Download

1 / 66
680 likes | 868 Views
Hardware platforms for Embedded computing. poor design techniques. The energy/flexibility conflict - Intrinsic Power Efficiency -. Operations/Watt [MOPS/mW]. Ambient Intelligence. 10. DSP-ASIPs. hardwired muxed ASIC. 1. Processors. Reconfigurable Computing. µPs. 0.1. 0.01. Technology.

E N D
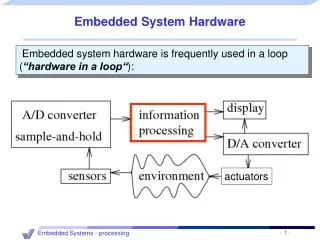
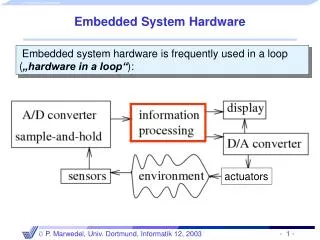
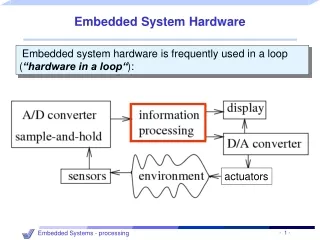
poor design techniques The energy/flexibility conflict- Intrinsic Power Efficiency - Operations/Watt[MOPS/mW] Ambient Intelligence 10 DSP-ASIPs hardwired muxed ASIC 1 Processors Reconfigurable Computing µPs 0.1 0.01 Technology 1.0µ 0.5µ 0.25µ 0.13µ 0.07µ Necessary to optimize HW/SW; otherwise the prize for software flexibility cannot be paid! [H. de Man, Keynote, DATE‘02;T. Claasen, ISSCC99]
Architectural Choices Flexibility 1/Efficiency (power, speed)
The Processor Design Space Application specific architectures for performance Embedded processors Microprocessors Performance is everything & Software rules Performance Microcontrollers Cost is everything Cost
Area of processor cores = Cost Nintendo processor Cellular phones
Another figure of meritComputation per unit area Nintendo processor ??? Cellular phones
Embedded vs. general-purpose processors • Embedded processors may be optimized for a category of applications. • Customization may be narrow or broad. • We may judge embedded processors using different metrics: • Code size. • Memory system performance. • Preditability.
Microcontrollers Memory ROM RAM CPU I/O Subsystems: Timers, Counters, Analog Interfaces, I/O interfaces A single chip
Microcontroller Architectures Memory 0 Program + Data Address Bus Von Neumann Architecture CPU Data Bus 2n Memory 0 Program Address Bus Harvard Architecture Fetch Bus CPU Address Bus 0 Data Data Bus
MCS-51 “Family” of Microcontollers • 8051 introduced by Intel in late 1970s • Now produced by many companies in many variations • The most pupular microcontroller – about 40% of market share • 8-bit microcontroller
“Original” 8051 Microcontroller 4096 Bytes Program Memory 128 Bytes Data Memory Two 16 Bit Timer/Event Counters Oscillator and timing Internal data bus 8051 CPU Programmable I/O Programmable Serial Port Full Duplex UART Synchronous Shifter 64 K Byte Bus Expansion Control subsystem interrupts External interrupts Parallel ports Address Data Bus I/O pins Control Serial Output Serial Input
Features for Embedded Systems Microcontrollers- MHS 80C51 as an example - • 8-bit CPU optimised for control applications • Extensive Boolean processing capabilities • 64 k Program Memory address space • 64 k Data Memory address space • 4 k bytes of on chip Program Memory • 128 bytes of on chip data RAM • 32 bi-directional and individually addressable I/O lines • Two 16-bit timers/counters • Full duplex UART • 6 sources/5-vector interrupt structure with 2 priority levels • On chip clock oscillators • Very popular CPU with many different variations
RISC processors • RISC generally means highly-pipelinable, one instruction per cycle. • Pipelines of embedded RISC processors have grown over time: • ARM7 has 3-stage pipeline. • ARM9 has 5-stage pipeline. • ARM11 has eight-stage pipeline. ARM11 pipeline [ARM05].
RISC processor families • ARM: ARM7 is relatively simple, no memory management; ARM11 has memory management, other features. • MIPS: MIPS32 4K has 5-stage pipeline; 4KE family has DSP extension; 4KS is designed for security. • PowerPC: 400 series includes several embedded processors; MPD7410 is two-issue machine; 970FX has 16-stage pipeline.
Audio applications MPEG Audio Portable audio Digital cameras Wireless Cellular telephones Base station Networking Cable modems ADSL VDSL DSP Applications
Another Look at DSP Applications Increasing Cost • High-end • Wireless Base Station - TMS320C6000 • Cable modem • gateways • Mid-end • Cellular phone - TMS320C540 • Fax/ voice server • Low end • Storage products - TMS320C27 • Digital camera - TMS320C5000 • Portable phones • Wireless headsets • Consumer audio • Automobiles, toasters, thermostats, ... Increasing volume
DSP vs. General Purpose MPU • The “MIPS/MFLOPS” of DSPs is speed of Multiply-Accumulate (MAC). • DSP are judged by whether they can keep the multipliers busy 100% of the time. • The "SPEC" of DSPs is 4 algorithms: • Inifinite Impule Response (IIR) filters • Finite Impule Response (FIR) filters • FFT, and • convolvers • In DSPs, algorithms are king! • Binary compatability not an issue • Software is not (yet) king in DSPs. • People still write in assembly language for a product to minimize the die area for ROM in the DSP chip.
Architectural Features of DSPs • Data path configured for DSP • Fixed-point arithmetic • MAC- Multiply-accumulate • Multiple memory banks and buses - • Harvard Architecture • Multiple data memories • Specialized addressing modes • Bit-reversed addressing • Circular buffers • Specialized instruction set and execution control • Zero-overhead loops • Support for MAC • Specialized peripherals for DSP • THE ULTIMATE IN BENCHMARK DRIVEN ARCHITECTURE DESIGN!!!
D P a x x[j-i] a[i] AX AY MY MX Address- registersA0, A1, A2 ..i+1, j-i+1 MF AF +,-,.. * x[j-i]*a[i] +,- Address generation unit (AGU) AR yi-1[j] MR Domain-oriented architectures n-1 Application: y[j] = i=0 x[j-i]*a[i] i: 0i n-1: yi[j] = yi-1[j] + x[j-i]*a[i] Architecture: Example: Data path ADSP210x - Parallelism - Dedicated registers MR:=0; A1:=1; A2:=n-2; MX:=x[n-1]; MY:=a[0];for ( j:=1 to n) {MR:=MR+MX*MY; MY:=a[A1]; MX:=x[A2]; A1++; A2--}
DSP - Features (1) • Multiply/accumulate(MAC)and zero-overhead loop (ZOL) instructions (as shown) • Heterogeneous registers (as shown) • Separate address generation units (AGUs)(as in ADSP 210x)
DSP - Features (2) sliding window • Modulo addressing:Am++ Am:=(Am+1) mod n(implements ring or circular buffer in memory) x t2 t1 t ..x[n-2]x[n-1]x[0]x[1].. ..x[n-3]x[n-2]x[n-1]x[n]x[1] Memory, t=t1 Memory, t2=t1+1
D P AX AY MY MX Address- registersA0, A1, A2 .. MF AF +,-,.. * +,- Address generation unit (AGU) AR MR Multiple memory banks or memories Simplifies parallel fetches
Very long instruction word (VLIW) processors Key idea: detection of possible parallelism to be done by compiler, not by hardware at run-time (inefficient). VLIW: parallel operations (instructions) encoded in one long word (instruction packet), each instruction controlling one functional unit. E.g.:
Cycle Instruction 1 A 2 B C D 3 E F G The Texas InstrumentsTMS 320C6xx as an example Bit in each instruction encodes end of parallel execution 31 0 31 0 31 0 31 0 31 0 31 0 31 0 0 1 1 0 1 1 0 Instr. A Instr. B Instr. C Instr. D Instr. E Instr. F Instr. G Instructions B, C and D use disjoint functional units, cross paths and other data path resources. The same is also true for E, F and G. Parallel execution cannot span several packets.
Partitioned register files • Many memory ports are required to supply enough operands per cycle. • Memories with many ports are expensive. Registers are partitioned into (typically 2) sets, e.g. for TI C60x: Data path A Data path B register file A register file B L1 S1 M1 D1 D2 M2 S2 L2 Address bus Data bus
Instruction types are mapped tofunctional unit types • There are 4 functional unit (FU) types: • M: Memory Unit • I: Integer Unit • F: Floating-Point Unit • B: Branch Unit • Instruction types corresponding FU type,except type A (mapping to either I or M-functional units).
Large # of delay slots,a problem of VLIW processors add sub and orsub mult xor divld st mv beq The execution of many instructions has been started before it is realized that a branch was required. Nullifying those instructions would waste compute power Executing those instructions is declared a feature, not a bug. How to fill all „delay slots“ with useful instructions? Avoid branches wherever possible.
Predicated execution:Implementing IF-statements „branch-free“ Conditional Instruction „[c] I“ consists of: • condition c • instruction I c = true => I executed c = false => NOP
Predicated execution:Implementing IF-statements „branch-free“: TI C6x Conditional branch [c] B L1 NOP 5 B L2 NOP 4 SUB x,y,a || SUB x,z,b L1: ADD x,y,a || ADD x,z,b L2: Predicated execution [c] ADD x,y,a || [c] ADD x,z,b || [!c] SUB x,y,a || [!c] SUB x,z,b if (c) { a = x + y; b = x + z; } else { a = x - y; b = x - z; } max. 12 cycles 1 cycle
I/O P E R I P H E R A L S I/0 PE PE PE I/0 SRAM SRAM PE CPU 3D stacked main memory DRAM PE Local Memory hierarchy i/o I/O Architecture Evolution • Roadmap continues: 906545 nm • “Traditional” Bus-based SoCs fit in one tile !! • Communication demand is staggering, but unevenly distributed, because of architectural heterogeneity
Picochip PC102 Ambric AM2045 Cisco CSR-1 Intel Tflops Raza XLR Cavium Octeon Raw Cell Niagara Opteron 4P Boardcom 1480 Xeon MP Xbox360 PA-8800 Tanglewood Opteron Power4 PExtreme Power6 Yonah Multicores Are Here! [Amarasinghe06] 512 256 128 64 # of cores 32 16 8 4 2 4004 8080 8086 286 386 486 Pentium P2 P3 Itanium 1 P4 8008 Athlon Itanium 2 1970 1975 1980 1985 1990 1995 2000 2005 20??
MPSoC – 2005 ITRS roadmap [Martin06]
Technology, Circuits, and Architecture to constrain the power Power is the Challenge! ) 1400 2 SiO2 Lkg 10 mm Die 1200 SD Lkg Active 1000 800 Power (W), Power Density (W/cm 600 400 200 0 90nm 65nm 45nm 32nm 22nm 16nm
Near Term Solutions • Move away from Frequency alone to deliver performance • More on-die memory • Multi-everywhere • Multi-threading • Chip level multi-processing • Throughput oriented designs • Performance by higher level of integration
Multi-threading C1 C2 Large Core Cache Single Thread C3 C4 Improved performance, no impact on thermals & power delivery Full HW Utilization Wait for Mem ST Multi-Threading Chip Multi-processing Wait for Mem MT1 Wait MT2 MT3 mArchitecture Techniques Increase on-die Memory
Cache Large Core Small Core C1 C2 Cache C3 C4 Multi-Core Power Power = 1/4 4 Performance Performance = 1/2 3 2 2 1 1 1 1 4 4 Multi-Core: Power efficient Better power and thermal management 3 3 2 2 1 1
Embedded Applications Asymmetric Multi-Processing Differentiated Processors Specific tasks known early Mapped to dedicated processors Configurable and extensible processors: performance, power efficiency Communication Coherent memory Shared local memories HW FIFOS, other direct connections Dataflow programming models Classical example – Smart mobile – RISC + DSP + Media processors Server Applications Symmetric Multi-Processing Homogeneous cores General tasks known late Tasks run on any core High-performance, high-speed microprocessors Communication large coherent memory space on multi-core die or bus SMT programming models (Simultaneous Multi-Threading) Examples: large server chips (eg Sun Niagara 8x4 threads), scientific multi-processors Embedded vs. General Purpose
Example system platforms • Generic • Automotive • Wireless • Multimedia
PC-based platform • Basic hardware components: • CPU; • memory; • timers; • DMA; • minimal I/O devices. • Basic software: • BIOS.
PC-style hardware architecture CPU memory I/O system bus bridge high-speed bus DMA controller timers low-speed bus bus interface I/O
Strong ARM • StrongARM system includes: • CPU chip (3.686 MHz clock) • system control module (32.768 kHz clock). • Real-time clock; • operating system timer • general-purpose I/O; • interrupt controller; • power manager controller; • reset controller.
Pros and cons • Plentiful hardware options. • Simple programming semantics. • Good software development environments. • Performance-limited.
TI Open Wireless Multimedia Applications Platform • Dual-processor shared memory system: external memory General-purpose processor DSP Mem ctrl DSP task & I/O ctrl GPP OS DSP manager DSP OS bridge http://www.ti.com/sc/docs/apps/wireless/omap/overview.htm
ARM9 core 16KB I-cache 8KB D-cache 2-way set associative 150 MHz C55x DSP core 16KB I-cache 8KB RAM set 2-way set associative 200 MHz TI OMAP™ Hardware platform Program Memory SDRAM Memory & Traffic Controller I-MMU D-MMU MMU Internal RAM/ROM I-Cache D-Cache I-Cache DMA RISC Core DSP Core + Appl Coprocessors Peripherals LCD Controller, Interrupt Handlers, Timers, GPIO, UARTs, ...
OMAPI Standard (ST/TI) • Goal: standardize the interfaces between application processor and peripheral devices in a mobile product • Provide standard services (APIs) in the OS that can be used by application developers
STMicro Nomadik platform Main Core I/Os HW Accelerators Memory System
Nomadik SW platform Compliant with OMAPI standard
Philips Digital Video Nexperia Platform MIPS™ TriMedia™ SDRAM General-purpose Scalable RISC Processor • 50 to 300+ MHz • 32-bit or 64-bit Library of DeviceIP Blocks • Image coprocessors • DSPs • UART • 1394 • USB …and more Scalable VLIW Media Processor: • 100 to 300+ MHz • 32-bit or 64-bit Nexperia™ System Buses • 32-128 bit MMI MIPS CPU TriMedia CPU D$ PRxxxx TM-xxxx D$ I$ I$ DEVICE IP BLOCK DEVICE IP BLOCK DEVICE IP BLOCK DEVICE IP BLOCK . . . . . . DVP MEMORY BUS PI BUS PI BUS DEVICE IP BLOCK DEVICE IP BLOCK DVP SYSTEM SILICON
Nexperia™ -DVP Software Architecture Supports multiple OSs and middleware software Abstracts platform functionality via consistent APIs Nexperia™-DVP Streaming Software Encapsulates implementation of streaming media components (hardware and software) Nexperia™ Platform Software OS independent device drivers for on-chip and off-chip devices Nexperia-DVP Software Applications MiddlewareJavaTV, TVPAK, OpenTV, MHP/Java, proprietary ... Kernel: pSOS, Win-CE, JavaOS Streaming and Platform Software Nexperia Hardware