Download

1 / 51
510 likes | 733 Views
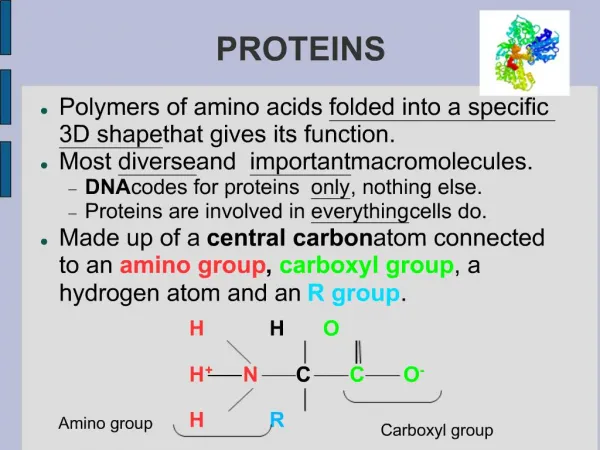
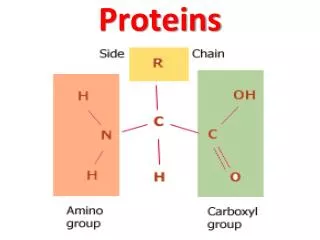
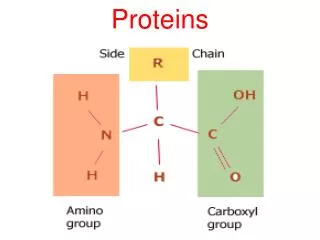
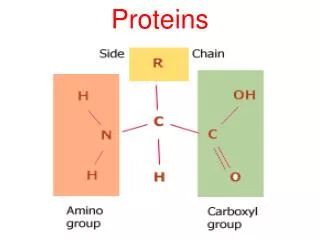
PROTEINS. AMINO ACID Amino acids are the basic structural unit of all proteins. A 'free' amino acid always has: an amino group - NH 2 , a carboxyl group - COOH a hydrogen - H a chemical group or side chain -" R ". These are all joined to a central carbon atom, the a -carbon.

E N D
AMINO ACID Amino acids are the basic structural unit of all proteins. A 'free' amino acid always has: an amino group -NH2, a carboxyl group -COOH a hydrogen -H a chemical group or side chain -"R". These are all joined to a central carbon atom, the a -carbon
Since the amino acids (except glycine) have 4 different groups attached to the a-carbon, they are optically active stereoisomers although only L-isomers are found in proteins.
Types of Amino Acid "R" represents "a chemical group" and gives each amino acid its distinctive properties. With amino acids, this chemical group is called the "sidechain", and it specifies the amino acid. There are only 20 different amino acids found in proteins, each with it's own defining sidechain. These sidechains have a widespread range of chemical (e.g.charge etc) and structural (e.g. shape etc) diversity. Here we can view the amino acids as they are commonly grouped.
ALIPHATIC AMINO ACIDS Aliphatic amino acids are hydrophobic. They do not like to be in contact with water molecules in an aqueous solution. For this reason, they are often located in the core of the protein, surrounded by the rest of the protein, and "shielded" by them from the aqueous surroundings. Glycine (Gly; G) Alanine (Ala; A)Valine (Val; V)Leucine (Leu; L) Isoleucine (Ile; I)Proline (Pro; P)
AROMATIC AMINO ACIDS These are the amino acids which contain an aromatic ring as part of their sidechains. Because of the hydrophobic nature of aromatic rings these amino acids are highly hydrophobic. Phenylalanine (Phe; F)Tyrosine (Tyr; Y). Tryptophan (Trp; W)
SULPHUR CONTAINING AMINO ACIDS There are two amino acids which contain a sulphur atom. They are both very special but for completely different reasons. Cysteine (Cys; C)Methionine (Met; M)
HYDROPHILLIC AMINO ACIDS These amino acids can be split into a several groups. There are those which are neutral, those which are acidic, and those which are basic. Acidic Amino Acids These amino acids are highly polar, and are nearly always negatively charged at physiological pH. Aspartate (Asp; D) anion. (Compare acetic acid and Glutamate (Glu; E)
Basic Amino Acids These amino acids contain side chains which are postively charged at physiological pH. Lysine (Lys; K) Arginine (Arg; R) Histidine (His; H)
Neutral Polar Amino Acids These amino acids are not charged at physiological pH. However they all have groups on their side-chains which are polar and can form hydrogen bonds. For this reason the amino acids are classed as hydrophillic. Serine (Ser; S)Threonine (Thr; T) Asparagine (Asn; N) Glutamine (Gln; Q)
PEPTIDE • Two or more amino acids covalently linked by an amide bond between the carboxylic acid group of one and the alpha-amino group of the other.
The Peptide Bond They are called peptides because when the carboxyl group of one amino acid joins to the amino group of another, a peptide bond is formed. Chemically this is an amide bond but when it occurs in proteins it is given the name peptide bond. In a polypeptide, there are many peptide bonds. These bonds are rigid and planar, due to electron sharing between the carboxyl carbon and the amide nitrogens which contribute to the bond and give it a partialdouble-bond character. The partial double bond nature of the peptide bond means that there is not free rotation about the C -- N bond. The most stable conformation is planar and trans as shown in the diagram
Formation of the peptide bond: The polymer formed is an unbranched chain of amino acids. Extended TRANS conformation (shown) where each torsion angle along chain is 180o
POLYPEPTIDE • A long peptide chain (typically with MW<10,000). • PEPTIDE BOND • The amide, covalent linkage of peptides. • PROTEIN • A large macromolecule composed of one or more polypeptide chains.
Peptide Nomenclature: eg. Glycyl-alanyl-tyrosyl-glycine Always referred to from N-terminal (amino) to the C-terminal (carboxy).
Short peptides are often given a general name according to how many residues (amino acids) are linked together. • Glycyl-alanyl-tyrosyl-glycine is a "TETRAPEPTIDE" • Alanyl-valyl-tryptophane is a "TRIPEPTIDE" • A general name for a long peptide is oligopeptide or POLYPEPTIDE. • CYCLIC PEPTIDES are formed when an amide (or peptide) bond is formed between the N-terminal and C-terminal residues.
Primary Structure A protein has a completely defined order of amino acids, called its sequence. This defined sequence is called the primary structure (1o) of the protein. The sequence, or primary structure is specified by the sequence of the piece of DNA containing a gene for that protein, and the sequence is unique to the individual protein. All the information necessary to make a protein is contained in the primary structure. However primary structure is only the first level of structural complexity of proteins. The primary structure of a protein (amino acid sequence) contains all the information needed to make the protein into a complicated 3 dimensional shape. This shape is essential to the function of the protein.
Secondary structures Peptide chains do not remain stretched out in the cell. They tend to fold into regular repetetive structures if they can. In these, the C=O and the N-H groups of the peptide bonds are Hydrogen Bonded to each other. These regular forms of protein structure are called secondary (2o) structures. Secondary Structure is the local structure which is typically recognized by specific backbone Torsion Angles and specific main chain Hydrogen Bond pairings. Since bond length and angles are fairly invariant in the known protein structures, the key to protein folding lies in the torsion angles of the backbone. A torsion angles is defined by 4 atoms, A, B, C and D.
When atoms A, B, C and D are main chain atoms : the carboxylic carbon, C1 the alpha carbon, C2 or C-alpha the amide group nitrogen, N There are THREE repeating torsion angles along the backbone chain called phi, psi and omega.
The OMEGA angle (the peptid bond) tends to be planar (0 or 180o) due to delocalization of the carbonyl electrons & the nitrogen lone pair. • Trans is generally favored over cis: • Only 116 (0.36%) of 32,539 angles in 154 X-ray structures were found to be cis (Stewart et al. 1990). • However...... some specific bonds are often cis, eg. • Tyr-Pro (25%), Ser-Pro (11%), X-Pro (6.5%) • This leaves phi and psi for flexible folding of the chain. However, steric conflicts limit even these angles as well.
The hydrogen bond is a key concept in describing the selectivity and stability of protein and nucleic acid structures. It involves three atoms, a donor electronegative atom, D, to which the hydrogen is bound (ie. N, O, or S in proteins) and an acceptor electronegative atom, A, in close proximity. In proteins and nucleic acids the predominant regular structures are also characterized by repeating hydrogenbond opportunities. With protein secondary structure, regularly spaced intrachain hydrogen bonding is seen.
a-Helices The a-helix is a rod like structure. It is one peptide chain which has coiled so that adjacent residues are 1.5A apart. There are H-bonds between the N-H and the C=O groups of the backbone. These link the peptide bonds between everyfourth amino acid. list of the features of the a-helix Right Handed a-helix (coils clockwise)3.6 residues per turnAll C=O and N-H groups are H-bondedH-bonds form between -N-H and C=O of every fourth amino acid in the chainSidechains point outward1.5A between adjacent residues
b-Sheets A polypeptide in a b-sheet is called a b-strand, and is almost fully extended (not coiled) so there is 3.5A between adjacent residues. The b-sheet is stabilised by H-bonds between the N-H and the C=O groups of different peptides or different parts of the same peptide. The b-strands in a sheet can either run in the same (parallel) or different (anti-parallel) direction.
Turns involving four (4) residues are more common with hydrogen bonding from the carbonyl of residue 1 to the N-H of residue 4. One class of these turns is called beta-turns, typically found at turns of beta-sheet structure and designated by Roman numerals.
Tertiary Structure The folding of the total chain, the combination of the elements of secondary structure linked by turns and loops. Its stability is determined by non-bonding interactions & the disulfide bond. The interactions in proteins that maintain structure cover the spectrum of chemical interactions from the covalent bonds of the amide backbone and the disulfide bridge through very polar charge-charge interactions to a variety of weaker, short distance interactions.
Hydrophobic Interactions Non-Polar/Hydrophobic/Aliphatic sidechainscannot hydrogen bond with water, hence the network of water is disrupted by them. This is avoided if the non-polar sidechains are removed or shielded from the water and buried in the interior of the protein. Hydrophobic interaction are a major drivingforce in protein folding. Hydrophobic interactions are also important in the formation of secondary structure elements such as a-helices and b-sheets. The peptide backbone is relatively hydrophillic because of the C=O and N-H groups of each peptide bond. However in the centre of the protein these tend to be in a hydrophobic environment. One way to reduce the hydrophilicity of the peptide backbone is to for hydrogen bonds between the peptide atoms. The a-helix and b-sheet are two structures which maximise the hydrogen bonding between the peptide bonds of the backbone and reduce its hydrophilicity.
Hydrogen Bonds When unfolded, all polar/hydrophillic sidechains can interact via H-bonds with water. When the protein folds, they must H-bond to each other and exclude much of the water. All groups capable of forming a hydrogen bond MUST, hence H-bonding in the backbone (C=O to N-H) by way of helices and sheets is an efficient way of ensuring maximum H-bonding. Sidechains can either accept (as in C=O) or donate (as in N-H, or O-H) an H-bond. The capacity of proteins to form hydrogen bonds is an important determinant of protein stability. Hydrogen bonds can be between backbone groups, as in helices and sheets; between side chains, such as serine or threonine O-H groups and carbonyl carbons of side chains (-C=O); and between backbone groups and side chain groups.
Ion Pairs When amino acid sidechains of opposite carge are in close proximity, they can form an ion pair (also called a salt bridge). But they are also capable of hydrogen bonding and hence, are usually found on the surface of the protein. If they can form a salt bridge, they will usually be buried. Salt bridges also increase the stability of the tertiary structure.
Hydrophobic interactions, hydrogen bonds and salt bridges are all non-covalent interactions • These are all relatively weak interactions but the large number in a protein combine to give the overall stability of the structure
Disulphide Bonds If two cysteine sidechains are close to one another and the local environment is conducive to oxidation,then they can form a disulphide bond/bridge. The residues can either be in the same peptide chain (forming a loop) or in different chains. As Disulphide bonds are covalent linkages they add considerably to the stability of proteins in which they occur. Note that disuphide bridges only form after the protein has folded into its tertiary structure. This folding is driven by the combined energy of all of the weak interactions described in the previous section above.
The tertiary structure of proteins is characterized by tightly folded structure with polar groups on the surface and non- polar groups buried. • Natural variation from species-to-species tends to favor changes in surface (and therefore polar) groups. • Structure is determined globally and redundantly. Up to 30% of the amino acids in some proteins have been changed to alanine with little change in the folded structure.
At the simplest level, proteins can be classified by their content of secondary structure (PDB). Typically, the focus is on alpha-helicies and beta- sheets. However, there are some proteins where turns and disulfide bonds seem to be more important considerations.
Consider wheat germ agglutinin, where 16 turns (in cyan) and 16 disulfide bonds (in brown) are the predominant structural contributions. While a large part of the structure has no classified secondary structure (in black), there are still four structurally homologous domains related by symmetry.
Some proteins are made up of mostly alpha helicies: • Both marine bloodworm hemoglobin (left) and E. coli cytochrome B562 (right) are composed of mostly alpha helicies. The 4 helix bundle of the cytochrome is a common motif.
Some are mostly beta sheet: • The green alga plastocyanin (left) and sea snake neurotoxin (right) are mostly beta sheets.
Of course, many proteins are a mix of alpha helicies and beta sheets. • Two simple proteins with a mix of 2o components: ribonuclease T1 (left) and pancreatic trypsin inhibitor (right).
The beta sheet core of carbonic anhydrase (left) and H-RAS P-21 protein (right) is often referred to as a beta saddle and it is found in many structures.
The beta barrel found in the triose phosphate isomerase (left) and xylose isomerase (right) structures is another very common motif.
Proteins containing more than one polypeptide chain exhibit an additional level of structural organisation. In this case, each polypeptide chain is a "subunit". Quaternary (4o) structure describes the way the are arranged together and the nature of their contacts. Subunits associate by non-covalent interactions similar to those involved in tertiary structure but are distinquished only by being interchain rather than intrachain. Some proteins are composed of identical subunits (chains). A simple example is the homodimer of HIV Protease. Some proteins are composed of non-identical subunits (chains). A simple example is insulin which is made up of two chains-heterodimer, the alpha chain and the beta chain, linked by two disulfide bridges.
Even with identical subunits, their relative positioningcontrols the symmetry of the complex and can have biochemical implications. Consider two right hands, nearly identical to each other but completely assymetric. They can be put together to form a "dimer" in many different ways With more subunits in the complex, we can imagine some emergent properties that can have biochemical implications. For example, with three identical subunits arranged linearly, the middle subunit experiences a very different environment from the other two. The possibilities grow with the number of subunits.
The four subunit arrangement of rabbit muscle glycogen phosphorylase is nearly planar (actually, the top two subunits are arranged at a slight angle to the bottom two). • Each pair of subunits is a functional unit in this case.
The four subunit arrangement of D-Xylose Isomerase is a more complex, interwoven arrangement.
Bovine hemoglobin is composed of two pairs of non-identical subunits, alpha and beta. Each alpha-beta pair is more closely associated than they are with each other, but the overall arrangement is roughly tetrahedral.