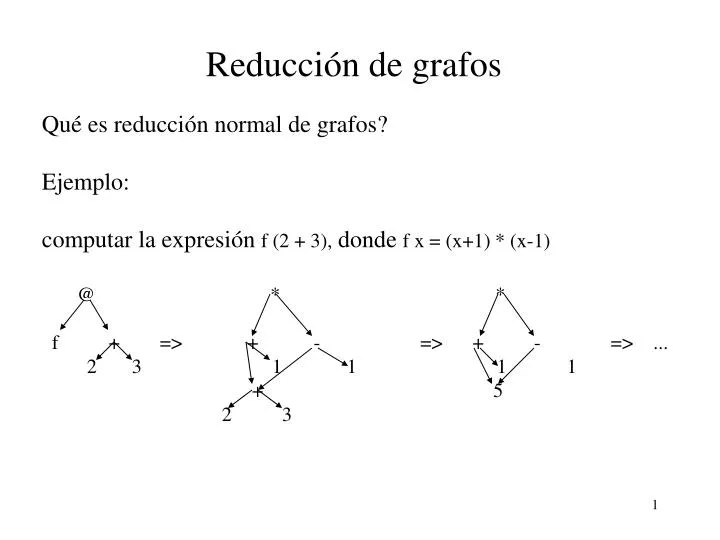
Reducci ó n de grafos. Qué es reducción normal de grafos ? Ejemplo: computar la expresi ó n f (2 + 3), donde f x = (x+1) * (x-1) @ * *

E N D
Reducción de grafos Qué es reducción normal de grafos? Ejemplo: computar la expresión f (2 + 3), donde f x = (x+1) * (x-1) @ * * f + => + - => + - => ... 2 3 1 1 1 1 + 5 2 3
Reducción de grafos • Arboles sintácticos y grafos • aplicación @ • abstracción \ x Ejemplo: \ x -> + 7 x \ x @ @ x + 7
Evaluación perezosa La evaluación perezosa de expresiones funcionales comprende los dos siguientes puntos básicos: i) El argumento de una función es evaluado solamente cuando el mismo es necesario (no cuando la función es aplicada). Esto se conoce como orden normal de reducción. ii) ... y es evaluado a lo sumo una vez. Esto selogra representar en general actualizando el grafo de reducción: @ 5 ____ =>
Constructores y E/S Supongamos que el valor de un programa funcional es una lista (posiblemente infinita). Lo que quisiéramos es que la lista sea impresa a la vez que se va generando la misma: Print(E) { E’ := Evaluate (E); if (IsNumber (E’)) then Output (E’) else { Print(Head(E’)); Print(Tail(E’)) } } Evaluamos a forma cons Evaluamos la cabeza Imprimimos el valor de la head y continuamos con la tail 5
Entrada Queremos que se efectúe lectura de datos solamente cuando éstos son necesarios: Input : ´a´ Input
Formas normales Las consideraciones previas acerca del tratamiento que queremos hacer de E/S nos lleva a la siguiente conclusión: la evaluación de una expresión cuyo resultado es una celdaCons no debe forzar la evaluación de lahead ytail de la misma. Esto significa que la reducción de una expresión debe parar aún cuando quedan redexes en el grafo. Ninguno de estos redexes será reducido, si se usa orden normal de reducción, hasta que toda la expresión haya sido evaluada a una celda Cons, porque hasta ese momento siempre habrá un top-level redex que el orden normal elegirá para reducir. Entonces, lo que necesitamos es efectuar orden normal de reducción, pero parar cuando no se encuentra un top-level redex.
Weak Head Normal Form Definimos inductivamente el predicado whnf sobre expresiones como sigue: ---------------- a es variable o constructor whnf a ------------------- whnf (\ x -> e) whnf f y f no es una abstracción ------------------------------------------ whnf (f e) p es un operador primitivo aridad de p = n, y n m --------------------------------- whnf (p e1 e2 ... em)
Weak Head Normal Form (2) Ejemplos: 3, Cons (id 5) ((\ x y -> x) f), + (- 4 3), \ x -> + 5 1 Definimos inductivamente la relación de ser un top-level redex(TLR) de una expresión como sigue ------------------------------------------------- ((\ x -> e) e1) TLR ((\ x -> e) e1 e2 ... en) si p es una operación primitiva aridad de p = m y m n ----------------------------------------- (f e1 e2 ... em) TLR (f e1 e2 ... en) Orden normal de reducción es equivalente a siempre evaluar el top-level redex de una expresión primero.
Supercombinadores Def. Un supercombinador S de aridad n es una abstracción de la forma \ x1 x2 ... xn -> e, donde: i) e no es una abstracción ii) S no tiene variables libres iii) las abstracciones que ocurren en e son supercombinadores iv) n 0 Ejemplos 3 , (+ 2 5) , \ x -> + x 1, \ f -> f (\ x -> + x x) Contraejemplos \ x -> y, \ y -> - y x, \ f -> f (\ x -> f x 2)
Supercombinadores (2) Definimos inductivamente el predicado whnf sobre supercombinadores como sigue: ---------------- a es un constructor whnf a ------------------- whnf (\ x -> e) whnf f y f no es una abstracción ------------------------------------------ whnf (f e) p es un operador primitivo aridad de p = n, y n m --------------------------------- whnf (p e1 e2 ... em) No variables libres en un supercombinador.
Cómo encontrar el siguiente top-level redex Supongamos que queremos efectuar un paso de reducción sobre la siguiente expresión: @ @ @ @ @ e2 fe1 Entonces para efectuar la computación (evaluar el redex) podemos razonar haciendo un análisis casos en la forma de f y su aridad.
Cómo encontrar el siguiente top-level redex (2) • La expresión f puede ser: • i) un constructor (número, celda Cons, etc.), y n entonces es igual a la aridad del mismo. La expresión ya está en whnf. • ii) un operador primitivo, de aridad k: • si n k entonces la expresión está en whnf • si n k entonces podemos reducir utilizando la correspondiente regla de evaluación (posiblemente después de haber recursivamente evaluado alguno de los ei) • iii) una abstracción: • si n 1entonces deberíamos reducir el redex (f e1) • si no la expresión está en whnf.
Usando un “spine stack” @ $ @ e4 @ e3 @ e2 if e1 * * * * * • if es la punta de la espina (tope del stack) • $ indica la raíz del redex • la vértebra son los nodos de aplicación encontrados en la recorrida hacia “abajo” (unwinding) de la espina • el nro. de argumentos está dado por la profundidad del stack
Usando un “spine stack” (2) El mismo stack puede ser usado para evaluar subexpresiones: * * * * * * *
Reducción de expresiones Hemos visto como buscar el redex a evaluar en cada paso de la reducción. Ahora veremos cómo efectuar una reducción. Esto se traduce en una transformación local al gtrafo que representa la expresión. Por lo tanto, el proceso de reducción sucesivamente modifica el grafo hasta que se llega al valor final. Vimos además que la punta de la vértebra puede ser una abstracción o un operador primitivo (en el caso de que el grafo tenga un top-level redex). A continuación veremos separadamente como tratar estos casos.
Reducción de expresiones l Supongamos entonces que el redex consiste de una abstracción aplicada a un cierto argumento. Entonces debemos aplicar la regla de b-reducción al grafo. Es decir, debemos construír una instancia del cuerpo de la abstracción, sustituyendo las ocurrencias libres de la variable ligada por el argumento. A continuación nos referiremos a este paso como a “instanciar el cuerpo de la abstracción”. @ @ \ x @ @ @ Not True => And @ @ x Not True And x
Reducción de expresiones l (2) Tres importantes aspectos de implementación surgen al considerar la reducción de este tipo de expresiones: i) El argumento del redex puede a su vez contener redexes, por lo tanto deberíamos sustituir el parámetro formal por punteros al argumento. ii) El redex puede ser compartido, entonces debemos reescribir físicamente la raíz del redex con el resultado de la evaluación iii) La abstracción podría ser compartida, por lo tanto debemos construír una nueva instancia del cuerpo de la abstracción, en vez de directamente sustituir en el cuerpo original.
Sustituyendo punteros al argumento Cuando sustituímos el parámetro formal por el argumento podríamos simplemente copiar el argumento donde sea que encontremos una ocurrencia del parámetro. Pero copiar el argumento podría ser realmente ineficiente, porque i) el argumento puede ser una expresión muy grande, y en dicho caso estamos gastando mucho espacio en este proceso ii) el argumento podría contener redexes, en este caso estamos duplicando redexes que luego tendrán que ser reducidos por separado. Estos problemas se pueden evitar sustituyendo el parámetro formal por punteros al argumento. Este proceso genera “sharing” de expresiones.
Reescritura de la raíz del redex Para explotar sharing debemos asegurar que cuando una expresión es reducida el grafo queda modificado. Esto implementa el hecho de que expresiones compartidas son efectivamente reducidas a lo sumo una vez. Para lograr este efecto lo que hacemos es simplemete reescribir la raíz del redex con la raíz de la expresión obtenida en el paso de reducción. Ejemplo: (And (Not True) ... Notar que hay fragmentos del redex que no son afectados por la reescritura y quedan completamente separados del grafo que estamos considerando. Eventualmente (si no son a su vez compartidos) serán reclamados por el garbage.
Construyendo una nueva instancia del cuerpo de la abstracción Cuando aplicamos una abstracción debemos efectuar la sustitución en una nueva copia del cuerpo de la misma en vez de directamente actualizar el cuerpo original. Esto es necesario porque la abstracción puede llegar a ser aplicada muchas veces, y su cuerpo sirve de “template” a partir del cual una instancia es creada cada vez que la abstracción es aplicada. Este template no debería ser afectado por el proceso de copia. Ejemplo: (\ x -> Not x) True La abstracción original se mantiene incambiada. (Notar $)
La función instantiate Describiremos la opración de instanciación por medio de una función recursiva (instantiate body var value), la que copia body sustituyendo las ocurrencias libres de var por value. Esta función implementa la operación de sustitución descripta previamente en el curso. instantiate body var value = case body of Var x -> if x == var then value else body App f e -> App (instantiate f var value) (instantiate e var value) Lam bvs@(x:xs) e -> if x == var then body else Lam bvs (instantiate e var value)
Evaluación perezosa Hemos visto que evaluación perezosa tiene dos ingredeientes principales: i) Argumentos de funciones deben ser evaluados sólo cuando son necesarios ii) una vez evaluados, no deberían ser evaluados más. Orden normal implementa el primer ingrediente. El segundo es implementado por la combinación de los siguientes puntos: i) sustituir punteros al argumento evita duplicar reducciones ii) actualizar la raíz del redex asegura que futuros usos del argumento no tendrñan que efectuar el trabajo de avaluación nuevamente
Reduciendo operadores primitivos Supongamos que el redex consiste de un operador primitivo aplicado al número correcto de argumentos. Entonces: i) los valores de los argumentos deben ser calculados, invocando recursivamente al evaluador. ii) el operador es ejecutado iii) reescribimos físicamente la raíz del redex Ejemplo: @ $ => @ $ => 18 $ @ @ @ 12 # @ 12 # + 6 @ 4 + 6 @ 4 + 6 @ 4 * 3 * 3 * 3
Representación concreta del grafo En una implementación cada nodo del árbol será representado en una pequeña area contigua de almacenamiento, llamada una celda. Una celda consiste de un tag, que dice qué tipo de nodo es y dos o más campos. Típicamente: Tag Campo 1 Campo 2 Un campo puede contener la dirección de otra celda, en ese caso diremos que es un puntero que apunta a una celda. Alternativamente un campo puede contener un valor atómico (no-puntero).
Posibles representaciones concretas Tipo de nodo Nodo abstracto Celda concreta Aplicación Lambda celda CONS Número Operador primitivo @ f e \ x cuerpo : x xs 34 + @ \ x : N 34 P +
Boxing y Unboxing Que un número ocupe una celda cuando con un campo se podría representar ese mismo número parece ser un gasto de espacio. (Ejemplo (+ 3 4)). En vez de tener punteros a celdas que contienen números parecería mejor poner directamente el número en el campo. Objetos que pueden ser completamente descriptos por un solo campo son llamados unboxed, mientras que aquellos que requieren una o más celdas se les llamará boxed. Candidatos típicos para representaciones unboxed son enteros, booleanos, caracteres y operadores primitivos (los que en adición pueden ser identificados usando un entero pequeño). En un sistema boxed el tag de la celda determina el tipo de los campos. No así en un unboxed, cada campo puede contener un puntero o un valor unboxed.
Boxing y Unboxing (2) números unboxed @ 3 bit de puntero @ + 5 1 Dirección @ 0 Valor N 3 Unboxing salva espacio, pero dificulta type-checking en tiempo de ejecución. (reservar parte del campo para identificar al valor). Requiere extra esfuerzo chequear los bits de punteros.
Nodos de indirección El procedimiento descripto para reducir la aplicación de una abstracción, en particular la actualización de la raíz del redex con el valor obtenido de la instanciación, presenta ciertos problemas. Supongamos que hemos instanciado el cuerpo y procedemos a actualizar la raíz, lo más obvio parece ser simplemente copiar la celda raíz del resultado sobre la celda raíz del redex. Este procedimiento, sin embargo, tiene los siguientes defectos: i) El resultado de la reducción podría no tener una celda raíz a ser copiada (implementación unboxed de valores) . Ej: (\ x -> 4) 5 ii) Es ineficiente, la celda raíz es construída, copiada y luego descartada (no más referencias a ella).
Nodos de indirección (2) Sería más eficiente construír la celda raíz directamente sobre la raíz del redex, evitando así construir una celda que luego será descartada. Sin embargo, en una reducción como (\ x -> x) (f 6) la celda raíz del resultado no es una celda nueva, por lo tanto no podemos construír la celda raíz del resultado sobre la del redex. Abstracciones cuyos cuerpos consisten de una constante unboxed o una sola variable forman un caso especial. A continuación analizaremos estos casos separadamente.
Actualización con objetos unboxed Cómo podemos actualizar la raíz de un redex con un objeto no-puntero ? Introducimos un nuevo tipo de celda, llamada de indirección. Una celda de indirección tiene un tag, IND digamos, que identifica la celda como una indirección y un campo que es el contenido de la celda. Cuando actualizamos una celda de aplicación con objeto unboxed, lo que hacemos es sobreescribir la plicación con una celda de indirección cuyo contenido es un objeto unboxed. @ \ x 6 => 4 4
Actualización cuando el cuerpo es una variable Consideremos el ejemplo visto @ $ \ x @ x f 6 Hay dos formas posibles de actualizar la raíz del redex: i) podríamos copiar la celda raíz del resultado sobre la celda raíz del redex @ $ @ $ \ x @ # => @ # x f 6 f 6
Actualización cuando el cuerpo es una variable (2) El resultado es correcto, sin embargo la aplicación de f a 6 ahora ha sido duplicada, (f 6) puede llegar a ser evaluada dos veces si # es compartido. Notar que este problema puede surgir sólo cuando el cuerpo de una abstracción es una variable. Si fuera una aplicación, la raíz del resultado será una celda de aplicación nueva y por lo tanto no podría ser compartida. Aún cuando (f 6) ya estuviera en forma normal el nodo $ es un duplicado de #, y por lo tanto es un gasto innecesario de memoria. ii) Podríamos usar un nodo de indirección y entonces reescribir el nodo $ con un nodo de indirección a #. Entonces:
Actualización cuando el cuerpo es una variable (2) @ $ $ \ x @ # => @ # x f 6 f 6 El problema con introducir nodos de indirección es que éstos pueden aparecer en cualquier punto del grafo, y por lo tanto la máquina de reducción debe testear por este tipo de nodos. También está el riesgo de construír largas cadenas de indirecciones. El problema de copia o indireccionamiento surge para todas las operaciones (funciones de proyección) que seleccionan algunos componentes de sus argumentos (head, if, etc.)
Evaluando el resultado antes de actualizar Una solución a los problemas presentados por estos métodos es la de evaluar el resultado antes de actualizar la raíz del redex. Esto puede justificarse como sigue: i) Estamos intentando reducir nodo $ a WHNF. Por lo tanto lo primero que haremos una vez que la reducción es completada es tratar de reducir el resultado, es decir (f 6) a WHNF. Por lo tanto podemos reducir # a WHNF antes de actualizar $ con el resultado de la aplicación. (nunca más de un nodo de indirección en cadena) ii) Una vez que una expresión está en WHNF su raíz nunca será sobreescrita, ya que nunca más será seleccionada como la raíz de un redex. (es seguro copiar un nodo una vez que está en WHNF)
Resumen: indirección vs. copia i) Cuando la raíz del resultado es construída durante la reducción, y es lo suficientemente pequeña, debería ser construída directamente sobre la raíz del redex. ii) Si la raíz del resultado no fue construída durante la reducción entonces podemos sobreescribir la raíz del redex ya sea con una copia de la raíz del resultado o con una indirección al resultado. iii) Los casos cubiertos por ii) cubren a) funciones (abstracciones o primitivas) que retornan valores unboxed. b) abstracciones cuyos cuerpos consisten de una sola variable c) funciones primitivas de proyección iv) En estos últimos casos el resultado debería ser evaluado a WHNF antes de sobreescribir la raíz del redex.
Argumentos a favor del uso de indirección i) No hay alternativa si el resultado es un valor unboxed ii) Nodos de indirección pueden ser fácilmente recuperados por un garbage, sin embargo éste no puede recuperar el espacio duplicado generado por la técnica de copiado. iii) Cadenas de nodos de indirección pueden ser evitadas iv) Serviría naturalmente en la implementación de memo functions. Desventaja: La máquina de reducción tiene que testear permanentemente la presencia de este tipo de nodos, y dereferenciarlos. Enlentece la implementación.






















