Download

1 / 11
110 likes | 121 Views
This IRAM network interface design overview highlights the goals, application characteristics, requirements, and design decisions for the VIRAM-1 prototype board. It includes information on packet descriptors, the DMA engine, queue manager, and more.

E N D
IRAM Network Interface Ioannis Mavroidis maurog@cs.berkeley.edu IRAM retreat January 12-14, 2000
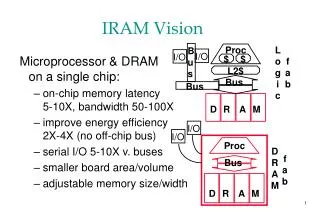
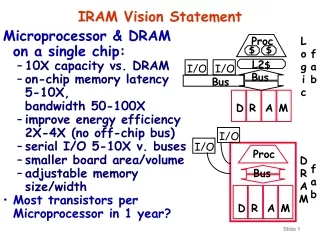
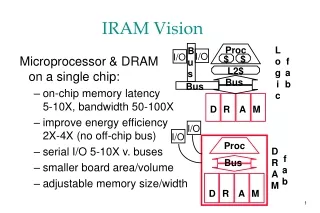
Outline • IRAM Network Interface Goals • VIRAM-1 prototype board and Application characteristics • NI Requirements and Design decisions • NI Architecture and Design Overview • Rough diagram of the whole datapath • What has been implemented so far: • Packet descriptor • DMA engine • Queue Manager
Application Characteristics • Streaming Multimedia/DSP computations or problems too large or too slow on a single IRAM : • FFT, MPEG, Sorting, Sparse matrix computations, N-body computations, Speech kernels, Rasterization or other graphics • Bulk synchronous communication, mostly messages 100s of bytes long. • High bandwidth is more important than low latency. • Programming model and OS support similar to : • MPI (message send/receive) • Titanium (remote read/write)
NI Requirements • Message Passing support • User-Level Access (mem-mapped device) • Flow Control (no packets dropped) • Routing/Bridging • Multiple DMA descriptors per packet • Should not under-utilize available link bandwidth • Keep it simple. Focus on prototype board and apps. • ~8 chips on same board • Applications: High bandwidth, Latency tolerant
NI Design Decisions • Packet is segmented into 32-byte flits • Route once per packet • Advantage: Routing each flit separately would: • Need more buffer space at the receiving node. • Consume more bandwidth for routing info overhead. • Disadvantage: implies that flits from different packets should not be interleaved. Better not have page-fault/MEM exception in the middle of a packet… • SW will have to guarantee this OR • For our prototype, apps are highly likely to fit in main MEM • Credit-based flow-control per flit • Do not have to allocate buffer for whole packet. • Error detection/correction codes per flit • Helps to reduce power consumption with low-swing interconnect
Packet Descriptor • Msg send is a 2 phase process: describe and launch • 64 memory-mapped registersfor packets description. • 16 max per packet. • Launch is atomic. • Description of one msg can start immediately after previous is launched. • Misc registers: • head, tail (circular buffer) • space_avail (max pct descriptor) • save_len (for context-switch) • error (illegal op_len/desc_len)
DMA engine • Supported operations • Sequential DMA (word aligned) • Strided DMA (words/doubles) • Address generator: • Allocates buffer to receive data when it arrives from memory. • Generates addresses. • Remembers pending requests. • Data receiver: • Communicates with memory through a 32-bit bus. • Generates mux_sel signal to read mem data, according to pending requests.
Queue Manager (1) • Manages multiple FIFO queues in one shared memory. • 5 queues: • 1 x 4 output links • 1 free list with all empty flits • Each queue is represented as a linked list with head/tail/next pointers • Supported operations: • enqueue (list, data) • data = dequeue (list)
Queue Manager (2) • 2 cycles per operations • Head/Tail Read • MEM, WB Head/Tail • Pipelining: 1 op/cycle • Problem: Complexity due to data hazards. • Solution: Do not allow 2 consecutive ops of the same kind to avoid most hazards. • Timing • Enqueue: Write 64 bits • Dequeue: Read 64 bits -> Port 0 • Enqueue: Write 64 bits • Dequeue: Read 64 bits -> Port 1 • Enqueue: Write 64 bits • Dequeue: Read 64 bits -> Port 2 • Enqueue: Write 64 bits • Dequeue: Read 64 bits -> Port 3