Download
1 / 29
290 likes | 301 Views
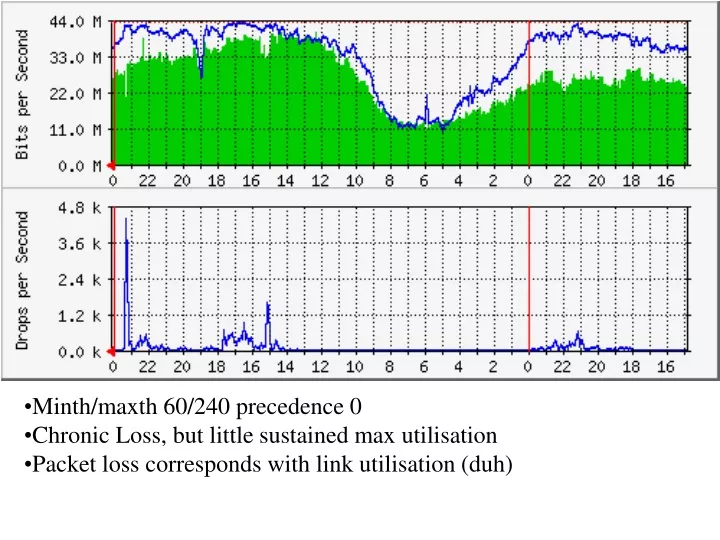
Minth/maxth 60/240 precedence 0 Chronic Loss, but little sustained max utilisation Packet loss corresponds with link utilisation (duh). 100% utilisation from 1500 to 2200 Sustained packet loss with maxth of 240 of ~100pps Large loss seems to come over short intervals.

E N D
Minth/maxth 60/240 precedence 0 • Chronic Loss, but little sustained max utilisation • Packet loss corresponds with link utilisation (duh)
100% utilisation from 1500 to 2200 • Sustained packet loss with maxth of 240 of ~100pps • Large loss seems to come over short intervals. • Before playing with maxth, test drop tail to see if different.
Turned off RED @ 1000 • Drop tail until ~ 1700 (dorian complaining :) • Notice chronic drop levels compared to RED turned on • Period from 1500-1700 averages above 740pps drop
Adjusted minth/maxth to 60/500 to account for avg drops ~100pps • Drops in one timesample, isolated to random burst of data traffic • No chronic drops • Weekend-> lower traffic levels
RED seems to be working better • Times like 2030 demonstrate 100% util with near-zero drops • Large drops seemed to be isolated spikes. Trend is ~ 30pps • maxth just changes tip of the iceberg?
981214 AvgQlen • Sampled @ 1 min intrvl • Large Variance • Corresponds to end of day • on 981214 traffic
Hovering around 100% link util • Peaks at 1700 and 2300 • nominal drops during the day • no more tickets in my inbox regarding congestion
Large average queue length clustered around large drop times • Mean non-zero queue length was 35 packets • Still large variance between adjacent points
Util hovers around 100% 1500-1800 • No sustained drops during this period
Sizable average queue lengths while exhibiting no packet loss.
WFQ/RED turned off at 1400 • Sustained packet loss without full link utilization • Less connection multiplexing across this link. • University link (typical student habits == bulk data xfer)
Link peaks multiple times at 1440kbps • Interesting that discards follow link utilization even at utilization • levels well below full. Discards seem directly related to • utilization. • 0/0/0:21
Exhibiting same trends as :21 graph • Note how drop pattern is nearly exactly the same as traffic pattern • at all of these link levels. Trough @ 1350, peak @ 0915 • 0/0/0:4
Exhibiting same tendencies around 1440 • Again odd drop correspondence. • Three interfaces, all drop tail, all max out at 1440, all have • discards which seem related to traffic levels. (0/0/0:27)
RED turned on 0/0/0:21 • Full link utilisation around midday • No drops save a random large drop sample • Try taking RED off real time to see router reaction.
RED turned off at 2100 • RED turned on at 0000 • Without RED we see chronic loss, but cannot discern whether line • utilisation has dropped off
Drops per second taken on when viewing discards over 5 • second intervals instead of MRTG 5 minute intervals. • Illustrates removal of RED configuration. Further, drops • were chronic across time samples.
Latency on this link (one minute samples) when RED • configuration was removed • Higher latency/lower packet loss during periods of RED • configuration.
RED configuration removed at 2130 • RED applied at 2330 • minth/maxth adjusted to 20 40 instead of 43 87 • to see if we could get drops during RED config.
See higher latency as traffic levels increase • RED taken out at point 1160. Still see latency • levels increase while drops are increasing. • Good case for RED?
Drops graph illustrating both times when RED was • removed from configuration (5 sec samples) • Time in between is RED configuration.
Conclusions • See full rate on DS3 with RED and Drop Tail. Drop Tail results • in higher sustained drops. No discernable global synchronization, • but this could be the result of large percentage over-booking on the • interface. ( when some set of configurations go into congestion • avoidance at the same time, there are always new or previously ramped • up connections that are waiting to fill the queue). • Proper RED configuration (cognizant of added latency) affords • discards for uncharacteristic bursts but totally absorbs some level • of observed average discards. • Importance is in choosing minth/maxth. I started at 60/240 • for the DS3 and moved it up to 60/500 when I found that there • was an appreciable level of discards per second with the first • configuration.
DS1s were not as over-booked as DS3. Also, each ds1 • multiplexes less connections. Dropping packets from one or • a handful of bulk transfers cuts back on • each snd_cwnd (each snd_cwnd is a large part of data • being sent over the connection. • Drop Tail ds1s do not achieve full link utilization at any • juncture. They seem to hover around 1440 kbps while • exhibiting chronic drops. • The only way found to achieve full link utilization on the • examined ds1s was to enable RED. RED settings of 43/87 • and 20/40 both yielded full utilization with no chronic • drops
There seems to be some direct relationship between utilization • and discards on the drop tail ds1s. • Choose minth/maxth based on examining the interface • traffic levels. Perhaps start out at a default setting and then • examine whether drops are from RED or from exceeding • maxth and adjust maxth accordingly. Some implementations • make minth default 1/2 maxth. Depending on operator preference, • this may not be desirable. In my situation, I wanted to slow • down a large portion of the traffic passing through the interface. • Setting the minth low (60) when an interface was experiencing • average queue lengths of 250 or more allowed RED to slow • down traffic in the 60-250 window. If defaults were used, minth • would have been set to 250 and you force average queue to grow • to at least 250 before the RED algorithm takes over. Consistently • forcing that queue size during congestion will lead to higher • latency added by that interface.
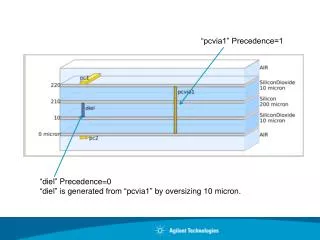
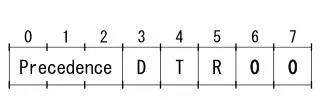
Evaluation • No increase in latency+significantly less packet loss+ • full link utilization = = good? • I used cisco implementation. Technically WRED • because of 8 priority levels, but data shows that on • the network you get 3 orders of magnitude more data • in priority 0 than any other. Thus, behaves like RED. • Precedence 0: 60 min threshold, 500 max threshold • 322498270 packets output, drops: 101196 random, 0 threshold • Precedence 1: 180 min threshold, 500 max threshold • 273549 packets output, drops: 9 random, 0 threshold • the rest of the precedence levels were like precedence 1.
Do not rely on the vendor to do configuration work. RED • is not a configure and forget option. Congestion levels • on your network could change over time. A configuration • useful in a large loss scenario would not be apt for a link • that flirts with congestion. Also, some vendor defaults • for interfaces are ludicrous (the ds3 which exhibited 1460 • drops per second was default configured for minth maxth • of 27 54 respectively). • So does this benefit the customer and will anyone care? • Well, you shouldn’t have oversold your network resources. • None of my customers noticed the changes in configuration • on their interfaces. However, customers did notice changes • at our core (namely dorian stopped complaining). RED • slowed their connections, but they tend to react in a harsh • fashion to packet loss. They didn’t react harshly (or notice) • an extra minute on their Netscape download.
RED/WRED Futures: • Using WRED effectively. There needs to be some knob which • allows the user to set precedence level on web, http, ftp, telnet • etc in a custom fashion so that when data encounters congestion, • traffic is selected against with an eye on elasticity. • As RED gets implemented effectively across cores, congestion • will not disappear (damn those sales people selling service • we haven’t built out yet) but packet loss will be shifted • away from the interactive (hit the reload button 500 times) • sessions and towards bulk xfer (which people minimize in the • background while they attend to interactive sessions). • Even if you always have 0 length queues, the adjacent • ASN may be 40% over capacity and grasping for breath. It is currently • the best way to statelessly combat congestion in the network. I would • hope the network operators configure it @ core and towards CPE.
Futures: Dealing with ‘fast tcp products’ which are more • aggressive than 2001 allows. Perhaps tweaking TCP congestion • avoidance to behave in a sane fashion when there is a ‘static’ • path but appreciable drops (like the ds1s in our example). Study • indicates bulk transfers across single congested gateways • (not as severely congested as the ds3) exhibit sawtooth graph • and keep ramping quickly back up into packet loss. Perhaps • should be more conservative. • Goal in all of this is to fully utilize finite resources without • loss. Mechanisms such as ECN, RED, and modifications • to areas of TCP could all help in achieving this goal. RED certainly • is an improvement over drop tail ‘queue management’ but • equating it with panacea is myopic. It needs to be coupled with • improvements in e2e traffic management to get operators closer • to that goal.
Acknowledgments • MRTG, gnuplot team, • Sally Floyd for comments/review • Susan R. Harris for much needed editing • all rotsb • Available htmlized at: • http://null2.qual.net/reddraft.html